nebula 压测环境安装
准备工作
- nebula集群 5台
- 测试机一台
- 网络要互通
集群配置
CPU: 16core
Memory : 122G
Disk 900G * 2
压测机配置同上 1台
压测机极限可mock 65500 并发
测试k6的安装
wget https://github.com/vesoft-inc/k6-plugin/releases/download/v0.0.8/k6-linux-amd64
mv k6-linux-amd64 k6
chmod 755 k6
准备csv
https://github.com/vesoft-inc/k6-plugin/blob/master/example/person.csv
代码
import nebulaPool from 'k6/x/nebulagraph';
import { check } from 'k6';
import { Trend } from 'k6/metrics';
import { sleep } from 'k6';
var lantencyTrend = new Trend('latency');
var responseTrend = new Trend('responseTime');
// initial nebula connect pool
// by default the channel buffer size is 20000, you can reset it with
// var pool = nebulaPool.initWithSize("192.168.8.152:9669", {poolSize}, {bufferSize}); e.g.
// var pool = nebulaPool.initWithSize("192.168.8.152:9669", 1000, 4000)
var pool = nebulaPool.init("192.168.8.152:9669", 400);
// initial session for every vu
var session = pool.getSession("root", "nebula")
session.execute("USE sf1")
export function setup() {
// config csv file
pool.configCSV("person.csv", "|", false)
// config output file, save every query information
pool.configOutput("output.csv")
sleep(1)
}
export default function (data) {
// get csv data from csv file
let d = session.getData()
// d[0] means the first column data in the csv file
let ngql = 'go 2 steps from ' + d[0] + ' over KNOWS '
let response = session.execute(ngql)
check(response, {
"IsSucceed": (r) => r.isSucceed() === true
});
// add trend
lantencyTrend.add(response.getLatency());
responseTrend.add(response.getResponseTime());
};
export function teardown() {
pool.close()
}
run
./k6 run nebula-test.js -u 65500 -d 1000s
结果
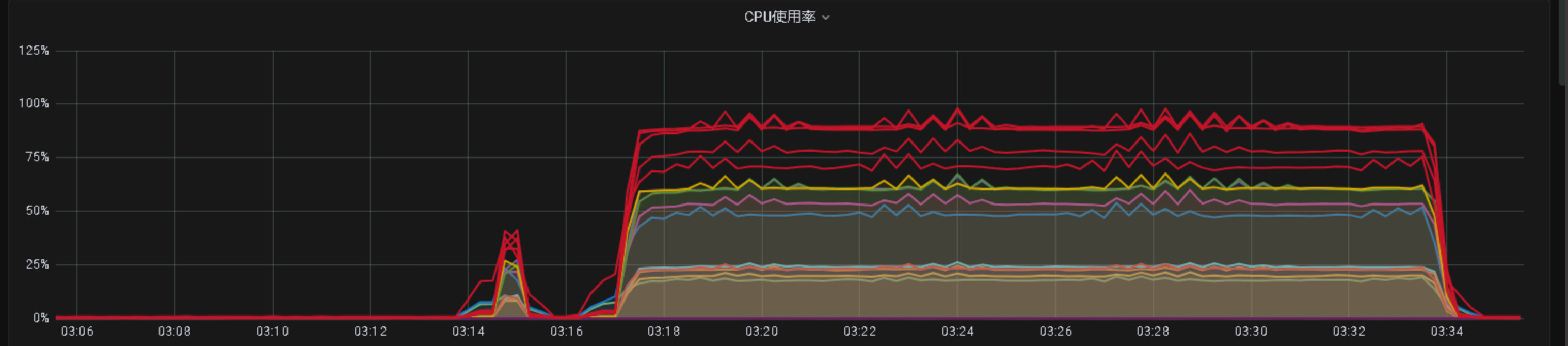
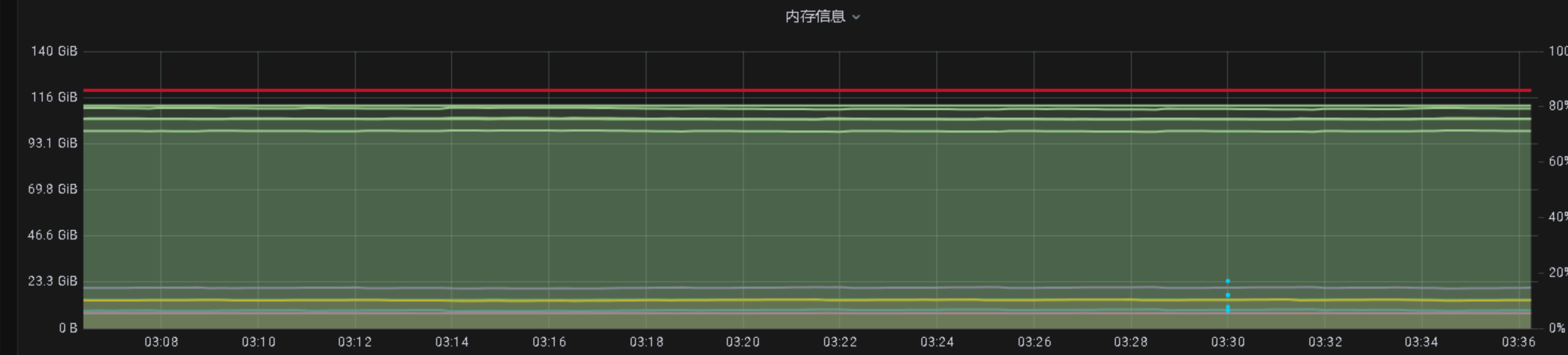
结论
在保证 100%check的前提下,内存有足够的富裕,但是 cpu已经接近极限 80% 以上。
 Bruce 你不展开讲讲机器、网络啥配置吗
Bruce 你不展开讲讲机器、网络啥配置吗