nebula 2.6.1, Spark Connector 2.6.0
对应代码
val sc = spark.sparkContext
spark.sql("use ods_xsyx_risk")
// val dateTime = "20190718"
//从hive中读取数据,数据是在hdfs上,hive是个外部表,你也可以用内部表,都有一样
val df = spark.sql("SELECT store_id, store_code,area_id,area_name,station_code,reserve_bank,status,online_day,first_order_day,is_blacklist" +
" from dwd_risk_control_nebula_vertex_store ")
println("打印行数·······")
df.show(10)
println("打印结束·······")
val config = NebulaConnectionConfig
.builder()
.withMetaAddress("10.67.0.198:9559")
.withGraphAddress("10.67.0.198:9669")
.build()
val nebulaWriteVertexConfig = WriteNebulaVertexConfig
.builder()
.withSpace("gangs_excavate")
.withTag("store_ven")
.withVidField("store_id")
.withVidAsProp(true)
.withBatch(1000)
.withWriteMode(WriteMode.UPDATE)
.build()
df.write.nebula(config, nebulaWriteVertexConfig).writeVertices()
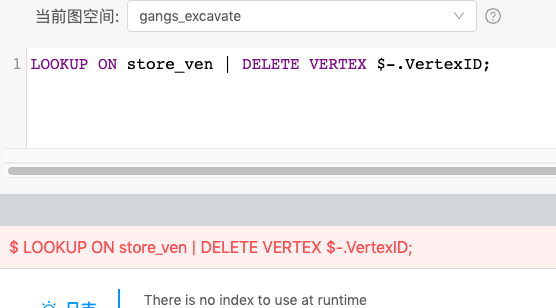
执行错误
manticError: The maximum number of statements allowed has been exceeded | com.vesoft.nebula.connector.writer.NebulaVertexWriter.submit(NebulaWriter.scala:52)