- nebula 版本:2.6.1
- 部署方式:分布式
- 安装方式:RPM
- 是否为线上版本: N
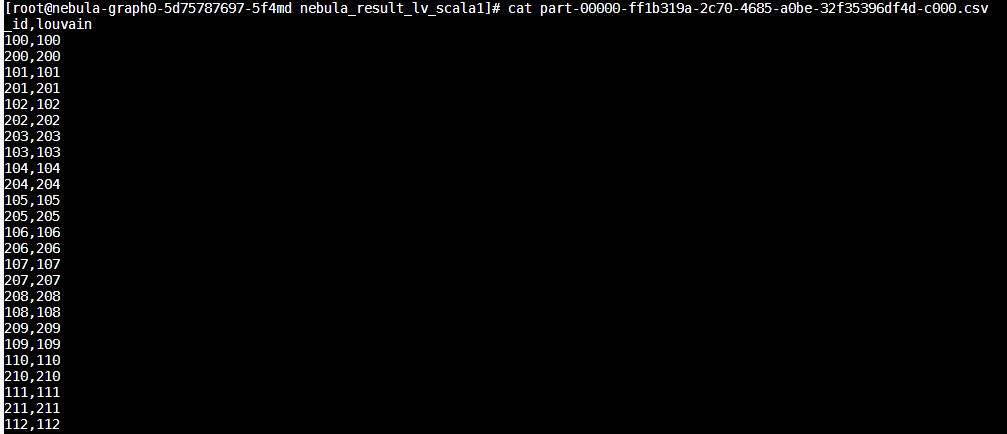
运行louvain算法时,返回的结果为两列,两列都是一样的数值,参见下图
正常的结果不应该是一列为点ID,一列为所在社区ID,怎么会两列数据全都一样,有多个点没显示出来,试了多组数据都是这样,看到有多个帖子都反馈这个都没解决,根据:https://github.com/vesoft-inc/nebula-spark-utils/pull/165 ,这个pr里修改了文件再执行还是一样的结果,求解决,我用的是提交算法包的方式,暂时没有调用接口开发的能力
你用的是什么版本的算法包
nebula-algorithm版本是2.5.1的
你提到的pr的时间晚于2.5.1发版时间
用snapshot版本
要怎么用,snapshot版本在哪里下载或者切换或者安装,小白一枚,不太了解snapshot版本是什么 
1 个赞

下最新时间的包程序包, nebula-algorithm-2.5-2021xxxx.jar
重新部署安装什么? 你如果是自己写代码api调用算法,那就直接把你引用的包版本 从2.5.1换成2.5-SNAPSHOPT。 如果是jar包提交的方式,就直接用这个下载的包
直接把nebula-algorithm-2.5-2021xxxx.jar、nebula-algorithm-2.5-2021xxxx-javadoc.jar、nebula-algorithm-2.5-2021xxxx-sources.jar这三个包下载下来放到nebula-algorithm/target路径下就可以直接提交使用了是吗?其他.jar.asc、.jar.md5、.jar.sha1、pom文件,以及tests.jar不用管是嘛?用的是jar包提交的方式
直接下载nebula-algorithm-2.5-2021xxxx.jar这一个包, 随便放哪都行
可以了,但是又发现一个新问题,就是application.conf文件中hasWeight参数的默认是false,我想把边上的权值也加入到louvain算法的计算中,就把这个参数改成了true,出来的结果又和之前的问题一样两列的值都是一样的,参数用false的话结果就正常,请问是参数的原因嘛?还是说是哪里出了问题
参数原因,看你选了哪个字段作为权重,这个字段是不是真的有意义
我选的是边的一个属性,格式是int64的,里面确定是有值的,并且labels和weightCols参数分别为边类型和属性名称,试了多组不同数据,都是hasWeight参数为false时结果正常,为true时就出现结果的两列值就一样的问题了
权重为true时,得到的结果集中点的数据量是对的么
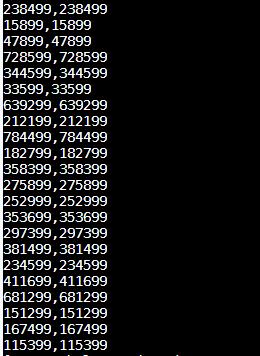
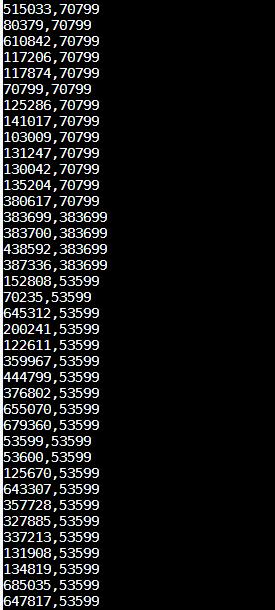
我是指点的数据量,如果点的数据量正确,两边一致说明权重值无法重组成新社区
我用了多组数据(包括官方文档里下载的basketballplayer那个数据集),每组数据的都是完全不一样的权值试了都是这样的问题,您这边不知能否提供一下您那边测试过权值为true的数据集供我这边测试一下,我这边用的数据集通过Python跑louvain是可以重新组成多个新社区的
得到的点的数据量也比原来的少