- nebula 版本:2.6.1
- 部署方式:分布式
- 安装方式: RPM
- 是否为线上版本:Y
- 硬件信息
- 问题的具体描述
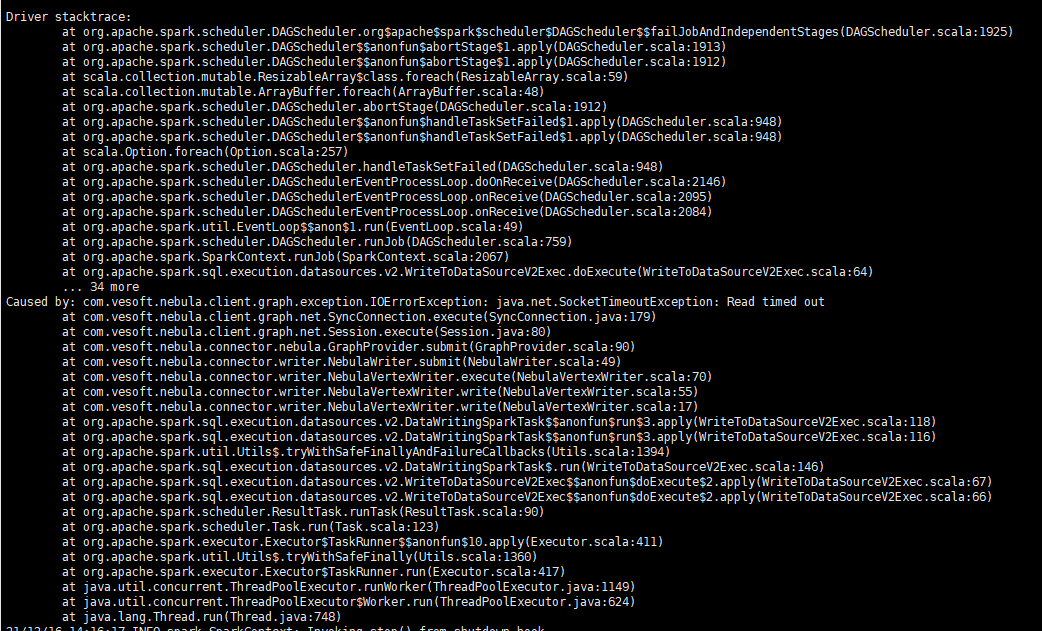
我使用spark-connector编写了一个删除数据的程序,使用的是df.write.nebula()中的WriteMode.DELETE 我看文档说明删除点会同时删除边,所以我先删除边,然后删除点,边的数量有3亿,删除完点应该是不包含边的,然后程序一直报链接超时。
程序终止后,我使用console链接测试下删除,没有任何反应,使用match 查询也没有任何反应,一直处于执行语句的状态,没有返回值,也没有日志产生。所有的space都不可用了。
但是执行submit job xx是可用的,我执行之后 show stats 可以看到边的数据是删除成功的,为0,点的数量还是正常的。我执行了一次compact,由于数据较多暂时没结果。
我使用一个小数据量进行测试,先删边再删点是没有问题的。
1 个赞
compact 执行了2小时还没有结束,初次导入数据时compact也只耗时1个半小时,但是我测试恢复正常了,可以进行查询和删除了。想知道这是什么原因导致的不可用。
之前删除的时候,机器开没开自动 compact ?
没有开自动compact,感觉像是删除数据导致全库查找了。
没有开自动 compact 的话,数据就都在 rocksdb 的 L0 上,然后 L0 因为有重复数据,每个 SST 都会去查,所以会很慢的。
你最开始的诉求是什么?3 亿的边,是一个 space 的全部数据还是部分数据?
如果是全部数据的话,也可以 create space new as old 创建一个新的 space,然后再 drop 老的 space。
https://docs.nebula-graph.com.cn/2.6.1/3.ngql-guide/9.space-statements/1.create-space/#_4
1 个赞
对了,你 storage 机器上的内存,block_cache 配置是多少?
然后一次删除多少个点边?
配置的100g,先删除了两条边,分别为1.5亿,然后再删除边对应的点,这个时候已经不可用了。
我是导入了12亿边8亿的点,导入后做了全量的compaction,这时数据都不在L0了吧,然后我想测试下删除数据的效率,选了两个类型边,一个类型的点进行删除,删除完边之后,再删除点就请求超时,你的意思是删除也会在L0产生文件吗。但是这是整个图库都不可用了,其他space查询也一直请求,直到超时,感觉是图库被卡在什么地方了。最开始的诉求是,删除数据导致的图库不可用,怎么避免和解决,虽然通过compact解决了,但是耗时太久了,有没有别的手段。
这块感觉有点问题,我和存储的同学确认一下。
- 先删除边,然后如果没有开启自动 compact 的话,L0 就有数据。
- 再删除点,因为删除点的时候,我们程序里会找这个点上的边,然后如果 L0 比较大就有可能超时。
如果你们有大量的删除数据,开启自动 compact 会好一些。但是现在的逻辑,删除数据还是会有一点复杂。
1 个赞
好的,因为自动compact会影响导数和查询,所以默认都是关闭的,配置也设置了local_config=true,所以是无法动态更改的。
我将程序更改下如何,先删除点,再删除边。
其实你只要删点就好了,点上的边,程序会删的。
除非你要删除的边,不在点里。
然后如果不开自动 compact 的话,其他查询还是会因为 L0,会比较慢的。
请问这个问题是否有新的进展?主要是L0的数据应该只存在删除数据的space中,别的space无法查询,这个问题是怎么导致的。
没 log盲猜一下, 应该是你这个正在删除的行为, 把全局的线程池跑满了. 导致应该隔离开的 space 也无法工作.
但是数据已经删除完成了,我才进行的查询操作。日志什么都没有打印,就是正常查询的操作,一提交就处于执行状态,一直到超时。但是其他submit 操作或者show 操作都可以。
嗯… submit 跟 show 一般都是在 meta 跑, 您这个应该是 storaged 无响应. 再复现的时候能不能贴下 storage 的 log, 我们好定位一下.
现在这种状态, 我就只能盲猜是某个线程池占满了.
system
关闭
17
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。