在上次的 nebula-storage on nLive 直播中,来自 Nebula 存储团队的负责人王玉珏(四王)同大家分享了 nebula storage 这块的设计思考,也解答了一些来自社区小伙伴的提问。本文整理自该场直播,按照问题涉及的分类进行顺序调整,并非完全按照直播的时间先后排序。
Nebula 的存储架构
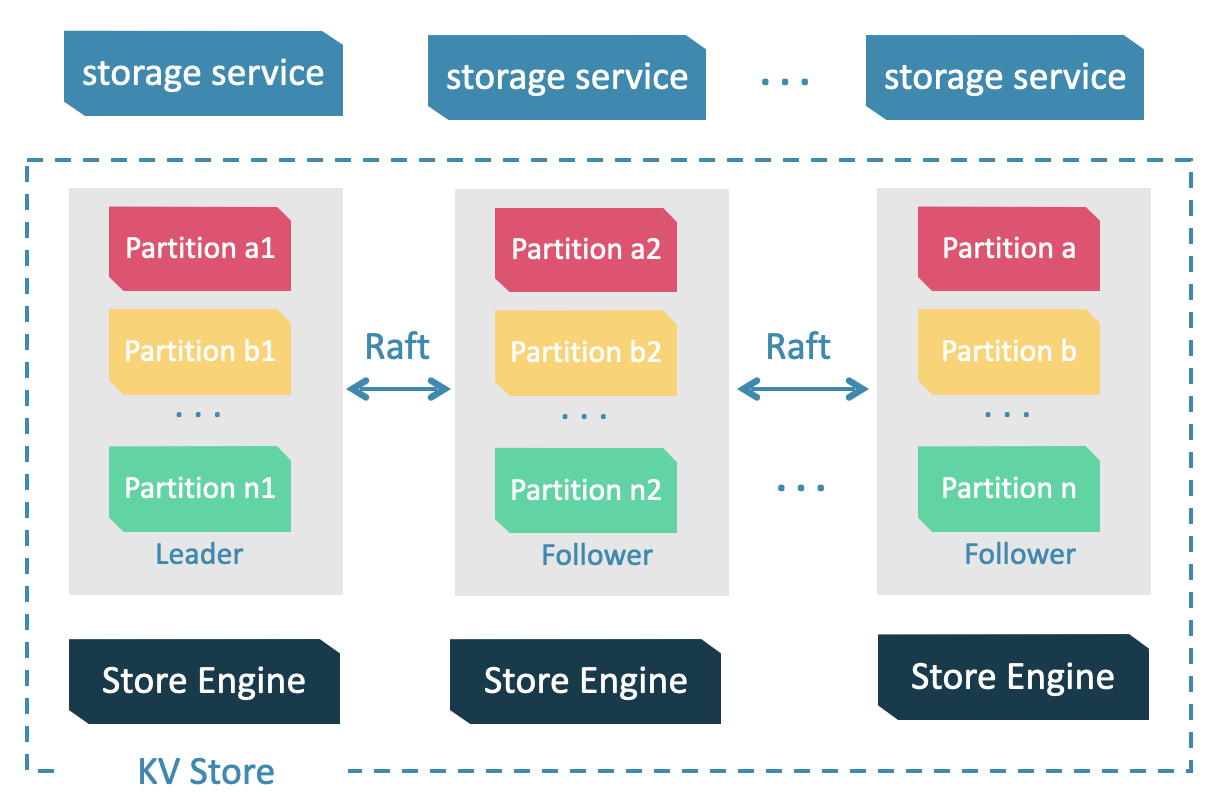
整个 Storage 主要分三层,最下面是 Store Engine,也 就是 RocksDB,中间是 raft 一致性协议层,最上层 storage service 提供对外的 rpc 接口,比如取点属性,或者边属性,或者是去从某个点去找它的邻居之类的接口。当我们通过语句CREATE SPACE IF NOT EXISTS my_space_2 (partition_num=15, replica_factor=1, vid_type=FIXED_STRING(30)); 创建 space 时,根据填写的参数将 space 划分为多个逻辑单元成为 partition,各个 partition 会落到不同机器上,同一个 Partition 的多个副本会组成一个逻辑单元,并通过 raft 共识算法 raft 保证一致。
Nebula 的存储数据格式


这里着重讲述为何 v2.x 会有这些数据格式的改动:在 v1.x 版本中,Nebula VID 主要是 int 类型,所以大家可以看到上图 v1.x 中不管是点还是边,它的 VID 是定长的、占 8 个字节。2.x 版本开始,为了支持 string 类型 VID,VertexID 就变成不定长的 n 个字节。所以大家创建 Space 的时候需要指定 VID 的长度,这个是最主要的改动,其他的话还有一些小的改动,去掉了时间戳。整体来说,目前的存储格式更贴近图的使用场景——从某个点开始找它的邻居,以 v2.x 这样 VertexID + EdgeType 存储格式来保存边的话,可以迅速地找到某个点出边。
同时,v2.x 也做了 key(Nebula 底层是 KV 存储的)编码格式上的改变,简单来说就是把点和边分开。这样的话,取某一个点所有 tag 时通过一次 prefix 就可以直接扫到,避免了像 v1.x 那样扫描点的过程中夹杂多个边的问题。
底层的数据存储
