Nebula Graph 1.0 基准性能测试
测试环境
硬件
配置如下:
- 处理器: Intel(R) Xeon(R) CPU E5-2697 v3 @ 2.60GHz, 2(sockets) * 14(cores) * 2(threads)
- 内存:DDR4,64GB * 4
- 存储:HP MT0800KEXUU,NVMe,800GB * 2
- 网络:Mellanox MT27500 10Gb/s
本测试共使用 5 台服务器,其中 graphd 1 台,storaged 3 台,客户端 1 台。
软件
Nebula Graph版本:V1.0.0 GA
操作系统:Centos 7.5
查询服务(graphd)为单节点;
存储服务(storaged)为三节点,24 个partition;
元数据服务(metad)为三节点,与 storaged 混布;
客户端使用 Golang API,采用单进程多协程同步请求发压,占用 1 台服务器。
Nebula Graph 服务端关键配置项
Storaged:
# 每个硬盘设置一个 RocksDB 实例
# The default reserved bytes for one batch operation
--rocksdb_batch_size=4096
# The default block cache size used in BlockBasedTable.
# The unit is MB.
--rocksdb_block_cache=102400
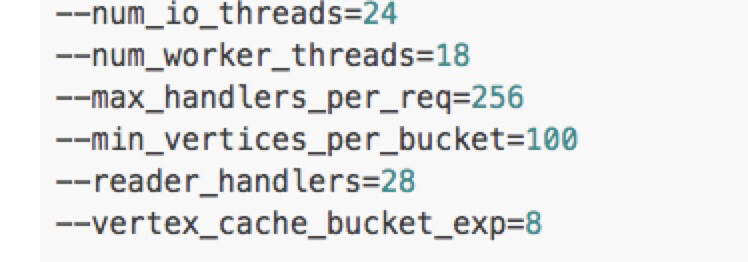
--num_io_threads=24
--num_worker_threads=18
--max_handlers_per_req=256
--min_vertices_per_bucket=100
--reader_handlers=28
--vertex_cache_bucket_exp=8
--rocksdb_disable_wal=true
--rocksdb_column_family_options={"write_buffer_size":"67108864",
"max_write_buffer_number":"4","max_bytes_for_level_base":"268435456"}
