- nebula 版本:2.5.1
- 部署方式:分布式
- 安装方式:RPM
- 是否为线上版本:Y
- 硬件信息
- 磁盘 SSD
spark批量导入顶点边时,如果使用1个副本数据,可以正常导入数据,没有任务和问题,但是,将副本数修改为3时,导入就会报错,而且只有边6亿+的时候才会报错,千万顶点和边都没有报错,报错如下入
21/12/06 02:39:20 INFO importer.NebulaV2EdgeBatchImporter$: error_code : -1005, error_msg: Storage Error: part: 63, error: E_RPC_FAILURE(-3).
21/12/06 02:39:20 INFO importer.NebulaV2EdgeBatchImporter$: error_code : -1005, error_msg: Storage Error: part: 121, error: E_RPC_FAILURE(-3).
graphd-stderr

当前任务总共6亿+数据
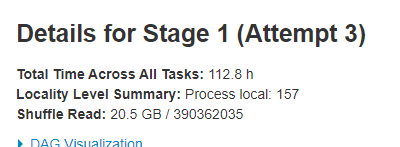
分片改为3以后,速度变慢了n倍。