针对用户提出的“Nebula 底层如何存储数据”的问题,四王了进行了回复:Nebula 的存储层使用 KV 进行存储点边数据。对于一个点而言,key 里面存储 VID 和它的 tag 类型。点的 value 中,会根据 这个 tag 的 schema,将 schema 中的各个属性进行编码并存在 value 中。比如,player 这个 tag 可能会有一个 age 这样一个整型年龄字段,使用存储的时候会把 age 字段的值,按某种编码保存在 value 中。再来说下边,边的存储 key 会多几个字段,主要是边的起点 ID、边类型、ranking 及终点类型,通过这四元组确定唯一的边。边的 value 和点的 value 类似,根据边的 Schema 字段定义,将各个字段进行编码存储。这里要说一下,Nebula 中存储边是存储两份:Nebula 中的边是有向边,存储层会存储正向边和反向边,这样的好处在于使用 GO FROM 进行遍历查找那些点指向点 A 或者点 A 指向哪些点可以快速通过双向查找实现。
一般来说,图存储分为切边和切点两种方式,像上面说的 Nebula 其实采用了切边方式:一条边存储两份 KV。
用户提问:为什么采用切边方式,切点和切边各自有啥利弊?
切边的话,每一份边存两份,数据总量会比切点大很多,因为图数据边的数量是远大于点的数量,造成边的大量冗余,相对好处是对起点和它的边进行映射时会映射到同一个 partition 上,这样进行一些从单个点触发的 query 时会很快速得到结果。切点的话,由于点可能被分在多个机器上,更新数据时得考虑数据的一致性问题,一般在图计算里面切点的使用会更广泛。
你问我答
下面内容收集于之前活动预告的 AMA 环节,以及直播时弹幕中提出的问题。
问题目录
- 边的 value 存储边属性吗?
- 强 Schema 的设计原因
- 存一份边的设计
- 图空间如何做物理隔离
- Meta 如何存储 Schema
- 存储未来规划
- VID 遍历点和边的原理
- 数据预校验
- Nebula 监测
- Nebula 的事务
- 数据膨胀问题
- 磁盘容量本身不均怎么处理
- Nebula 的 RocksDB “魔改”
边的 value 存储边属性吗?
和上面底层存储里讲的那样,创建 Edge 的 schema 时候会指定边类型上的属性,这些属性会作为底层 RocksDB key 的 value 存储起来,这个 value 的占位是定长的,和下面这个问题类似:
强 Schema 的设计原因
强 schema 是因为技术原因还是产品原因? 因为考虑到 string 类型是变长的,每行长度本身就不固定,感觉跟无 schema 无区别。 如果非定长,那查询时怎么知道该查询到哪里呢? 是有标志位么?
