- nebula 版本:docker pull vesoft/nebula-graph:latest
- 部署方式:单机 docker run --rm -ti vesoft/nebula-graph:latest bash
- 安装方式:Docker
- 是否为线上版本:Y
- 硬件信息
- 内存 8G
- CPU 4core
- 问题描述
以上是单机启动graph服务的方式
1. 通过rpm安装studio, 版本是nebula-graph-studio-3.2.3.x86_64.rpm之后, 通过访问页面是OK的
但是在连接上会报错, Cannot read properties of null (reading ‘code’)
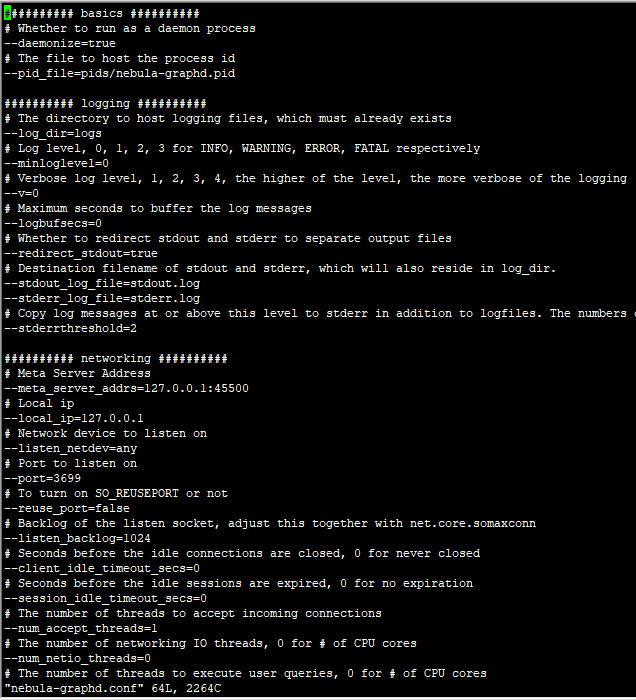
页面配置host: 部署服务的ip:3699(这个端口号是docker拉取最新版本的默认nebula-graphd.conf配置)
用户名/密码:root/nebula
Nebula 的最新镜像拉取命令是 docker pull vesoft/nebula-graphd:latest 哈,你少了一个 d
这个应该是 v1.x 的版本的 Nebula,![]() 你可以把整个配置文件和 Studio 的配置贴一下吗?
你可以把整个配置文件和 Studio 的配置贴一下吗?
好的 我重新拉一下 那估计是我拉取的版本不对 少了一个d
嗯嗯,先试试

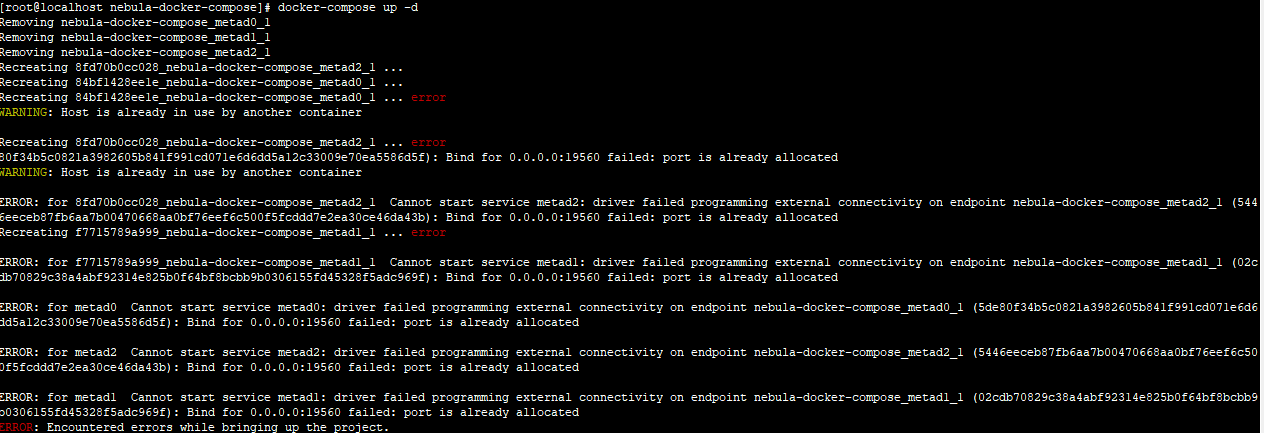
换一种方式使用docker-compose安装报如下错误:
在此, 里边的yaml配置文件已将对应服务的ports设置为固定映射;
而且已经通过docker添加name为nebula-net的network
把配置文件贴一下,然后 meta 的这个端口号你映射过吗?还有你配置了几个副本?
