
业务背景
泰康在线作为一家互联网保险公司,拥有过亿的海量客户群体。对这些客户进行精准营销,或者是保险业务里的风险控制,就需要对客户之间的关联关系、客户与特征标签的关系,进行高效的管理和计算处理。
在技术方面也存在类似的事物间关联关系管理的诉求。比如数据治理,我们需要建立多个系统间的数据血缘关系。应用系统监控,也同样需要管理服务器、应用、接口间的相互关联关系。
传统的关系型数据库,在管理深度关联关系方面,存在明显的性能问题。而图数据库在这方面具有天然的优势,能够非常方便地存储实体间的关联关系,并可以进行灵活的扩展。特别是分布式图数据库,能够有效处理海量的关联关系的存储甚至是计算问题。
于是,在 2020 年下半年,泰康在线的技术团队启动了图数据库的调研。
技术选型
对于图数据库的选择,我们技术选型的要求如下:
- 开源软件且社区活跃。毕竟我们还处于探索阶段,必须节省成本。
- 能够支持十亿级节点、百亿级边。这是业务数据规模决定的。
- 分布式架构,支持横向扩展。
- 多跳查询延迟在毫秒级。这是为了支持某些 OLTP 场景。
- 学习门槛低。
图数据库调研
基于上述选型要求,我们对 DB-Engines 排名靠前的图数据库进行了相关调研。在这里面,Neo4j、ArangoDB 虽然开源,但是只有单机版本开源可用;JanusGraph、HugeGraph,具有通用的图语义解释层、提供了图遍历的能力,但是受到存储层或者架构限制,多跳遍历的性能较差,很难满足 OLTP 场景下对低延时的要求;DGraph、Nebula Graph,根据图数据的特点对数据存储模型、点边分布、执行引擎进行了全新设计,对图的多跳遍历进行了深度优化,能够满足我们的选型要求。通过查阅相关资料,我们发现 Nebula Graph 在性能、社区活跃度方面,都比 DGraph 要高一些。所以,最终我们选择了 Nebula Graph。