--rocksdb_block_based_table_options={"block_size":"8192"}
Graphd:
# The number of networking IO threads, 0 for # of CPU cores
--num_netio_threads=20
# The number of threads to execute user queries, 0 for # of CPU cores
--num_worker_threads=32
--storage_client_timeout_ms=600000
--filter_pushdown=false
数据集介绍
- 数据源:LDBC Social Network Benchmark Dataset
- 数据规模:Scale Factor 为 1000
- 源数据大小:632 GB
- 导入后(集群)占用空间:~500 GB * 副本数量
- 点数:1,243,792,996
- 边数:8,397,443,896
注1:LDBC benchmarks 数据集模拟一个典型的社交网络分布,更多介绍见 https://github.com/ldbc
Schema

数据集 k-hop 出度分布情况
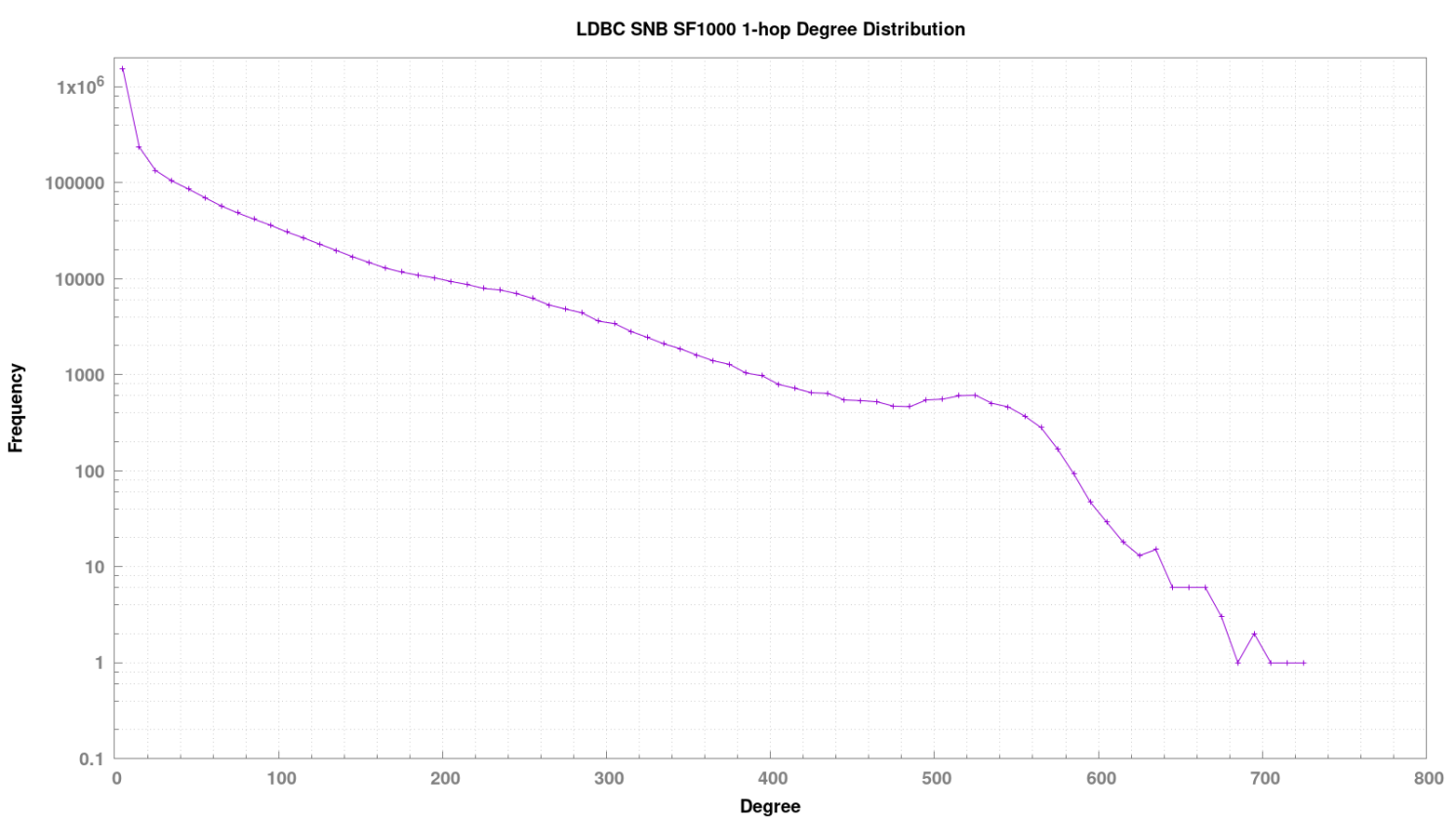
1 跳出度分布情况
绝大多数节点的出度在 10 以内,个别稠密点的出度为 700
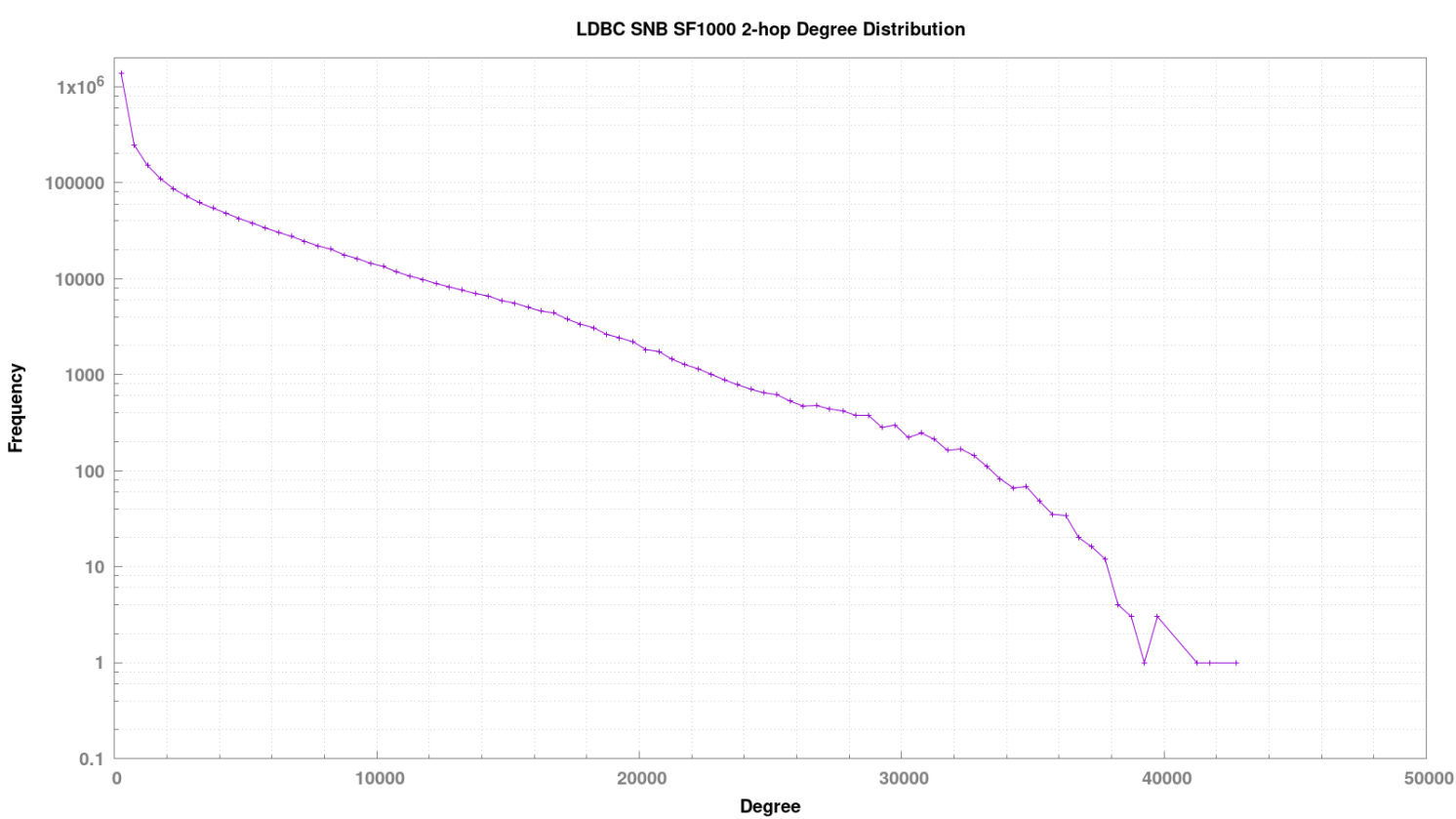