其实本质上原因是用强 Schema 的好处是快,先说下常见的简单数据类型,比如:int 和 double,这样的数据类型长度是固定的,我们会直接在 value 相应的位置进行编码。再说下 string 类型,在 Nebula 中有两种 string :一种是定长 string,长度是固定,和前面的简单数据类型一样,在 value 的固定位置进行编码。另外一种是变长的 string,通常来说大家都会比较倾向于变长 string(灵活),非定长 string 会以指针形式存储。
举个例子,schema 中有个属性是变长 string 类型,我们不会和简单数据类型一样直接编码保存,而是在相应位置保存一个 offset 指针,实际指向 value 中的第 100 个字节,然后在 100 这个位置才保存这个变长 string。所以读取变长 string 的时候,我们需要在 value 中读两次,第一次获取 offset,第二次才能真正把 string 读出来。通过这样的形式,把所有类型的属性都转化成"定长",这样设计的好处是,根据要读取的属性和它前面所有字段的占用字节大小,可以直接计算出要读取的字段在 value 中存储的位置,并把它读出来。读取过程中,不需要读取无关的字段,避免了弱 schema 需要对整个 value 进行解码的问题。
像 Neo4j 这种图数据库,一般是 No Schema,这样写入的时候会比较灵活,但序列化和反序列化时都会消耗一些 CPU,并且读取的时候需要重新解码。
追问:如果有变长 string,会不会导致每行数据长度不一样
可能 value 长度会不一样,因为本身是变长嘛。
追问:如果每行长度不一样,为什么要强 schema?
Nebula 底层存储用的 RocksDB,以 block 的形式组织,每个 block 可能是 4K 大小,读取的时候也是按 block 大小进行读取,而每个 block 中的各个 value 长度可能是不一样的。强 schema 的好处在于读单条数据的时候会快。
存一份边的设计
Nebula 存边是存储了两份,可以只存储一份边吗?存一份边反向查询是否存在问题?
其实这是一个比较好的问题,其实在 Nebula 最早期设计中是只存一份边的属性,这适用于部分业务场景。举个例子,你不需要任何的反向遍历,这种情况下是完全不需要存反向边。目前来说,存反向边最大的意义是方便于我们做反向查询。其实在 Nebula 比较早的版本中,准确说它是只存了反向边的 key,边类型的属性值是没有存,属性值只存在正向边上。它可能带来一些问题,双向遍历或者反向查询时,整个代码逻辑包括处理流程都会比较复杂。
如果只存一份边,反向查询的确存在问题。
图空间如何做物理隔离
大家在用 Nebula 时,首先会建图空间 CREATE SPACE,在建图空间时,系统会分配一个唯一图空间 ID 叫 spaceId,通过 DESCRIBE SPACE 可以获取 spaceId。然后 Storage 发现某台机器要保存 space 部分数据时,会先单独建一个额外的目录,再建单独 RocksDB 在这个上面起 Rocks 的 instance(实例)用来保存数据,通过这样方式进行物理隔离。这样设计的话,有个弊端:虽然 rocksdb 的 instance,或者说整个 space 目录是互相隔离,但有可能存在同一块盘上,目前资源隔离还做的不够好。
Meta 如何存储 Schema
我们以 CREATE TAG 为例子,当我们建 tag 时,首先会往 meta 发一个请求,让它把这个信息写进去。写入形式非常简单,先获取 tagId,再保存 tag name。底层 RocksDB 存储的 key 便是 tagId 或者是 tag name,value 是它每一个字段里面的定义,比如说,第一个字段是年龄,类型是整型 int;第二个字段是名字,类型是 string。schema 把所有字段的类型和名字全部存在 value 里,以某种序列化形式写到 RocksDB 中。
这里说下,meta 和 storage 两个 service 底层都是 RocksDB 采用 kv 存储,只不过提供了不一样的接口,比如说,meta 提供的接口,可能就是保存某个 tag,以及 tag 上有哪些属性;或者是机器或者 space 之类的元信息,包括像用户权限、配置信息都是存在 meta 里。storage 也是 kv 存储,不过存储的数据是点边数据,提供的接口是取点、取边、取某个点所有出边之类的图操作。整体上,meta 和 storage 在 kv 存储层代码是一模一样,只不过往上暴露的对外接口是不一样的。
最后,storage 和 meta 是分开存储的,二者不是一个进程且存的目录在启动的时指定的也不一样。
追问:meta 机器挂了,该怎么办?
