2.6.1
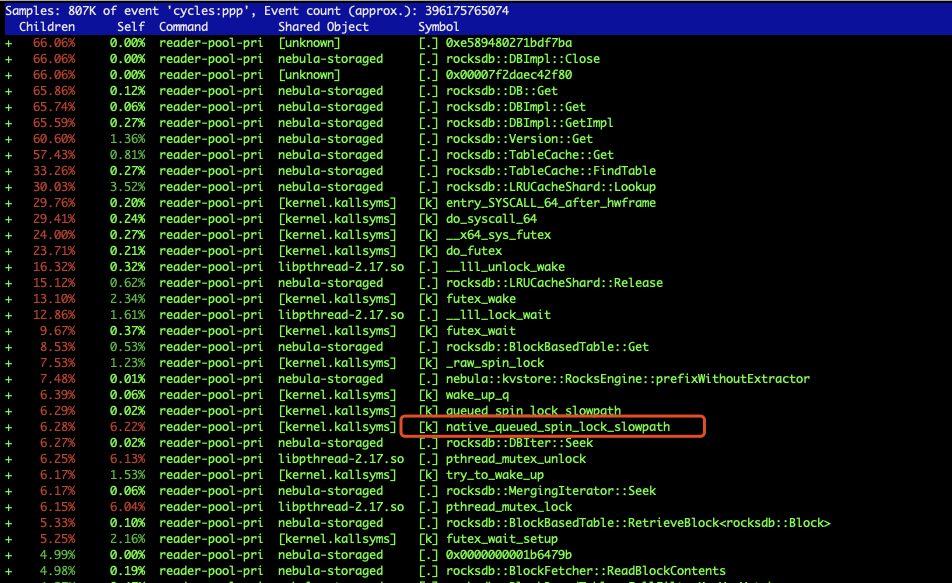
storage中20s内的perf记录
有问题机器
正常机器

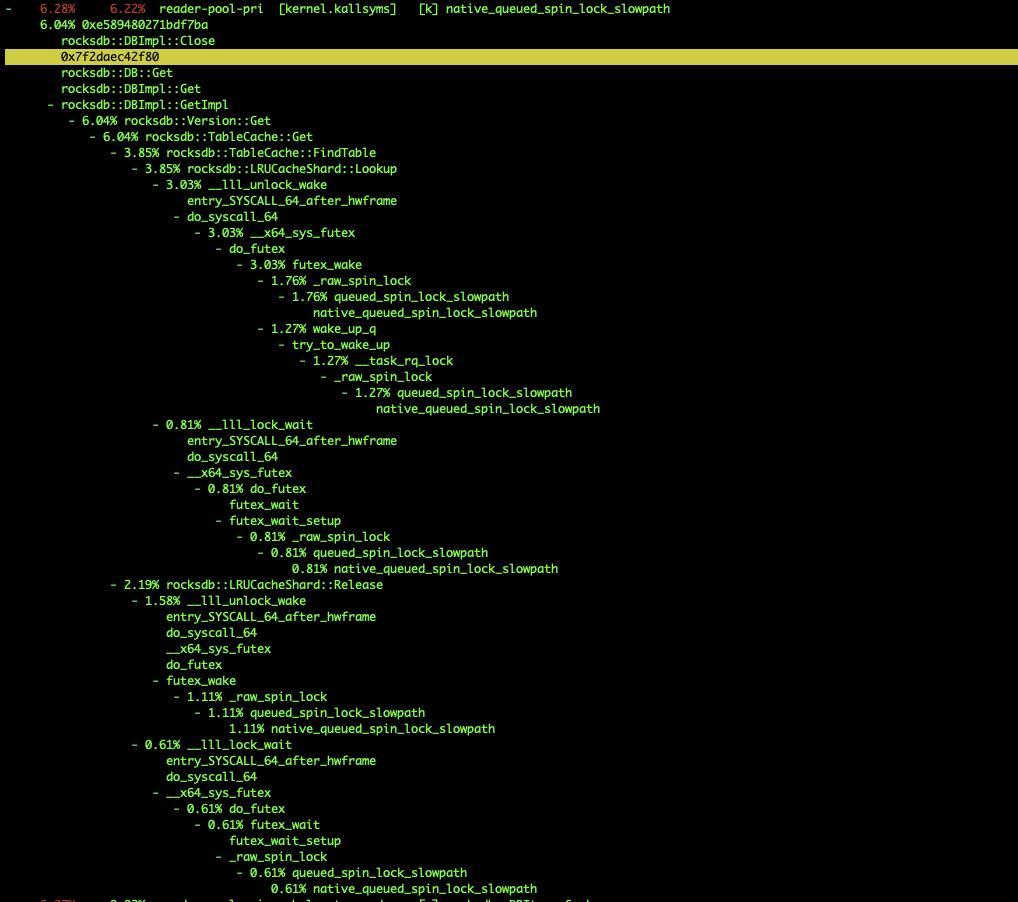
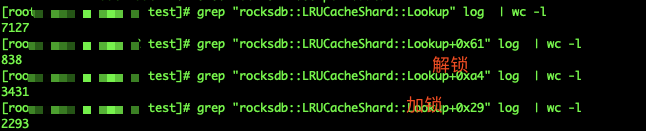
看监控发现 ,有问题的机器,在lrucacheshard加锁 解锁的时候占用很高的cpu,出问题的时候会更高,导致正常的请求timeout,最后导致这个storage不可用,然后整个集群就挂掉了
这种情况有什么缓解的办法吗
2.6.1
storage中20s内的perf记录
有问题机器
正常机器
看监控发现 ,有问题的机器,在lrucacheshard加锁 解锁的时候占用很高的cpu,出问题的时候会更高,导致正常的请求timeout,最后导致这个storage不可用,然后整个集群就挂掉了
这种情况有什么缓解的办法吗
perf record结果和query发下看看,而且有问题机器和正常机器在一个数量级,未必是这里问题,如果真是,LRU可能需要多开点bucket了,但也只能缓解
Get多的话,由于现在用了rocksdb的row cache,所以lock contention可能是会比较严重,可以考虑把bucket设置多点(不过代码里现在好像是写死的)。不过值得注意的好像是另外一个……为啥关rocksdb占用这么高
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。