2 跳出度分布情况
绝大多数节点 2 跳近邻的个数为 2000 以内,个别稠密点的 2 跳近邻数量为 40000
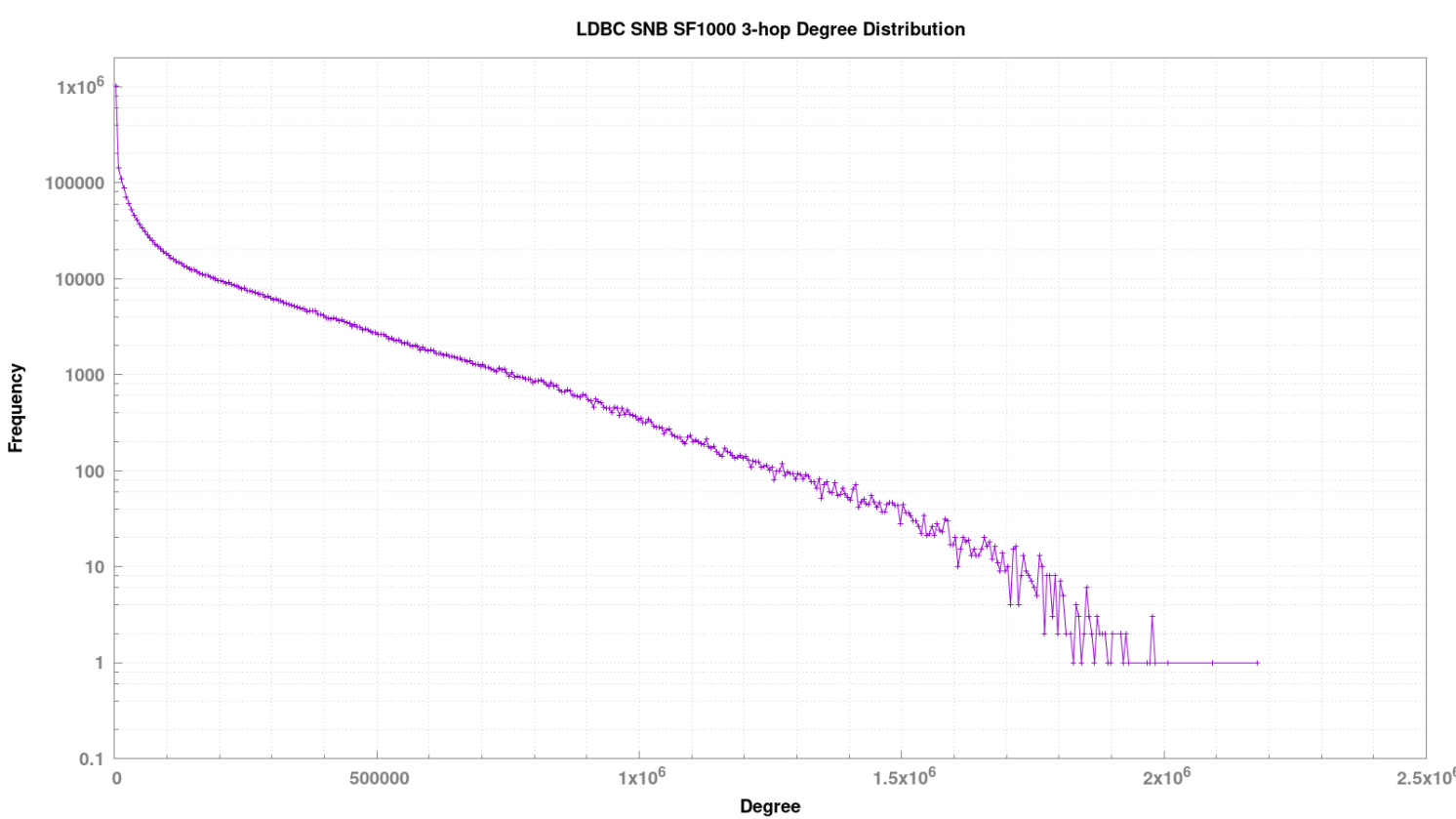
3 跳出度分布情况
绝大多数节点3跳近邻的个数为 100,000 以内,个别稠密点的 3 跳近邻数量为 2,000,000
查询语句示例
k-hop 不返回属性
GO 1 STEP FROM $ID$ OVER knows
GO 2 STEP FROM $ID$ OVER knows
GO 3 STEP FROM $ID$ OVER knows
k-hop 返回属性
GO 1 STEPS FROM $ID$ OVER knows YIELD knows.time, $$.person.first_name,\