是这样,通常来说 Nebula 建议 meta 以三副本方式部署。这样的话,只挂一台机器是没有问题的。如果单副本部署 meta 挂了的话,是无法对 schema 进行任何操作,包括不能创建 space。因为 storage 和 graph 是不强依赖 meta 的,只有在启动时会从 meta 获取信息,之后都是定期地获取 meta 存储的信息,所以如果你在整个集群跑的过程中,meta 挂了而又不做 schema 修改的话,对 graph 和 storage 是不会有任何影响的。
存储未来规划
Nebula 后面在存储层有什么规划吗?性能,可用性,稳定性方面
性能这块,Nebula 底层采用了 RocksDB,而它的性能主要取决于使用方式,和调参的熟练程度,坦白来说,即便是 Facebook 内部员工来调参也是一门玄学。再者,刚才介绍了 Nebula 的底层 key 存储,比如说 VID 或者是 EdgeType 在底层存储的相对位置某种程度上决定了部分 Query 会有性能影响。从抛开 RocksDB 本身来说,其实还有很多性能上的事情可做:一是写点或者写边时,有些索引需要处理,这会带来额外性能开销。此外,Compaction 和实际业务 workload 也会对性能有很大影响。
稳定性上,Nebula 底层采用 raft 协议,这是保证 Nebula Graph 不丢数据一个非常关键的点。因为只有这层稳定了,再往下面的 RocksDB 写入数据才不会出现数据不一致或者数据丢失的情况发生。此外,Nebula 本身是按照通用型数据库来设计的,会遇到一些通用型数据库共同面临的问题,比如说 DDL 改变;而本身 Nebula 是一款分布式图数据库,也会面临分布式系统所遇到的问题,像网络隔离、网络中断、各种超时或者因为某些原因节点挂了。上面这些问题的话,都需要有应对机制,比如 Nebula 目前支持动态扩缩容,整个流程非常复杂,需要在 meta 上、以及挂掉的节点、剩余“活着”的节点进行数据迁移工作。在这个过程中,中间任何一步失败都要做 Failover 处理。
可用性方面,我们后续会引入主备架构。在有些场景下所涉及的数据量会比较少,不太需要存三副本,单机存储即可。这种全部数据就在单机上的情况,可以减去不必要的 RPC 调用,直接换成本地调用,性能可能会有很大的提升。因为,Nebula 部署一共起 3 个服务:meta、graph 和 storage,如果是单机部署的话,graph + storage 可以放在同一台机器上,原先 graph 需要通过 RPC 调用 storage 接口去获取数据再回到 graph 进行运算。假如你的查询语句是多跳查询,从 graph 发送请求到 storage 这样的调用链路反复执行多次,这会导致网络开销、序列化和反序列化的这些损耗提高。 当 2 个进程(storaged 和 graphd)合在一起,便没有了 RPC 调用,所以性能会有个大提升。此外,这种单机情况下 CPU 利用率会很高,这也是目前 Nebula 存储团队在做的事情,会在下一个大版本同大家见面。
VID 遍历点和边的原理
可以依据 VID 遍历点和边?
