1 背景
公司内部有使用图数据库的场景,内部通过技术选型确定了 Nebula Graph 图数据库,首先需要验证 Nebula Graph 数据库在实际业务场景下批量导入性能并验证。在这个过程中发现通过 Exchange 工具通过把 csv 文件放在 hdfs 上,分享下踩过的坑, 希望能让后人少弯路。
2 环境信息
- Nebula Graph 版本:nebula:2.5.0
- 部署方式(分布式 / 单机 / Docker / DBaaS):分布式
- 硬件信息
- 磁盘(SSD / HDD):SSD
- CPU、内存信息:
- 1*.200.66 128G (graph and meta)
- 1*.200.67 128G (graph and meta)
- 1*.200.68 128G (graph and meta)
- 1*.120.10 128G (graph)
- 1*.120.11 128G (graph)
- 1*.120.12 128G (graph)
- 数仓环境:Hadoop 3.2.1
- 编译后生成 jar 包:nebula-exchange-2.5.1.jar
- spark 环境:spark-2.4.7
- maven环境:apache-maven-3.8.4
3 编译 Exchange
- 下载 pulsar-spark-connector_2.11,解压到本地 Maven 库的目录
io/streamnative/connectors中 - 本地环境下克隆:
git clone -b v2.5.1 https://github.com/vesoft-inc/nebula-spark-utils.git - 切换到目录
cd nebula-spark-utils/nebula-exchange - 打包 Nebula Exchange:
mvn clean package -Dmaven.test.skip=true -Dgpg.skip -Dmaven.javadoc.skip=true - 压缩上传到测试环境下