$$.person.last_name, $$.person.birthday
GO 2 STEPS FROM $ID$ OVER knows YIELD knows.time, $$.person.first_name,\
$$.person.last_name, $$.person.birthday
GO 3 STEPS FROM $ID$ OVER knows YIELD knows.time, $$.person.first_name,\
$$.person.last_name, $$.person.birthday
注2:语句中 $ID$ 为图遍历起点 ID 占位符,执行时会被替换为真实随机 ID。
测试结果
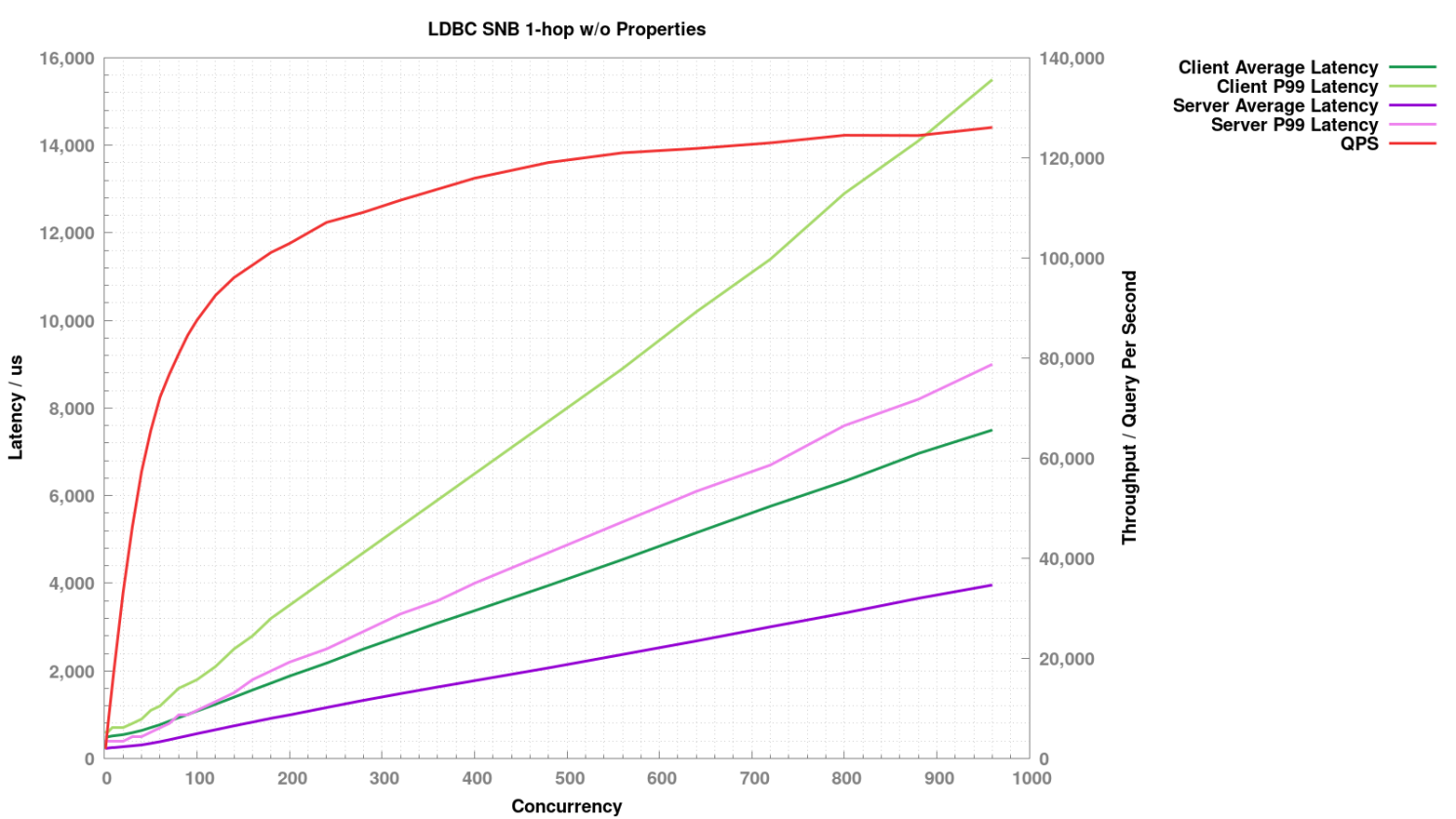
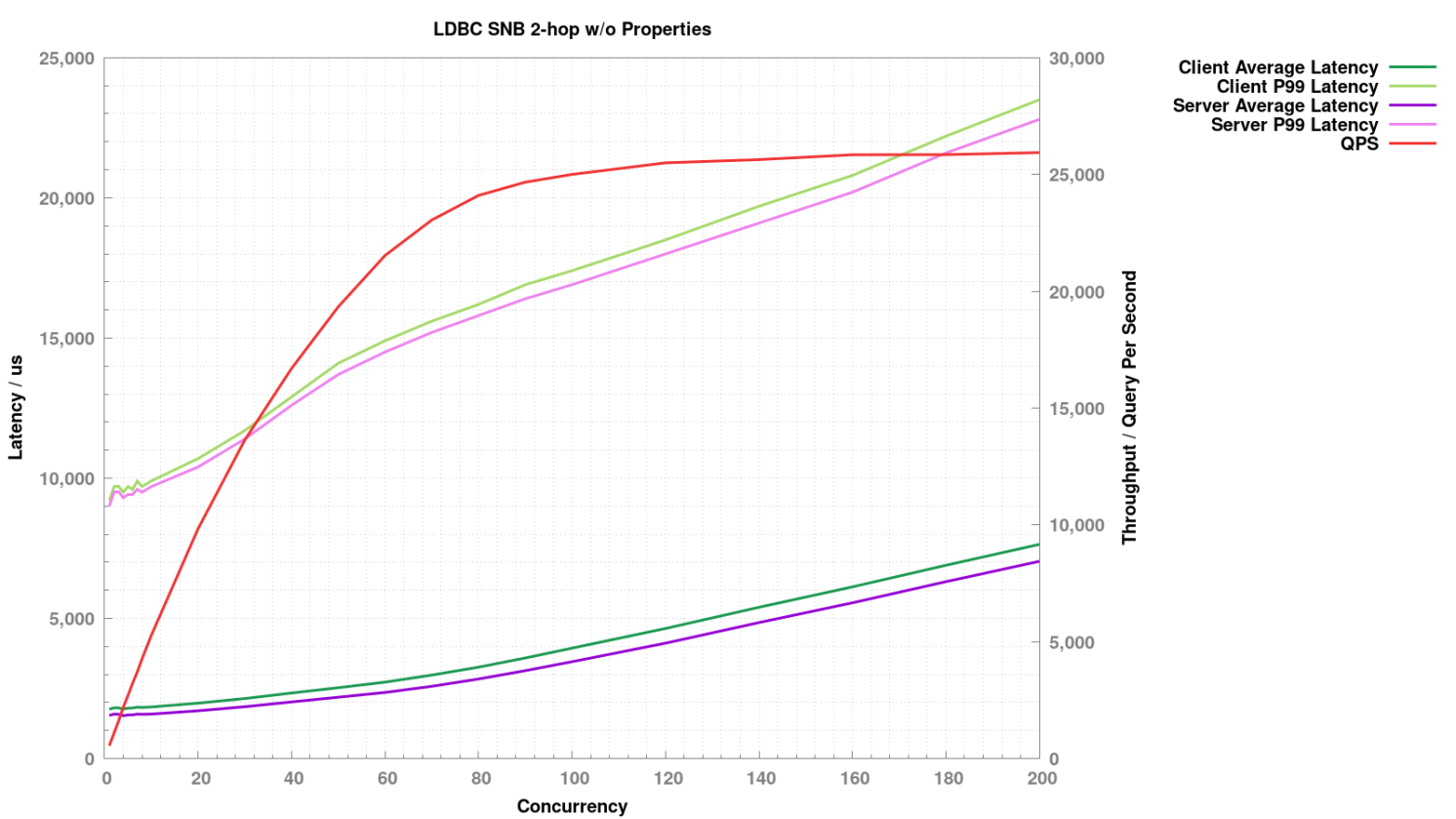
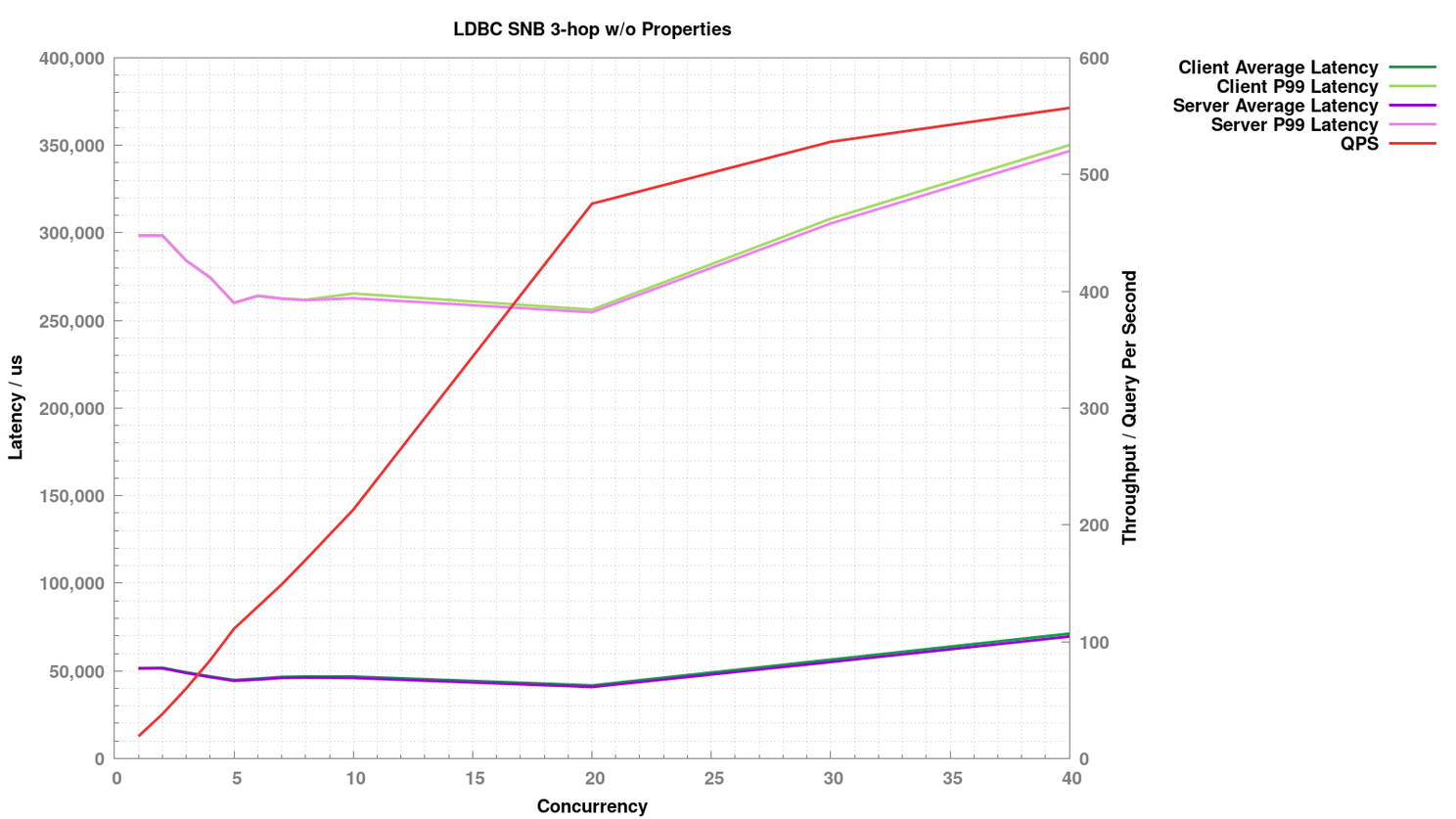
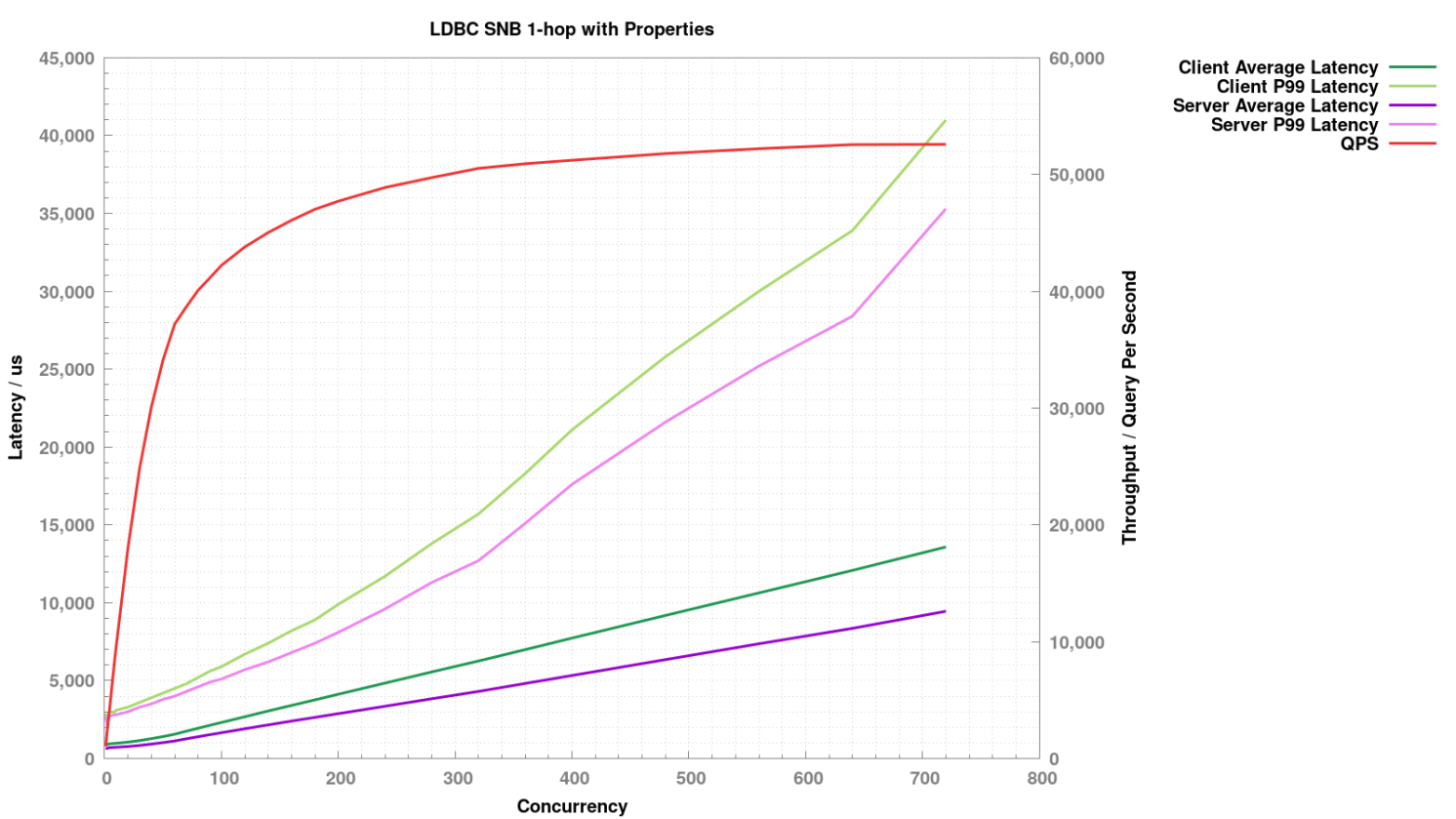
针对每种查询,逐步增大并发度,观察此时吞吐和延时的表现。
1-hop 不返回属性
2-hop 不返回属性
3-hop 不返回属性
1-hop 返回属性
2-hop 返回属性

3-hop 返回属性

其他
测试代码和 nGQL 可以在这里找到 https://github.com/dutor/nebula-bench
有疑问欢迎在下方跟帖留言。