
每周五 Nebula 为你播报每周看点,每周看点由固定模块:产品动态、社区问答、推荐阅读,和随机模块:本周大事件构成。
本周产品动态颇丰,社区用户 @wuxiaobai24 贡献的 pr 让你能通过 std::vector<Value>({"Hello Nebula Graph"}) 提取当中的子字符串;pr #4095 则在降低路径消耗的内存消耗量之外,还支持了路径算子的并发执行…在社区问答方面,你将了解版本升级以及 replica_factor 设置。
本周大事件
Nebula 首届征文活动上线
社区用户繁凡问过:为什么要办这个活动呢?是的,为什么呢?因为你是 Nebula 的用户,没有人比你更清楚你是怎么用上它的、Nebula 如何使用、怎么用会获得更好的性能,它又是如何帮你解决问题的…只要你对 Nebula 有兴趣、喜钻研,我们都无比欢迎你来书写自己和 Nebula 有趣的故事!
此外,本次活动除了常见的数码产品(机械键盘、无线充、运动手环)之外,社区用户 Johntill 建议的赠送数据库、领域技术书籍也在获奖用户的查收礼包当中。(细细查看下图能看到书籍们闪烁的智慧之光)
产品动态
本周 Nebula 主要有这些产品动态:
- 社区
wuxiaobai24贡献 |支持从字符串中提取出匹配正则表达式的子字符串,标签:数据提取,pr 参见:https://github.com/vesoft-inc/nebula/pull/4098 - 支持多并发执行路径算子,标签:
优化,pr 参见:https://github.com/vesoft-inc/nebula/pull/4095 - 减少路径内存使用,标签:
优化,pr 参见:https://github.com/vesoft-inc/nebula/pull/4095 - 修复词法分析里科学记数法匹配错误导致的语法报错,标签:
bugfix,pr 参见:https://github.com/vesoft-inc/nebula/pull/4136 - 当节点存在多条路径,某条数据路径对应磁盘故障时,不再需要重建整个节点,标签:
故障恢复,pr 参见:https://github.com/vesoft-inc/nebula/pull/4131 - 存算合并版本支持自动
ADD HOSTS,可在配置文件中通过--add_local_host来配置服务,标签:优化,pr 参见:https://github.com/vesoft-inc/nebula/pull/4129 - 修复
WHERE子句同时引用多MATCH变量结果显示不正确的问题,标签:bugfix,pr 参见:https://github.com/vesoft-inc/nebula/pull/4143
社区问答
Pick of the Week 每周会从官方论坛、知乎、微信群、微信公众号及开源中国等渠道精选问题同你分享。
主题分享
本周分享的主题是【升级问题】,由社区用户 Jun69 提出,Nebula 研发同学负责解答,原帖出自 Nebula 论坛:https://discuss.nebula-graph.com.cn/t/topic/8296。
Jun69:想把生产环境的 Nebula 数据库升级至 3.0.2,存在以下问题:
1、nebula 2.5.0 就开始支持内存水位配置,这个参数是否可自由配置,如果自己配可以怎么配置?如果不能配默认是多少?当前一个机器上部署了 graphd 和 storaged 两个服务,担心相互影响。
2、nebula 2.5.0 就能支持慢查询终止,是超过慢查询的时间阈值就直接返回错误,服务端有参数配置决定是否终止。
3、在升级至 3.0.2 有个要求,剩余空间必须是当前数据容量的 3 倍,当时的情况是数据大小为 550 G,磁盘空间为 1.8 T。在不删除数据的情况下能够有手段升级?(个人理解,当前升级没有自动备份数据,就算升级至新版本有数据膨胀,也不需要三倍的剩余空间)官方文档上写索引不提高加速查询,仅支持定位。那我是不是只要每个 TAG 随便建一个索引就好,我不太理解为什么不能提高性能?
Nebula:既然你知道内存水位管理,可以看下文档啊,文档里面有详细的解释说明的,这个是可配置的:在 graph 服务配置中指定 system_memory_high_watermark_ratio 大小即可;终止慢查询的话,可以通过 nGQL 语句 KILL QUERY 终止正在执行的查询;至于升级,从 2.x 升级到 3.x,是原地升级的,就是直接改你原来的数据,所以:
- 为了防止升级失败,最好你手动备份一下数据。 1 倍。
- 升级过程中,会复制 wal。如果你集群最近没有写入数据,wal 会自动清理,这个就不会很大。
- 升级过程中,会额外的增加一部分数据,这个数据和你有多少个点有关系。 1 亿点,vid type 是 int64 大约为 1.2 G。
综上,需要手动备份额外的 550G 和预留 wal 和增加的数据,不需要 3 倍。
Nebula 进阶技能
本周的 Nebula 进阶技能分享一个【replica_factor 设置】,来源于官方文档:https://docs.nebula-graph.com.cn/3.0.2/20.appendix/0.FAQ/#create_spacereplica_factor_2。
Storage 服务使用 Raft 协议(多数表决),为保证可用性,要求出故障的副本数量不能达到一半。
当机器数量为 1 时,replica_factor 只能设置为 1。
当机器数量足够时,如果 replica_factor=2 ,当其中一个副本故障时,就会导致系统无法正常工作;如果 replica_factor=4,只能有一个副本可以出现故障,这和 replica_factor=3 是一样。以此类推,所以 replica_factor 设置为奇数即可。
建议在生产环境中设置 replica_factor=3,测试环境中设置 replica_factor=1,不要使用偶数。
推荐阅读
- 《BIGO 的数据管理与应用实践》
- 推荐理由:数据治理能提高企业数据的安全性和易用性,在本文中来自 Bigo 数据中台的蒋涉权讲述了他搭建元数据管理平台用来解决数据缺少统一标准、缺少数据联系、权限管控颗粒度粗的问题。
星云·小剧场
为什么给图数据库取名 Nebula?