/data/sysdir/nebula-spark-utils-2.5.1
4 更改迁移数据配置
见文件 /data/sysdir/nebula-spark-utils-2.5.1/nebula-spark-utils/nebula-exchange/target/classes/csv_application_2.conf,关键信息如下:
# Nebula Graph相关配置
nebula: {
address:{
# 指定Graph服务和所有Meta服务的IP地址和端口。
# 如果有多台服务器,地址之间用英文逗号(,)分隔。
# 格式: "ip1:port","ip2:port","ip3:port"
graph:["**.**.110.25:9669","**.**.110.26:9669","**.**.110.27:9669","**.**.120.10:9669","**.**.120.11:9669","**.**.120.12:9669"]
meta:["**.**.110.25:9559","**.**.110.26:9559","**.**.110.27:9559"]
}
# 指定拥有Nebula Graph写权限的用户名和密码。
user: root
pswd: ***
# 指定图空间名称。
space: test
5 创建 schema
create space test(vid_type = FIXED_STRING(64));
create tag entity(name string);
create edge relation(name string);
6 传到 hdfs
将测试数据切割后放入到hdfs上(因为文件太大,选取切割方式上传)
hadoop fs -put /data/sysdir/nebula-spark-utils-2.5.1/dataset/*.csv hdfs://hadoopCluster***/user/hive/warehouse/***.db/dataset/
7 数据集信息
- edge.csv 139,951,301 计约:1.4亿条,6.6G