从上图你可以看到存储了个 Type 类型,在 v1.x 版本中无论点和边 Type 类型都是一样的,所以就会发生上面说到过的扫描点会夹杂多个边的问题。在 v2.x 开始,将点和边的 Type 进行区分,前缀 Type 值就不一样了,给定一个 VID,无论是查所有 tag 还是所有边,都只需要一次前缀查询,且不会扫描额外数据。
数据预校验
Nebula 是强 Schema 的,插入数据时如何去判断这个字段是否符合定义?
是否符合定义的话,大概是这样,创建 Schema 时会要求指定某个字段是 nullable 或者是有默认值,或者既不是 nullable 也不带默认值。当我们插入一条数据的时候,插入语句会要求你“写明”各个字段的值分别是什么。而这条插入 Query 发到存储层后,存储层会检查是不是所有字段值都有设置,或者写入值的字段是否有默认值或者是 nullable。然后程序会去查是不是所有的字段都可以填上值。如果不是的话,系统会报错,告知用户 Query 有问题无法写入。如果没有报错,storage 就会对 value 进行编码,然后通过 raft 最后写到 RocksDB 里,整个流程大概是这样的。
Nebula 监测
Nebula 可以针对 space来进行统计吗?因为我记得好像针对机器。
这个是非常好的问题,目前答案是不能。这块我们在规划,这个问题的主要原因是 metrics 较少,目前我们支持的 metrics 只有 latency、qps 还有报错的 qps 这三类。每个指标有对应的平均值、最大值、最小值,sum 和 count,以及 p99 之类参数。目前是机器级别的 metrics,后续的话会做两个优化:一个增多 metrics;二是按 space 级别进行统计,对于每个空间来说,我们会提供诸如 fetch、go、lookup 之类语句的 qps。上面是 graph 这边的 metrics,而 storage 这块因为没有强资源隔离能力,还是提供集群或者单个机器级别的 metrics 而不是 space 级别的。
Nebula 的事务
nebula 2.6.0 的边事务是怎么实现的呢?
先说下边事务的背景,背景是上面提到的 Nebula 是存了两份边 2 个 kv,这 2 个 kv 可能会存在不同的节点上,这会导致如果有台机器挂了,其中有一条边可能是没有成功写入。所谓边事务或者叫 TOSS,它主要解决的问题就是当我们遇到其中有一台机器宕机时,存储层能够保证这两个边(出边和入边)的最终一致。这个一致性级别是最终一致,没有选择强一致是因为研发过程中碰到一些报错信息以及数据处理流程上的问题,最后选择了最终一致性。
再来说下 TOSS 处理的整体流程,先往第一个要写入数据的机器发正向边信息,在机器上写个标记,看标记有没有写成功,如果成功了进入到下一步,如果失败直接报错。第二步的话,把反向边信息从第一台机器发给第二台机器,能让存正向边的机器向第二台机器发送反向边信息的原因是,Nebula 中正反向边只有起点和终点调换了一个位置,所以存正向边的机器是完全可以拼出反向边。存反向边的机器收到之后,会直接写入边,并将它的写入结果成功与否告诉第一台机器。第一台机器收到这个写入结果之后,假设它是成功的,它就会把之前第一步写的标记删掉,同时换成正常的边,这时整个边的正常写入流程就完成了,这是一个链式的同步机制。
简单说下失败的流程,一开始第一台机器写失败了直接就报错;第一台机器成功之后,第二台机器写失败了,这种情况下机器一会有背景线程,会一直不断尝试修复第二台机器的边,保证和第一台机器一样。当中比较复杂的是,第一台机器会根据第二台机器返回的错误码进行处理。目前来说,所有的流程都会直接把标记删掉,直接换成正常的正向边,同时写些更额外的标记来表示现在需要恢复的失败边,让它们最终保持一致。
追问:点没有事务吗?
