版本:2.6.0
scheme
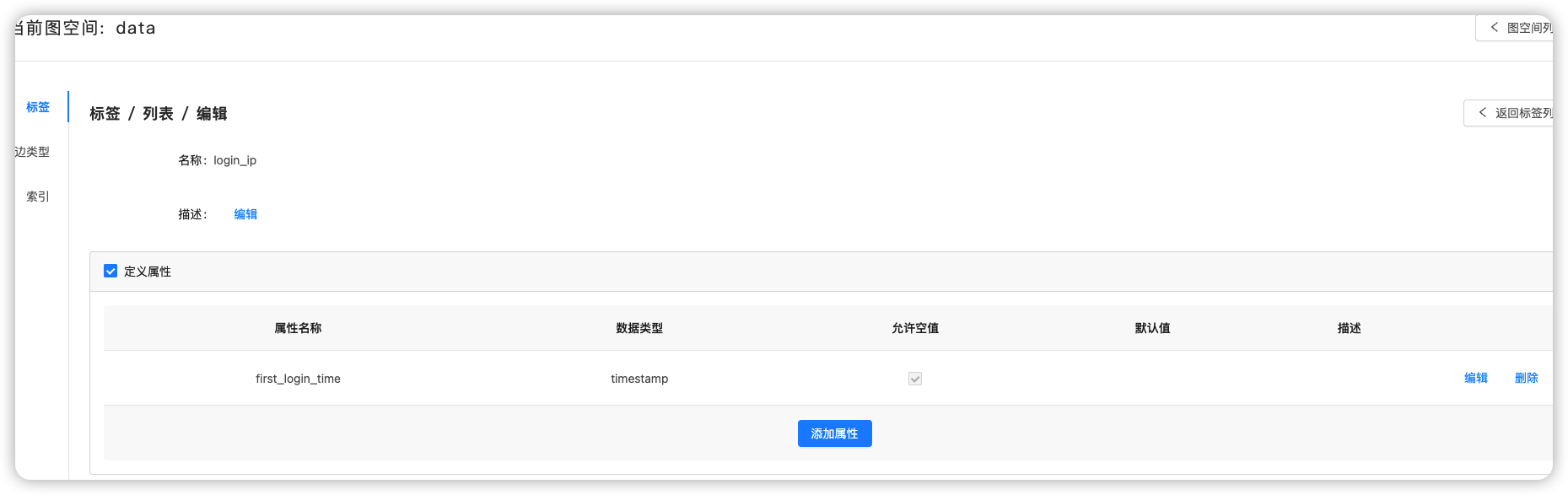
数据(csv格式):
配置
version: v2
description: example
removeTempFiles: false
clientSettings:
retry: 3
concurrency: 2 # number of graph clients
channelBufferSize: 1
space: data
connection:
user: root
password: nebula
address: 127.0.0.1:9669
postStart:
commands: |
afterPeriod: 1s
preStop:
commands: |
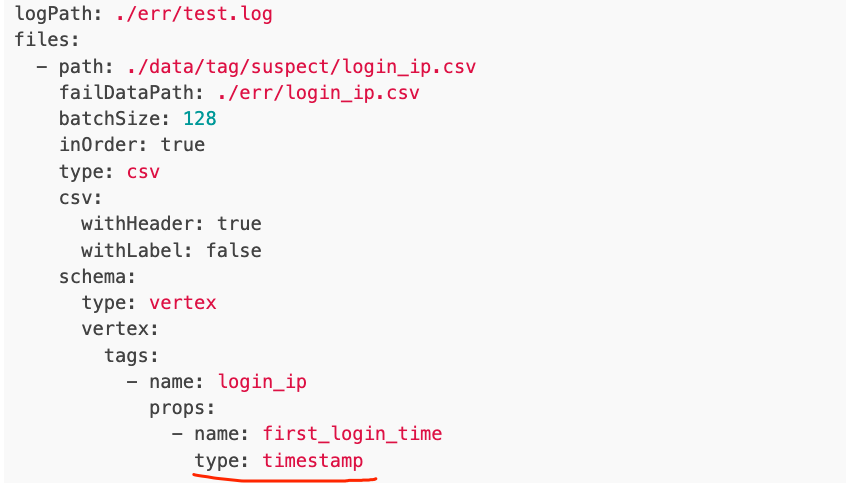
logPath: ./err/test.log