- vertex.csv 74,314,635 计约:7千万,4.6G
合计条数: 214265936 计约:2.14亿,11.2G
8 执行导入命令
/data/sysdir/spark/spark-2.4.7/bin/spark-submit --master yarn --num-executors 50 --class com.vesoft.nebula.exchange.Exchange /data/***/nebula-spark-utils-2.5.1/nebula-exchange/target/nebula-exchange-2.5.1.jar -c /data/***/nebula-spark-utils-2.5.1/nebula-spark-utils/nebula-exchange/target/classes/csv_application_2.conf
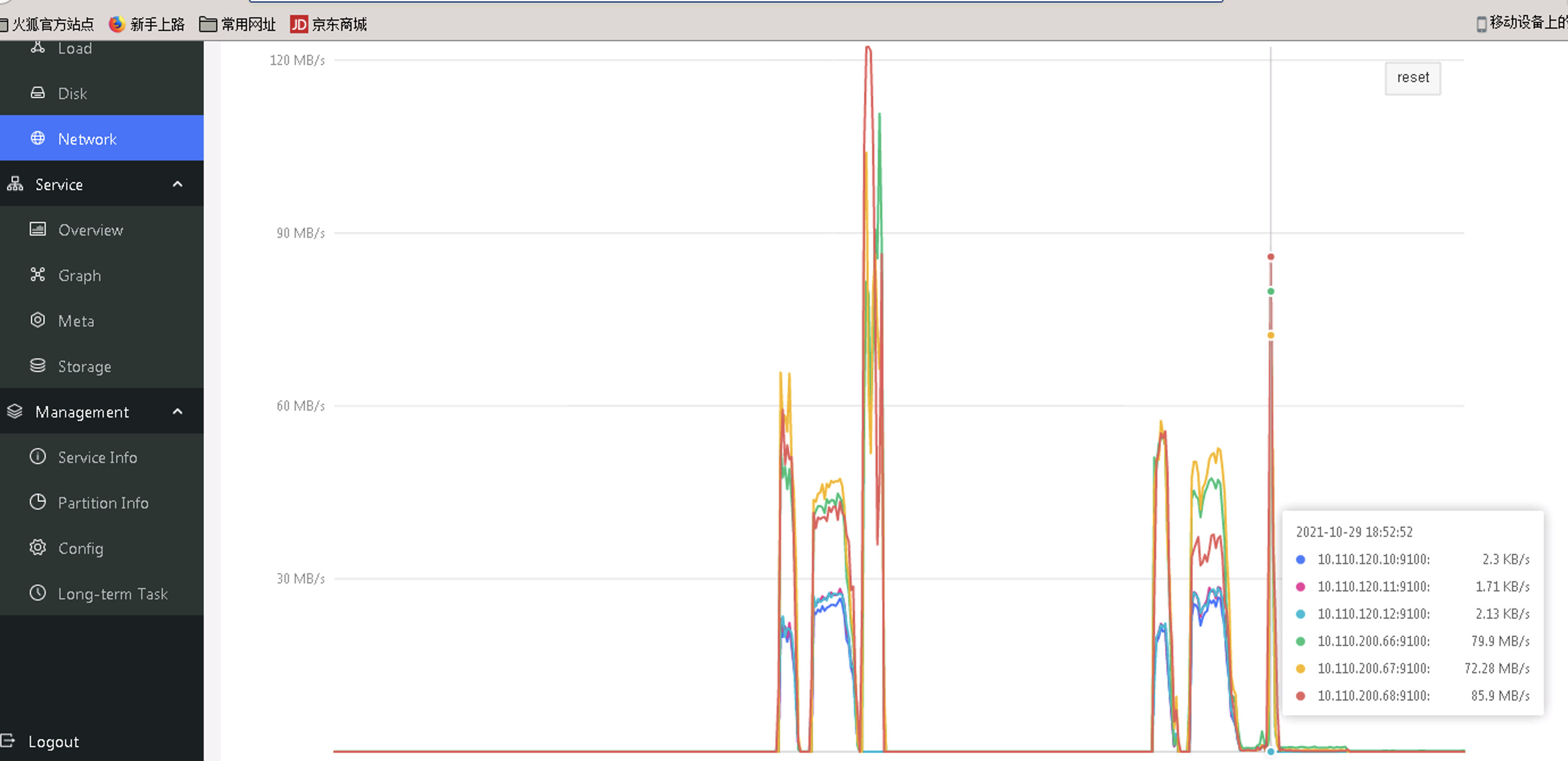
9 性能监控
10 结果验证
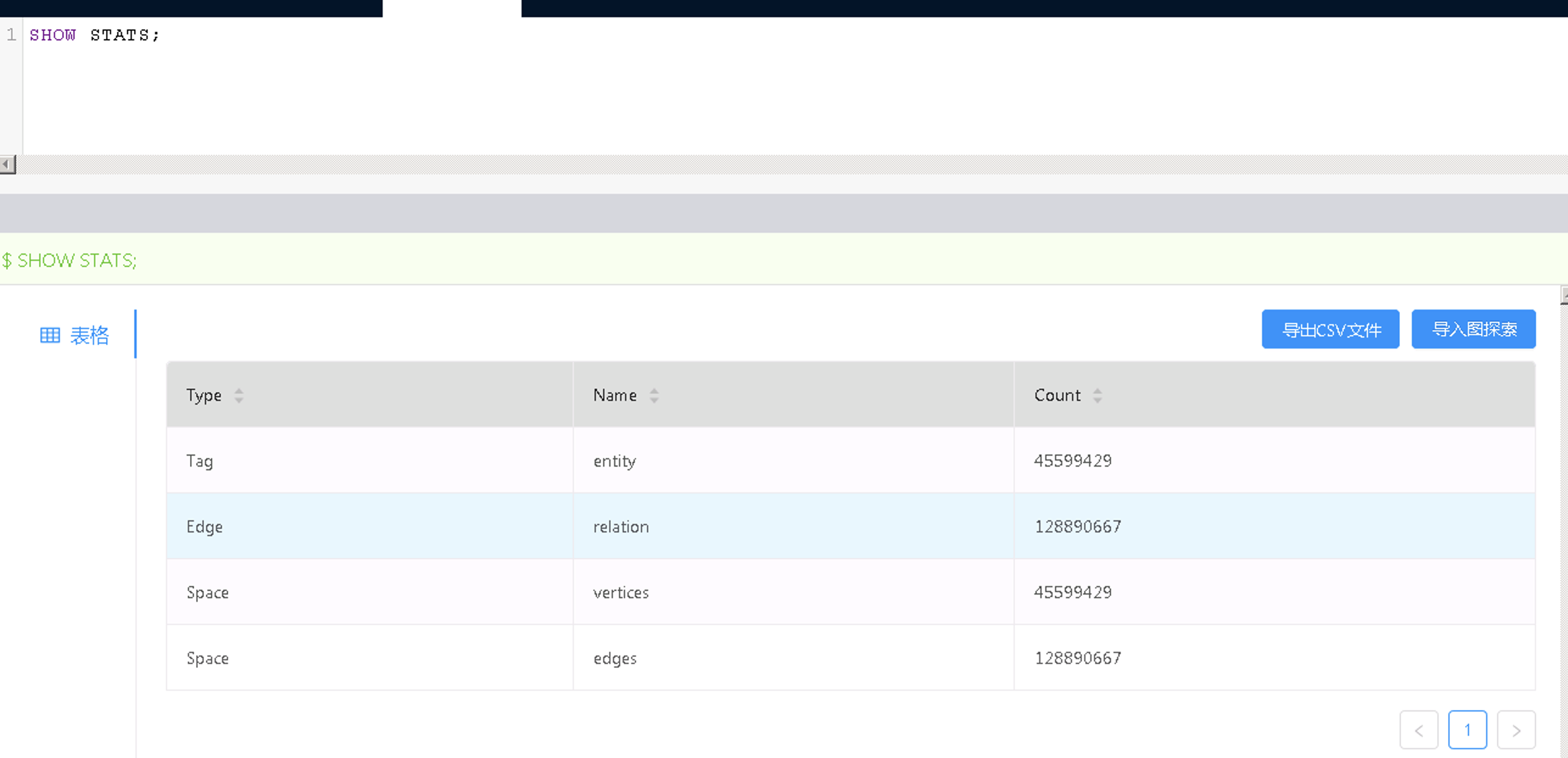
SUBMIT JOB STATS;
SHOW STATS;
11 踩坑阻力点
- 上传csv文件太大,我们采取的时候切割分段上传
- 要搞清楚nebula的存储节点,跟原数据节点的位置,配置文件里会有用到(我就写错了总在过程中报错)
- Nebula Graph 中 tagName 是大小写敏感的,tags 的配置中需要注意好大小写
12 感谢
vesoft 提供了宇宙性能最强的 Nebula Graph 图数据库,我们也在努力尽快让 Nebula Graph 这么好的产品运用起来
疑问
最后还有一些其他疑问?
- 本次数据量级是11.2G,耗时10分钟,然后我们又准备了36G的真实数据集(tag(1:8)、edge(5:18)),同样的方式耗时4.5h,为啥时间拉长了这么久?
- 下一步我们准备调研 Nebula 对事务的控制,有啥好的参考文献么?
验证由养乐多,七分饱先生撰写