- nebula 版本:3.0.0
- spark 版本:2.4.1
- scala 版本:2.11.8
- 部署方式:分布式
- 安装方式:RPM
- 是否为线上版本:Y
直接提交算法包时报错
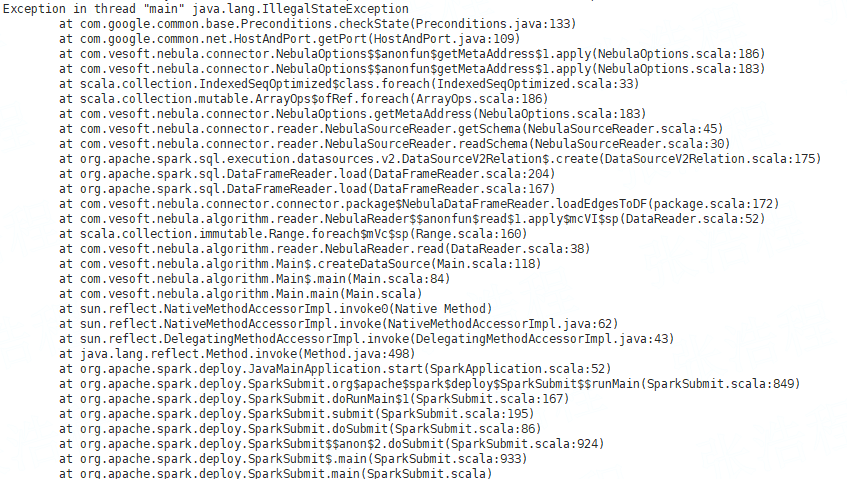
使用配置:
{
spark: {
app: {
name: LPA
partitionNum:100
}
master:local
}
data: {
source: nebula
sink: csv
hasWeight: false
}
nebula: {
read: {
metaAddress: "192.168.20.30:9559,192.168.20.69:9559,192.168.20.79:9559"
space: Twitter2010
labels: ["edge"]
weightCols: ["start_year"]
}
write:{
graphAddress: "192.168.20.30:9669,192.168.20.69:9669,192.168.20.79:9669"
metaAddress: "192.168.20.30:9559,192.168.20.69:9559,192.168.20.79:9559"
user:root
pswd:nebula
space:Twitter2010
tag:pagerank
type:insert
}
}
local: {
read:{
filePath: "file:///data16/zhc/spark/algo/Twitter-2010-kn-sample.csv"
# srcId column
srcId:"_c0"
# dstId column
dstId:"_c1"
# weight column
#weight: "col3"
# if csv file has header
header: false
# csv file's delimiter
delimiter:","
}
write:{
resultPath:/data16/zhc/spark/algo/result
}
}
algorithm: {
executeAlgo: pagerank
pagerank: {
maxIter: 20
resetProb: 0.85 # default 0.15
}
}
}

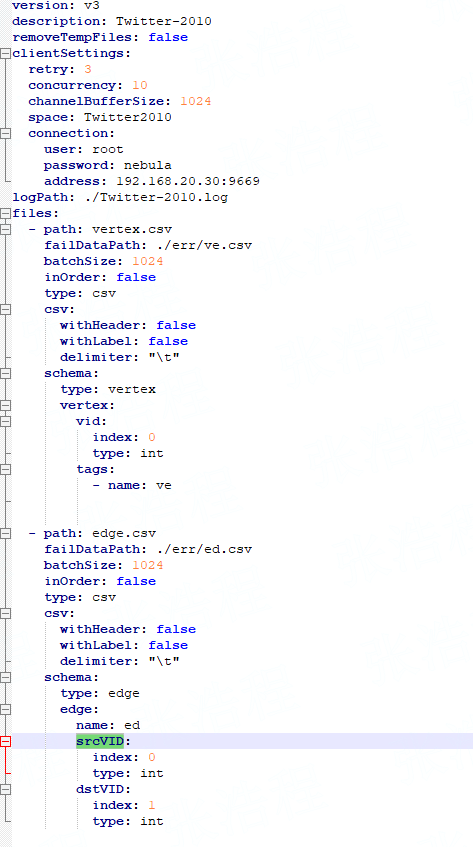
 原来如此。所以新的问题是你说的配置跑 pagerank 吗?
原来如此。所以新的问题是你说的配置跑 pagerank 吗? 我提交给文档同学修复了,你捉到的 bug 被我收录到我们的捉虫活动里了哈
我提交给文档同学修复了,你捉到的 bug 被我收录到我们的捉虫活动里了哈 