files:
- path: ./data/tag/suspect/login_ip.csv
failDataPath: ./err/login_ip.csv
batchSize: 128
inOrder: true
type: csv
csv:
withHeader: true
withLabel: false
schema:
type: vertex
vertex:
tags:
- name: login_ip
props:
- name: first_login_time
type: timestamp
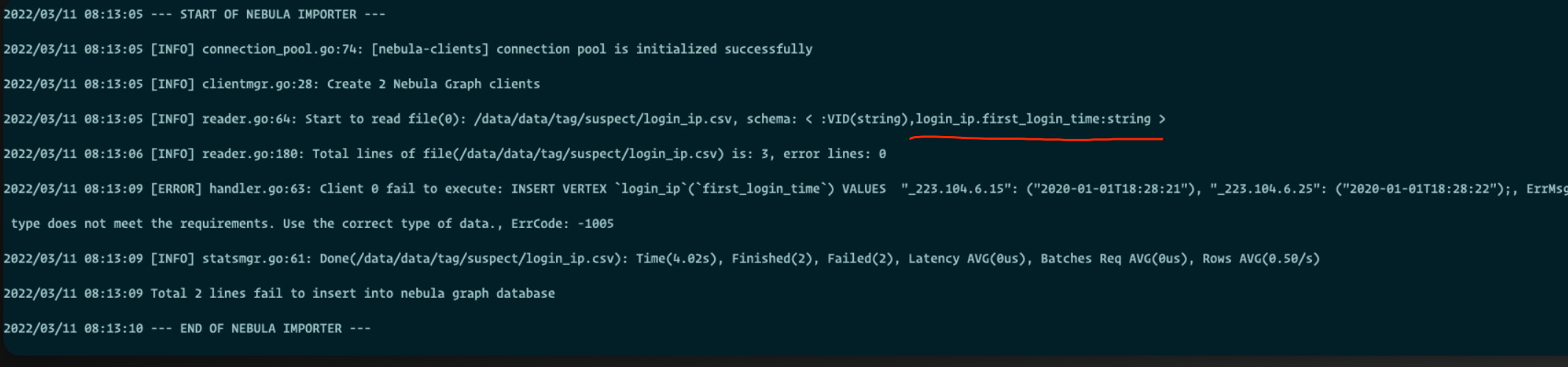
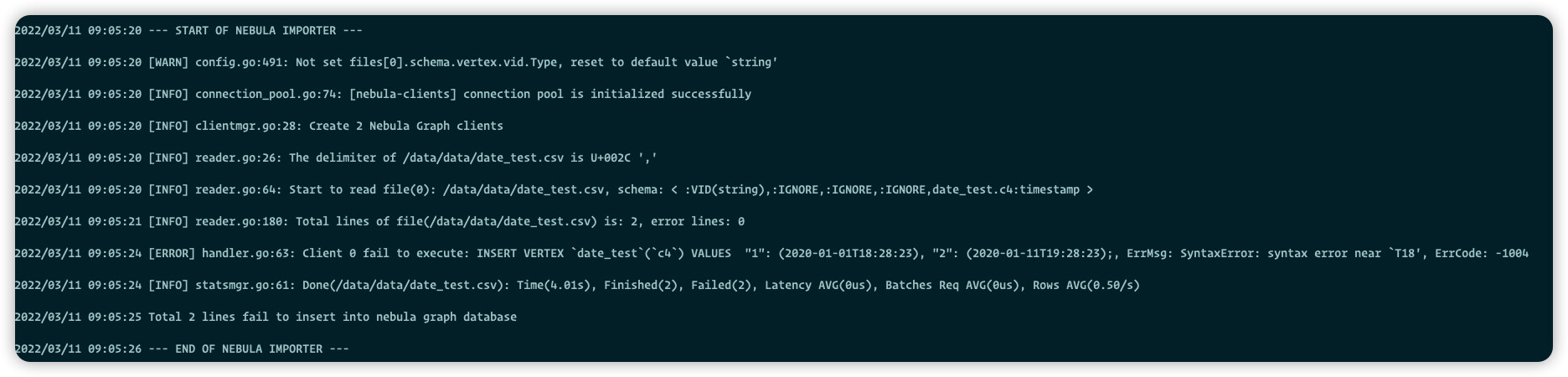
导入日志:
steam
2
这里是 string 类型的,但是你配置文件里是 timestamp 类型的,

你确认下?