在实际应用之前,我们对 Nebula Graph 进行了一系列的技术调研。其中,我们选择了理赔业务数据进行了数据导入、多跳查询的实际测试。我们需要的版本是 Nebula Graph 2.0,导入工具采用 nebulagraph-importer,导入方式为 csv 文件导入。测试数据为 7,000 万理赔数据,包含约 1.5 亿节点、2.1 亿边。实际测试环境,我们的 Nebula Graph 2.0 部署在 3 台物理机上,每台物理机配置如下:
- CPU:2核(Intel(R) Xeon(R) Gold 6240 CPU @ 2.60GHz)
- 内存:128G
- 硬盘:SAS盘
实测数据导入速度:点导入速度约 75 万/秒,边导入速度约 62 万/秒。
19:35:10 [INFO] statsmgr.go:61: Done(/home/appadmin/tools/vertex.csv): Time(206.88s), Finished(155756618), Failed(0), Latency AVG(53696us), Batches Req AVG(99743us), Rows AVG(752877.65/s)
19:37:23 [INFO] statsmgr.go:61: Done(/home/appadmin/tools/edge.csv): Time(340.29s), Finished(213307919), Failed(0), Latency AVG(52057us), Batches Req AVG(94303us), Rows AVG(626848.88/s)
这个导入速度,已经完全满足我们的业务场景要求。在多跳查询方面,我们也进行了简单的测试,实际查询速度基本都不到 100 毫秒,满足我们的要求。
通过这些调研,我们发现 Nebula Graph 完全能够满足我们的业务场景要求。于是,我们最终选择 Nebula Graph 作为我们图计算平台的基础组件。
解决方案设计
为了应对不同的业务场景,我们建立了初步的图计算平台:
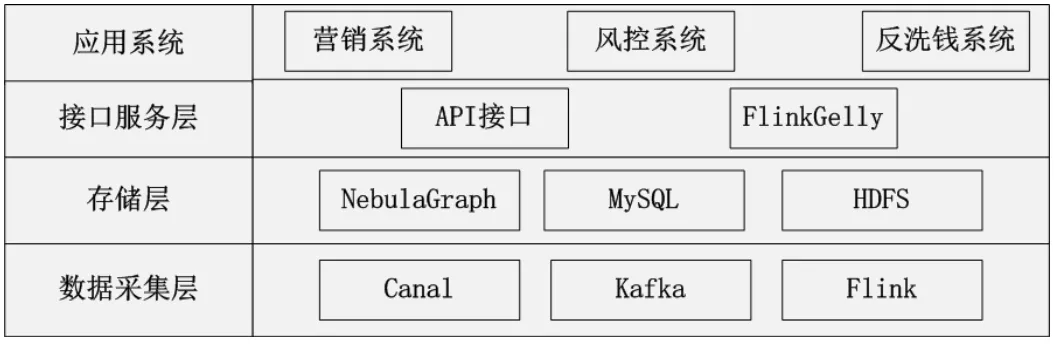
其中,数据通过 Canal、Kafka、Flink 等组件处理后,进入存储层。存储层由多种存储引擎组成,核心组件是 Nebula Graph。对外提供的服务方式,有 API 接口和图计算框架 Flink Gelly,分别应用于实时交互和图计算场景。整个平台,可以服务于多种业务:营销、风控、反洗钱等。目前,我们主要应用于时效要求不高的离线场景。
成果展示
针对不同的业务场景,我们采用 Nebula Graph 进行了一些实际的业务实际。
案例1. 理赔反欺诈
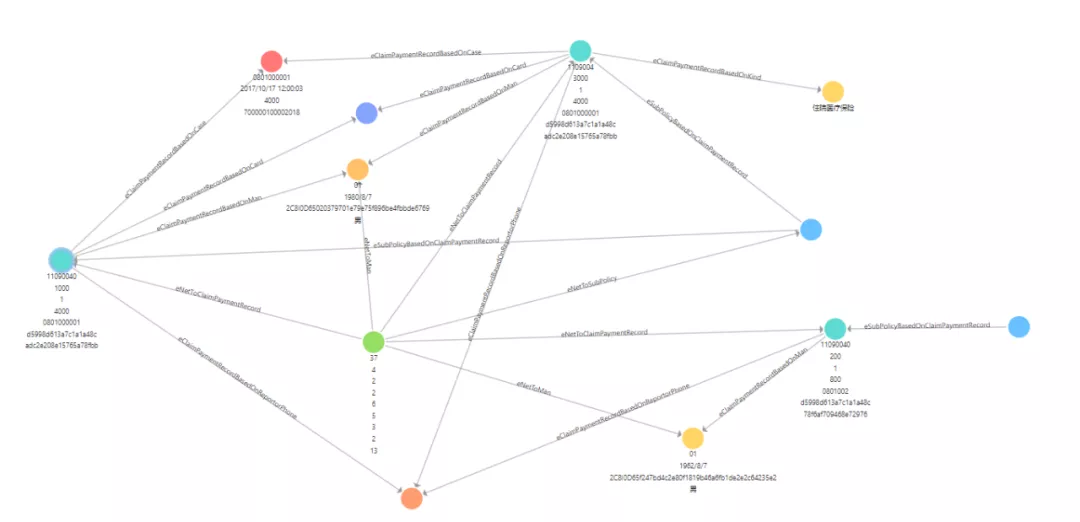
这是基于客户关联关系构建的知识图谱,已经应用于理赔反欺诈场景。通过建立客户与赔案、证件号、手机号、邮箱的知识图谱,我们就可以通过 Flink Gelly 对其进行连通子图的计算,获取有关联关系的理赔客户群。基于不同的业务筛选条件,来发现可疑的理赔欺诈团伙。
案例2. 数据血缘关系
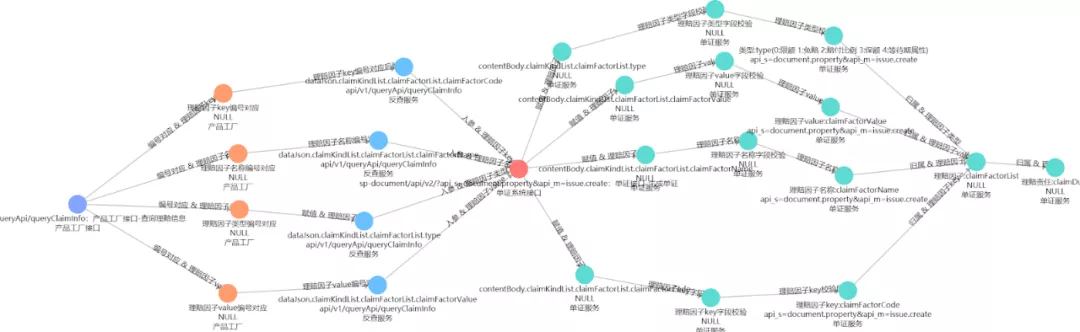