我直接给您贴配置文件吧vi docker-compose.yaml
version: '3.4'
services:
metad0:
image: vesoft/nebula-metad:v2.6.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559
- --local_ip=metad0
- --ws_ip=metad0
- --port=9559
- --ws_http_port=19559
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=0
healthcheck:
test: ["CMD", "curl", "-sf", "http://metad0:19559/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 9559
- 19559
- 19560
volumes:
- ./data/meta0:/data/meta
- ./logs/meta0:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
storaged0:
image: vesoft/nebula-storaged:v2.6.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559
- --local_ip=storaged0
- --ws_ip=storaged0
- --port=9779
- --ws_http_port=19779
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
healthcheck:
test: ["CMD", "curl", "-sf", "http://storaged0:19779/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 9779
- 19779
- 19780
volumes:
- ./data/storage0:/data/storage
- ./logs/storage0:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
graphd:
image: vesoft/nebula-graphd:v2.6.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559
- --port=9669
- --local_ip=graphd
- --ws_ip=graphd
- --ws_http_port=19669
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- storaged0
healthcheck:
test: ["CMD", "curl", "-sf", "http://graphd:19669/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 9669:9669
- 19669
- 19670
volumes:
- ./logs/graph:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
networks:
nebula-net:
之前起的容器占用了端口
我用docker-compose down了所有的服务再启动也是同样的报错呢
再重启也会报错,可能是因为你部署了多套 Nebula,都用了 9669 端口,你试试最新的那个配置文件把端口号改下,看看会不会还报错。

请问是不是把框里的端口号映射出来吗 还是直接把框里的端口号改了呀
箭头对应的端口号还要改吗
对,把 9559 改了,所有的 9559(同一个配置文件)
您看下我改之后的配置哪里不对吗?还是报一样的错误呢
version: '3.4'
services:
metad0:
image: vesoft/nebula-metad:v2.0.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9859
- --local_ip=metad0
- --ws_ip=metad0
- --port=9859
- --ws_http_port=19559
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=0
healthcheck:
test: ["CMD", "curl", "-sf", "http://metad0:19559/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 9859
- 19559
- 19560
volumes:
- ./data/meta0:/data/meta
- ./logs/meta0:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
storaged0:
image: vesoft/nebula-storaged:v2.0.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9859
- --local_ip=storaged0
- --ws_ip=storaged0
- --port=9879
- --ws_http_port=19779
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
healthcheck:
test: ["CMD", "curl", "-sf", "http://storaged0:19779/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 9879
- 19779
- 19780
volumes:
- ./data/storage0:/data/storage
- ./logs/storage0:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
graphd:
image: vesoft/nebula-graphd:v2.0.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9859
- --port=9869
- --ws_ip=graphd
- --ws_http_port=19669
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
healthcheck:
test: ["CMD", "curl", "-sf", "http://graphd:19669/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 9869
- 19669
- 19670
volumes:
- ./logs/graph:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
networks:
nebula-net:
external: true
- -,你的 Docker 环境也太混乱了,上面的配置文件是 v2.0 的,在上面的是 v2.6 的,还有 v3.0 的镜像以及 v1.x 的。我建议要不你吧所有镜像都清理下,然后按照 使用 Docker Compose 部署 - Nebula Graph Database 手册 来操作下吧。环境太乱了,记得清理干净镜像。
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。