是这样,因为点是只存了一份,所以它是不需要事务的。一般来说,问这个问题的人是想强调点和边之间的事务,像插入边时看点是否存在,或者删除点时删除对应边。目前 Nebula 的悬挂点的设计是出于性能上的考虑。如果要解决上面的问题的话,会引入完整的事务,但这样性能会有个数量级的递减。顺便提下,刚说到 TOSS 是链式形式同步信息,上面也提到能这样做的原因是因为第一个节点能完整拼出第二个节点的数据。但链式的话对完整的事务而言,性能下降会更严重,所以未来事务这块的设计不会采纳这种方式。
数据膨胀问题
首次导入数据是怎么存储的,因为我发现首次导入数据磁盘占用会较多?
大家发现如果磁盘占用高,一般来说是 WAL 文件比较多。因为我们导入的数据量一般比较大,这会产生大量的 wal,在 Nebula 中默认的 wal ttl 是 4 个小时,在这 4 个小时中系统的 WAL 日志是完全不会删除的,这就导致占用的磁盘空间会非常大。此外,RocksDB 中也会写入一份数据,相比后续集群正常运行一段时间,这时候磁盘占用会很高。对应的解决方法也比较简单,导入数据时调小 wal ttl 时间,比如只存半小时或者一个小时,这样磁盘占用率就会减少。当然磁盘空间够大你不做任何处理使用默认 4 小时也 ok。因为过了若干个小时后,有一个背景线程会不断去检查哪些 wal 可以删掉了,比如说默认值 4 个小时之后,一旦发现时过期的 wal 系统便会删掉。
除了初次导入会有个峰值之外,线上业务实时写入数据量并不会很大,wal 文件也相对小。这里不建议手动删 wal 文件,因为可能会出问题正常按照 ttl 来自动删除就行。
compact 都做了什么事可以提高查询,也减小了数据存储占用?
可以看下 RocksDB 介绍和文章,简单说下 Compaction 主要是多路归并排序。RocksDB 是 LSM-Tree 树结构,写入是 append-only 只会追加地写,这会导致数据存在一定的冗余。Compaction 就是用来降低这种冗余,以 sst 作为输入,进行归并排序和去除冗余数据,最后再输出一些 sst。在这个输入输出过程中,Compaction 会检查同一个 key 是否出现在 LSM 中的不同层,如果同一个 key 出现了多次会只保留最新的 key,老 key 删掉,这样提高了 sst 有序的程度,同时 sst 数量和 LSM-Tree 的层数可能会减小,这样查询时候需要读取的 sst 数量就会减少,提高查询效率。
磁盘容量本身不均怎么处理
不同大小的磁盘是否考虑按百分比占用,因为我使用两块不同大小的磁盘,一块占满之后导数就出现问题了
目前是不太好做,主要原因是存储 partition 分布查找是按照轮循形式进行的,另外一个原因是 Nebula 进行 Hash 分片,各个数据盘数据存储大小趋近。这会导致如果两个数据盘大小不一致,一个盘先满了后面的数据就写入不进去。解决方法可以从系统层进行处理,直接把两块盘绑成同一块盘,以同样一个路径挂载。
Nebula 的 RocksDB “魔改”
Nebula 的 RocksDB 存储中,是通过列 column family 来区别 vertex 属性吗?
目前来说,其实我们完全没有用 column family,只用了default column family。后续可能会用,但是不会用来区分 vertex 属性,而是把不同 partition 数据分到不同 column family,这样的好处是直接物理隔离。
Nebula 的魔改 wal 好像是全局 multi-raft 的 wal,但是在目录上体现出来的好像每个图空间都是单独的 wal,这个原理是啥?
首先,Nebula 的确是 multi-raft,但没有全局 wal 的概念。Nebula 的 wal 是针对 partition 级别的,每个 partition 有自己的 wal,并不存在 space 的 wal。至于为啥这么设计,相对来说现在实现方式比较容易,虽然会存在性能损耗,像多个 wal 的话磁盘写入就是个随机写入。但是对 raft 而言,写入瓶颈并不是在这而是系统的网络开销,用户的复制操作 replication 开销是最大的。
这是一个从 https://nebula-graph.com.cn/posts/nebula-storage-on-nlive/ 下的原始话题分离的讨论话题