- nebula 版本:2.0.1
- 部署方式:分布式
- 安装方式:RPM
- 是否为线上版本:Y
- 硬件信息
- 磁盘:SSD
- CPU、内存信息
- 问题的具体描述
- 问题1:drop space 后,手动提交submit job compact,执行成功后,发现storage/data下数据依然存在;过了一两天后,数据还是存在的,请问这个是什么问题?只能手动删除吗?
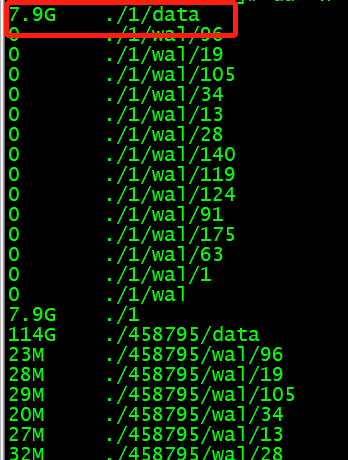
- 问题2:storage配置文件中配置了wal_ttl=14400,但是在不导入新数据的情况下,wal下一直有数据,没有触发回收。是还需要其他参数吗?
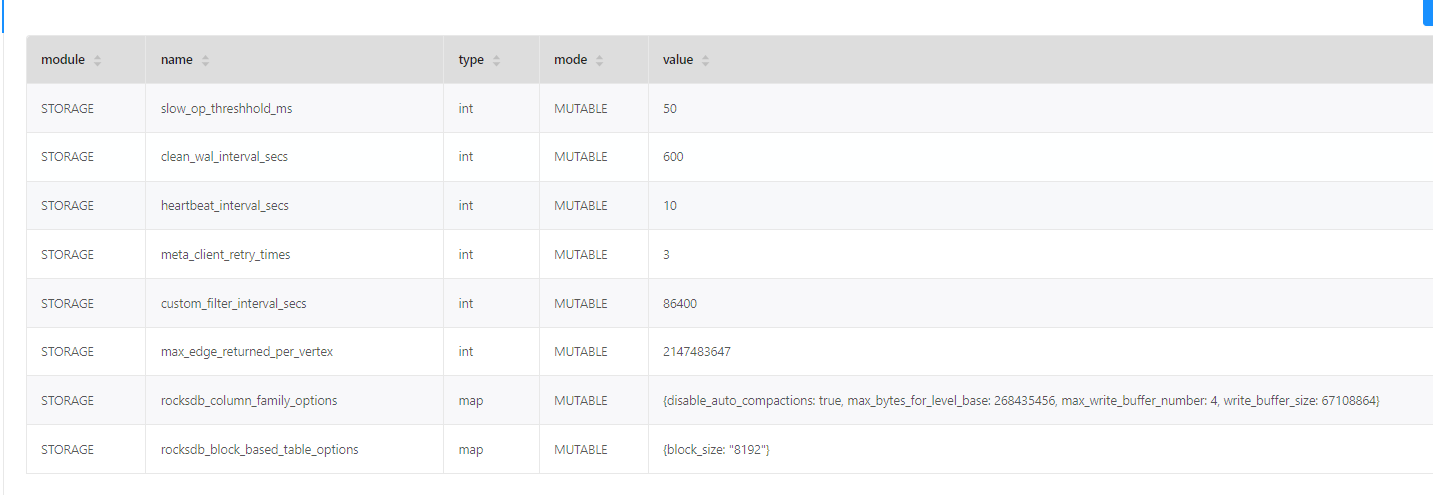
- 配置参数信息如下
- 麻烦抽时间回复下,谢谢

问题一:
是的, 2.0.1 是只能手动删的.
问题二:
2.0.1 那里写的有点毛病:
如果 space 没有 drop 掉的话, 那么过了 ttl 的时间可以把 wal 干掉,
但是 space 一旦被 drop, 对应的 clean wal 的函数就进不去了, wal 也只能手动删.
- 1.这两个问题在新版本有解决吗?具体哪个新版本处理这两个问题?
- 2.wal未清除还有一种情况:space 存在,一段时间内没有数据同步操作,但是storage下旧的wal文件未清除,当天的wal文件内容还有更新?这个是什么原因导致的啊?

-
2.5 之后有个配置参数可以 drop 的时候就删.
-
我先研究下, 应该是 raft 那个空的 AppendEntry 心跳包.
FLAGS_auto_remove_invalid_space
可以参考下的 removeSpace
https://github.com/vesoft-inc/nebula-storage/blob/v2.5.1/src/kvstore/NebulaStore.cpp
- 1.添加参数:auto_remove_invalid_space = true,需要重启storage服务才生效吗?我看参数说明有个 when restart,还是手动执行一次submit job compact就可以啊?
DEFINE_bool(auto_remove_invalid_space, false, "whether remove data of invalid space when restart");
2.当天的wal数据有新增,可以理解为有raft心跳,那wal 旧的文件也超过wal_ttl的配置时间了,为什么没有清除呢?是还需要其他参数配置吗?这个不太明白。
-
需要重启的
-
WAL 会保留最近的 2 个, 从第三个开始删.
(防止出现 wal中还有有用的数据, 然后系统关机了一周, 一启动把原来的 wal 都给删了等问题)
1 个赞
明白了,非常感谢。然后drop space之后,不通过重启storage服务来清除storage/data下的数据是否有开发计划呢 ?毕竟每次都需要重启服务,比较麻烦还有一定的风险。
下个版本就可能会把那个选项默认改为 true.
我的理解好像有点问题,这里说的when restart 是只需在storage配置文件中 添加auto_remove_invalid_space = true,然后重启一次storage服务就可以了。而不是我之前理解的需要先添加配置参数,然后还要在每次drop space后再重启一次storage服务。是这样的吧?
是的, 只用重启一次.
多谢,明白了。
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。