换成官方的数据和配置
https://github.com/vesoft-inc/nebula-importer/blob/master/examples/v2/date_test.csv
version: v2
description: example
removeTempFiles: false
clientSettings:
retry: 3
concurrency: 2 # number of graph clients
channelBufferSize: 1
space: importer_test
connection:
user: root
password: nebula
address: 127.0.0.1:9669
postStart:
commands: |
afterPeriod: 1s
preStop:
commands: |
logPath: ./err/test.log
files:
- path: ./data/date_test.csv
failDataPath: ./err/date_test.csv
batchSize: 2
inOrder: true
type: csv
csv:
withHeader: false
withLabel: false
delimiter: ","
schema:
type: vertex
vertex:
vid:
index: 0
tags:
- name: date_test
props:
- name: c4
type: timestamp
index: 4
有新的报错
v2
docker run --rm -ti \
--network=host \
-v /media/seven/data/clue_associate_analysis/nebula_importer/:/data \
vesoft/nebula-importer:v2 \
--config /data/test_v1.yaml
@HarrisChu @steam 你们生成csv的时候,是怎么定义类型的
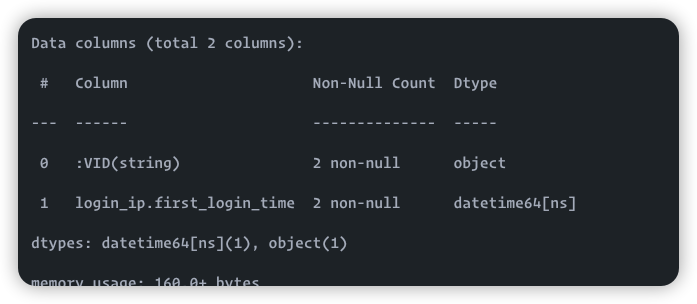
我更改了类型,还是读出为string
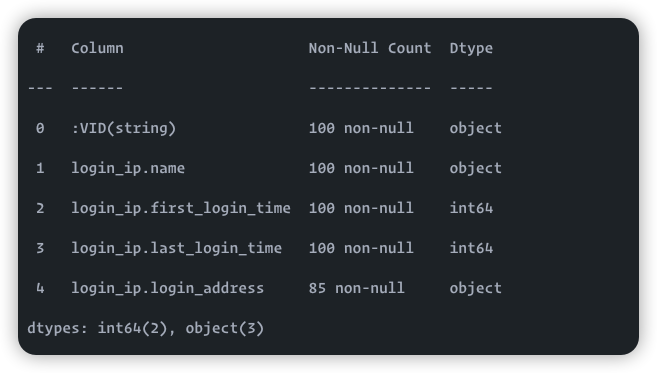
2022/03/11 09:35:23 [INFO] reader.go:64: Start to read file(0): /data/data/tag/suspect/login_ip.csv, schema: < :VID(string),login_ip.name:string,login_ip.first_login_time:string,login_ip.last_login_time:string,login_ip.login_address:strin
g >
v2 改成 v2.6.0 ,v2 是老的 2.0 的。
@steam 记个 issue 吧,每次发布 v2.x 最新版,也更新一下 v2 的镜像。
2 个赞
换成v2.6.0 官方的数据可以跑通了,谢谢
但是我有个问题就是怎样生成的csv是timestamp类型的?
csv 里没有 timestamp 类型一说,文件里都是 string。
如果 importer 里配置了类型是 timestamp,插入到 nebula 中时,相当于 timestamp(“2021-03-11T08:00:00”),然后服务端转成 timestamp.
@HarrisChu 但是你看我的数据,我用importer 读进去是字符串啊,官方的读进去是timestamp
官方的
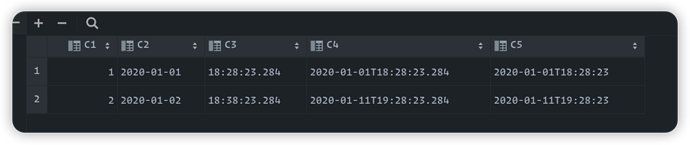
我的
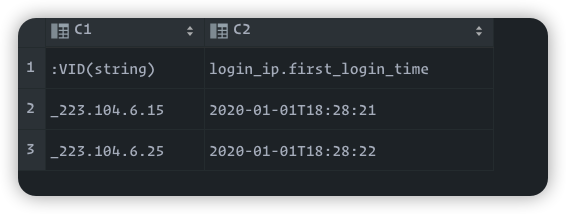
测试nebula importer 读取数据类型
配置文件一:
files:
- path: ./data/date_test-1.csv
failDataPath: ./err/date_test.csv
batchSize: 2
inOrder: true
type: csv
csv:
withHeader: false
withLabel: false
delimiter: ","
schema:
type: vertex
vertex:
tags:
- name: login_ip
props:
- name: name
type: string
- name: first_login_time
type: timestamp
- name: last_login_time
type: timestamp
- name: login_address
type: string
nebula importer 日志
2022/03/15 02:57:55 [INFO] reader.go:64: Start to read file(0): /data/data/date_test-1.csv, schema: < :VID(string),login_ip.name:string,login_ip.first_login_time:timestamp,login_ip.last_login_time:timestamp,login_ip.login_address:string >
2022/03/15 02:57:55 [INFO] reader.go:180: Total lines of file(/data/data/date_test-1.csv) is: 2, error lines: 0
配置文件二:
files:
- path: ./data/date_test-1.csv
failDataPath: ./err/date_test.csv
batchSize: 2
inOrder: true
type: csv
csv:
withHeader: true
withLabel: false
delimiter: ","
schema:
type: vertex
vertex:
tags:
- name: login_ip
props:
- name: name
type: string
- name: first_login_time
type: timestamp
- name: last_login_time
type: timestamp
- name: login_address
type: string
nebula importer 日志
2022/03/15 03:01:41 [INFO] reader.go:64: Start to read file(0): /data/data/date_test-1.csv, schema: < :VID(string),login_ip.name:string,login_ip.first_login_time:string,login_ip.last_login_time:string,login_ip.login_address:string >
2022/03/15 03:01:41 [INFO] reader.go:180: Total lines of file(/data/data/date_test-1.csv) is: 2, error lines: 0
不管数据是否导入成功,只是测试数据读取的时候获取的类型
只是将csv的withHeader设置为true,nebula importer 读进去的数据类型就不一样
@steam @HarrisChu
1 个赞
system
关闭
15
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。