- nebula 版本:2.6.1
- 部署方式:分布式
- 安装方式: Docker
- 是否为线上版本:Y
partition num: 100
replicas: 3
今天发现丢了27个partition

show parts后发现lost的partition的ip并不在当前的storaged里,有什么办法修复吗?
partition num: 100
replicas: 3
今天发现丢了27个partition
show parts后发现lost的partition的ip并不在当前的storaged里,有什么办法修复吗?
那是因为你建space时候应该是包含了那个storage,现在除非把它加回来否则搞不定
这是bug吗 
集群的结构能否说说看, 除了那个掉线的之外还有几个storaged?
6个graph,3个meta,10个storage
replica: 3
partition num: 100
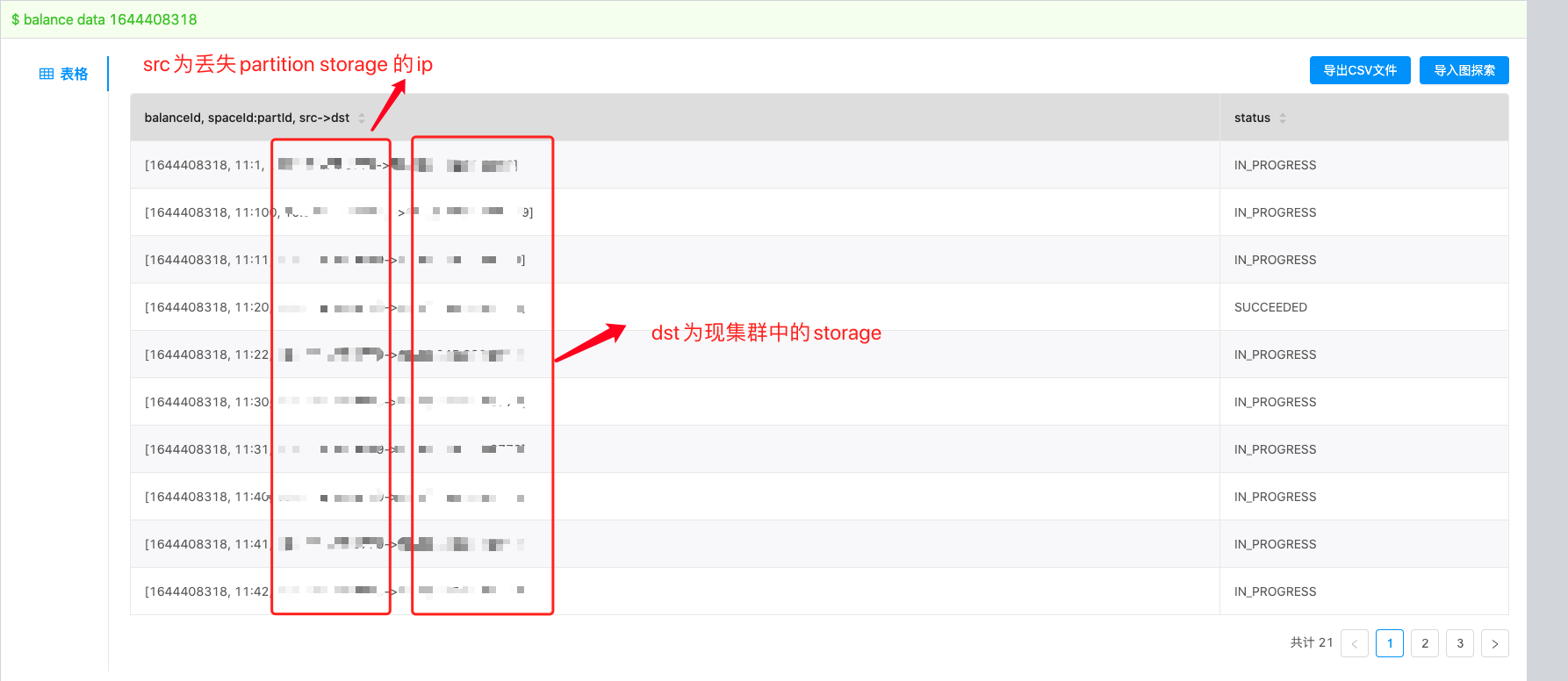
那个storage掉线之后应该是补了一个新的,集群里已经没有这个丢掉的storage了。show hosts也没有丢掉的这个storage,show parts显示丢了27个这个storage上的partition
balance data过后,生成的plan显示是从丢掉的storage(src)到集群里现有的storage(dst),多balance几次过后丢掉的partition又全都回来了
这是什么操作 partition还能从丢掉的storage里回来
storage掉线后默认一天之后会从集群中删除,这时候应该不会自动balance data,所以会显示有差不多1/10的partition不见了。后面你做balance data时应该会发现这些lost的partition,然后从其他的副本里复制数据到其他节点来恢复3副本。plan上显示已经掉线的storaged ip逻辑上也说的通,如果改成显示其他副本的仍然在线的storaged ip会更加让人迷惑吧,你想想看。
“从其他的副本里复制数据到其他节点来恢复3副本”指的是从leader将数据复制过来的吗?还是raft group中的follower也行呢?plan显示从一个已经不存在的storage ip 将数据复制过来确实会很疑惑呀 
显示的part从a → b是指原来part在a上,现在会挪到b上,数据不一定是从a过来,而是从这个part的leader过来。所以显示的是part的分布变化,而不是数据流的变化。
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。