Nebula 是星云的意思,很大嘛,也是漫威宇宙里面漂亮的星云小姐姐。对了,Nebula 的发音是:[ˈnɛbjələ]
本文星云图讲解–《NGC 6369》
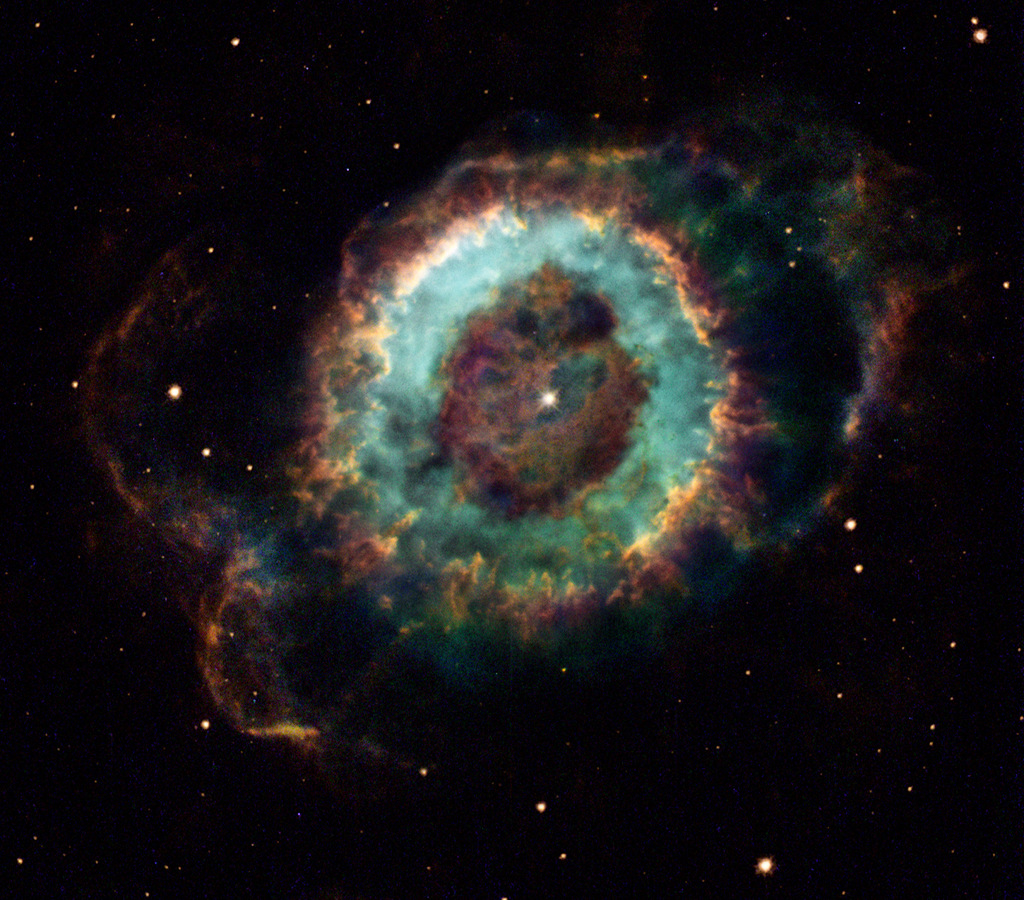
形似幽灵的 NGC 6369,是夜空中的一团暗淡幻影,以小幽灵星云的称号广为周知。它是十八世纪天文学家威廉.赫歇尔爵士,在用望远镜探索蛇夫座时所发现的。
影像提供与版权:Jeremiah Roth
作者与编辑:Robert Nemiroff (MTU) & Jerry Bonnell (UMCP)
这是一个从 https://nebula-graph.com.cn/posts/nebula-graph-weekly-pickup-2022-04-15/ 下的原始话题分离的讨论话题