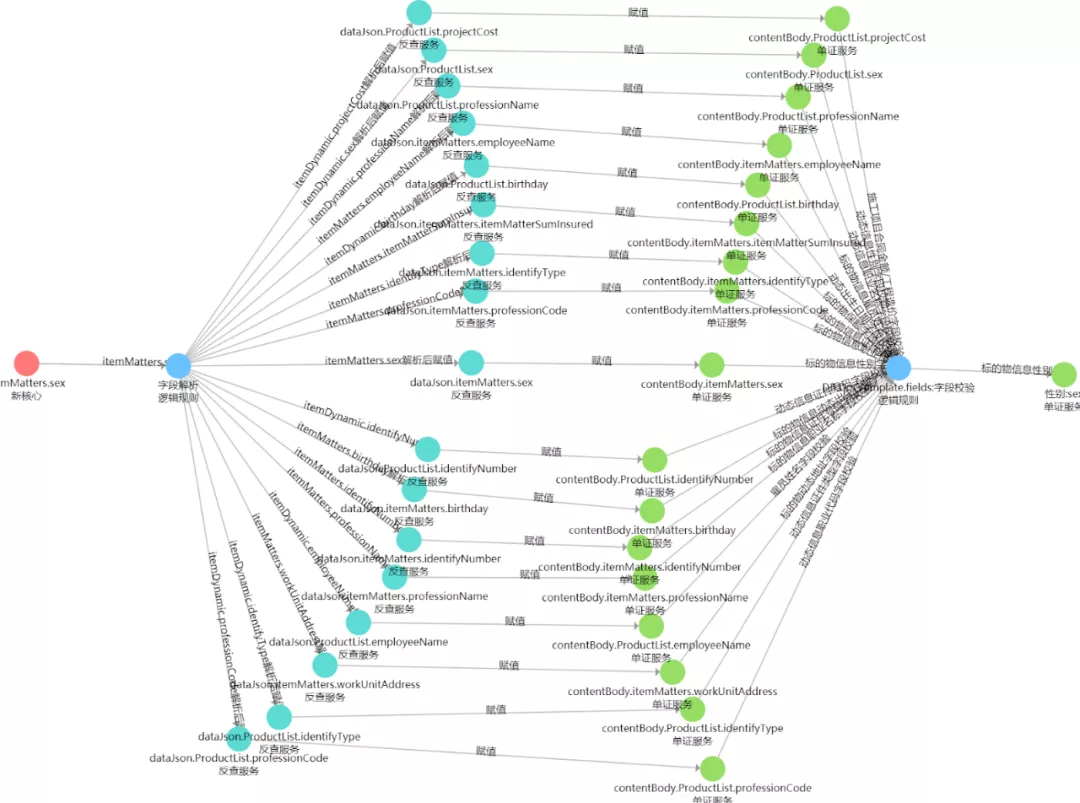
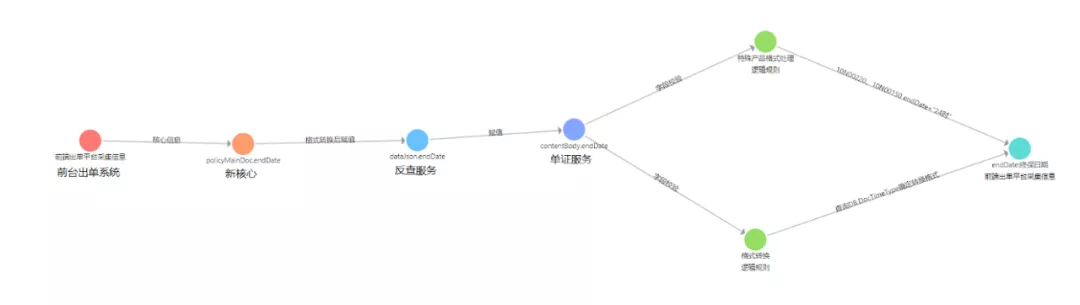
这是我们在系统间的数据血缘关系方面的应用。图示的是电子保单的数据流转链路、产品工厂和核心系统跟电子保单之间的数据关联关系。因为电子保单的数据,来自多个系统,调用关系复杂。通过图谱来展示这些关联关系,我们很方便地定位电子保单错误信息的数据来源,提高开发人员的联调效率。
案例3. 应用监控
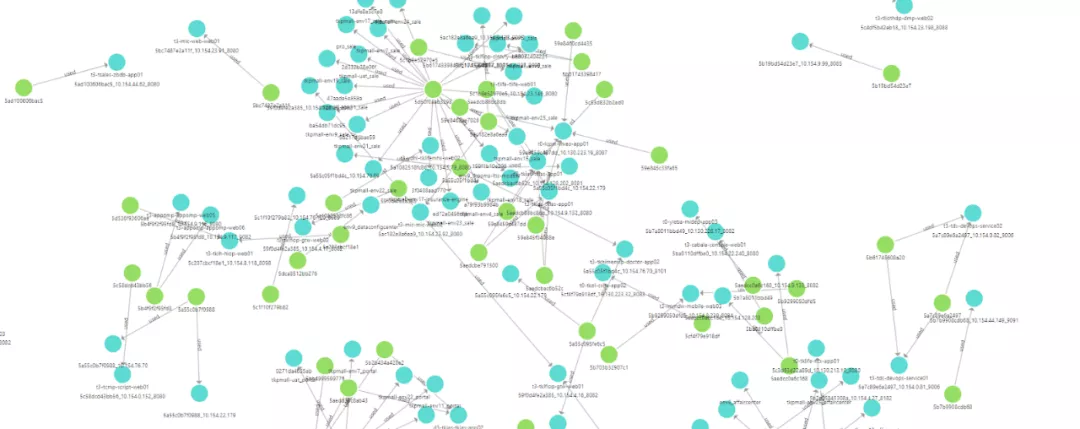
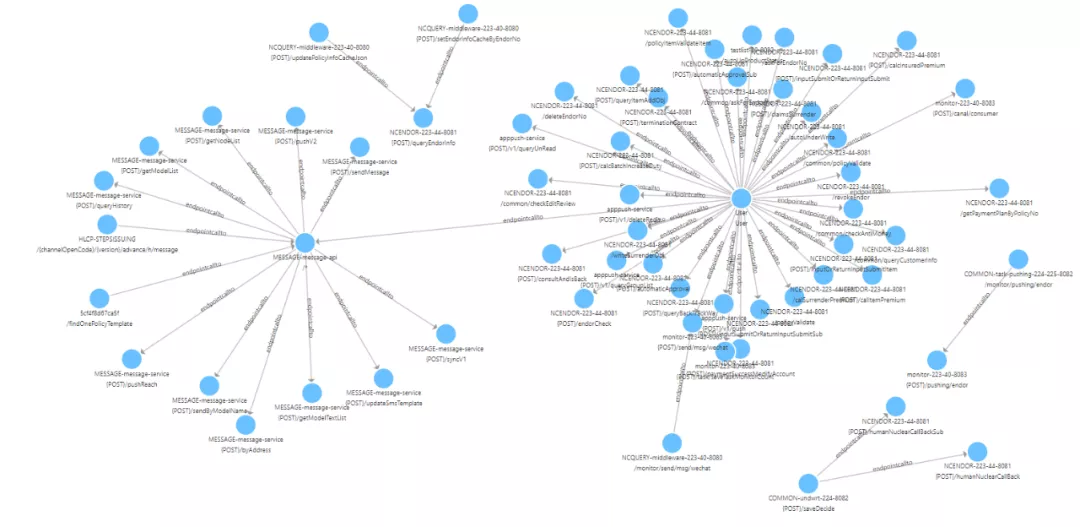
这是我们基于 Nebula Graph 建立的应用服务器、接口之间的关联图谱。基于这些关联关系,我们构建自己的应用监控系统。有了这些关联关系做基础,我们就可以很方便、直观地管理我们的应用系统,监控相关的异常告警,并在故障根因分析方面提供便利。
致谢
上面是泰康在线利用 Nebula Graph 在业务应用上进行的一些探索和初步的实践。虽然还只是一个起步,但是让我们感受到了分布式图数据库的巨大潜力。后续我们还会继续扩宽图数据库的应用,包括实时交互场景。
目前 Nebula Graph 在使用过程中,性能和稳定性都表现很优秀。整个探索过程中,Nebula Graph 的研发团队和社区也给了我们很多帮助,在此,对他们表示衷心的感谢!
这是一个从 https://nebula-graph.com.cn/posts/tk.cn-knowledge-graph-practice/ 下的原始话题分离的讨论话题