我用3台机器部署的集群,3台机器的配置都完成后然后3个机器分别启动了服务(./nebula.service start all)。然后查询status 都是好的,查询show hosts 都是online的状态,然后等了一会儿我再查的时候一台机器就是offline了,其他两个还是正常的,请问是怎么回事呢
看下 offline 那台机器的服务日志
我看了graph和meta都是online,只有storage是下线的,我看的storage的日志显示Receive response about askForVote from “xx.xxx.xx.xx:xx”, error code is -6,然后下面还有 bytesWritten: 3690, expected:37496, error:connection timed out
看下你 storage 的配置,还有你用的 Nebula 版本号多少。
看起来是raft选举出了问题,可以看看raftpart的代码 
版本号是2.0.1的,版本3的因为之前导入有问题,就没有用3的。还有storage的日志下最后写有device has no space。是不是因为这个原因呢
- -。设备磁盘空间满了,那个报错信息。
我清理了一些文件,然后这个机器的storage还是起不来(用的./nebula.service start all),而且data下边的storage里边的数据占了很大空间,可是边和点一共才5000万左右。查了日志什么都没有,怎么办呢,在线等大神解答
等 4 个小时之后呢,wal 文件可能占用了部分的空间,一般 wal 文件会在 4 个小时之后被清理掉
我修改为半小时了,现在的问题是我看storage日志上面就显示一条日制是storage path should not empty是怎么回事呢,我也没改什么配置啊
截几幅图吧
- 问题节点的nebula-storaged.INFO日志
- storage的配置文件
- df -h磁盘空间信息
1:就这一行
![]()
2: 我就修改了log_dir和wal_ttl,其他就是ip按照文档改了下因为ip不方便就没有截图,其他东西没有改
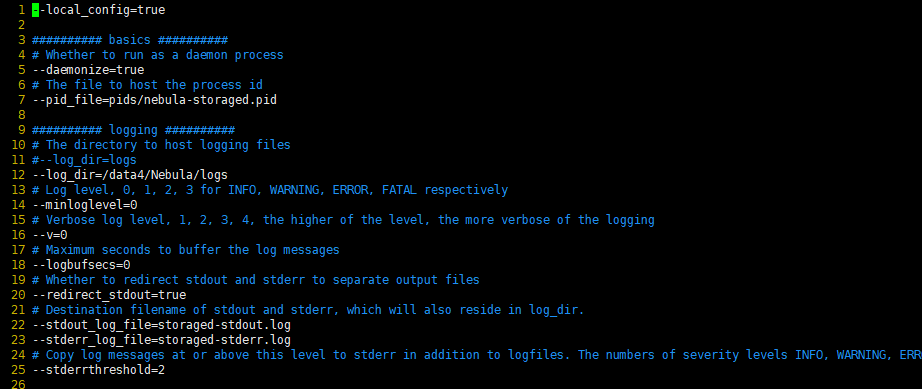
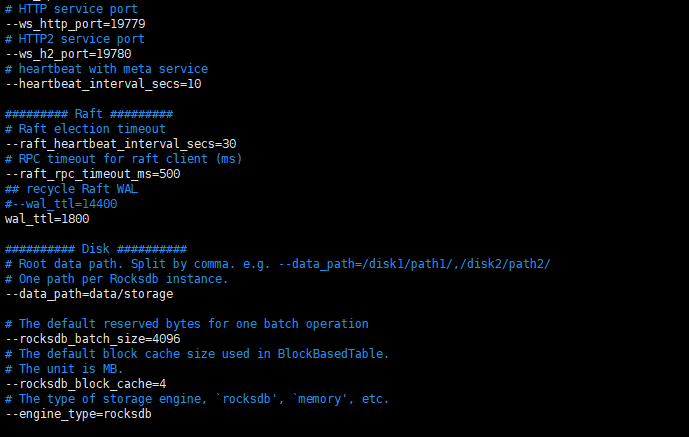
3: 因为之前的空间不足,我把整个nebula移到了这个data4下边,所以大小应该是没有问题
![]()
另外两个服务meta和graph重启了吗
重启了,没用,不知道是怎么回事。我又重新在卸载下载了graph,现在可以了。
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。