[s-user@~]$ free -g
total used free shared buff/cache available
Mem: 123 71 11 0 40 51
Swap: 0 0 0
来,补充下 Nebula 版本号,然后描述了下,你做了什么操作。顺便。。老哥你是不是 storage 也写错成 stroge,- -,我记得好像改过一次标题是这个错别字。
nebula 2.6.1 是的是storage
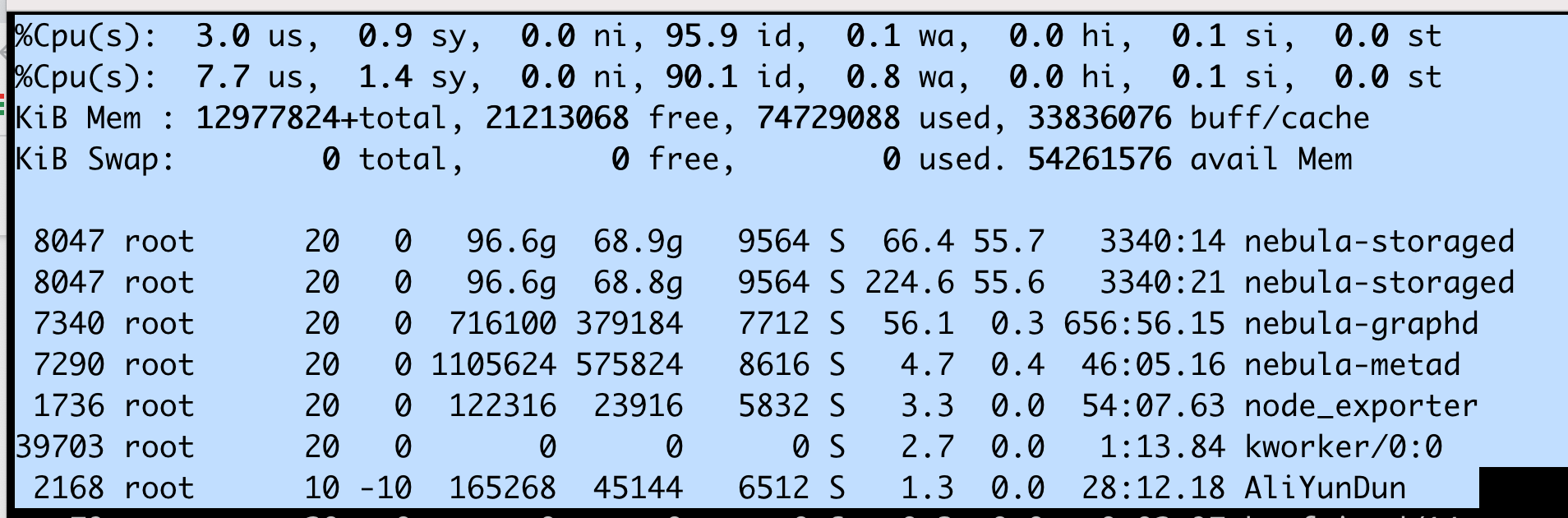
block cache设置的多大,具体做了什么操作,单纯的说storage占用内存高别人很难给到帮助
–rocksdb_block_cache=4096
老哥,你记得补充下你做了什么操作。
spark数据导入,--enable_partitioned_index_filter=true 设成了true也是很高
所以是,用 Spark 导入数据的时候,发现 nebula- storage 占用内存率非常高对吗?
是的,现在设置参数重启一样高,根据之前论坛上说的默认值我也去掉了,还是很高,这个相关工具检测哪个用到内存最高吗

jeprof看起来有读数据啊 compaction开着还是关掉了 另外关注下是刚启动就很大 还是导入过程中变大的
谢谢已解决
请问能分享下解决的方法么?
通过jeprof定位到索引和过滤块,调整max_open_files、cache_index_and_filter_blocks 解决,但会产生性能问题,发现默认块block_size为8k太小,准备调整这个来减少索引内存,过滤器换成Ribbon Filter (准备测试中)
2 个赞
太棒了 ,期待您的更多成果和分享
,期待您的更多成果和分享
期待写个文章分享下具体的分析过程和思路
2 个赞
可以的,这个提交到哪
1 个赞

话说你们数据量有多大?开了rocksdb的partition_index_filter之后 应该只有第一层的index/filter在内存诶?