- nebula 版本:2.6.1
- 部署方式:分布式
- 安装方式:源码编译
- 是否为线上版本:Y
- 硬件信息
- 磁盘 1.5T
- CPU、内存信息 32C128G
- 查询客户端的配置为 4C8G
- 问题的具体描述
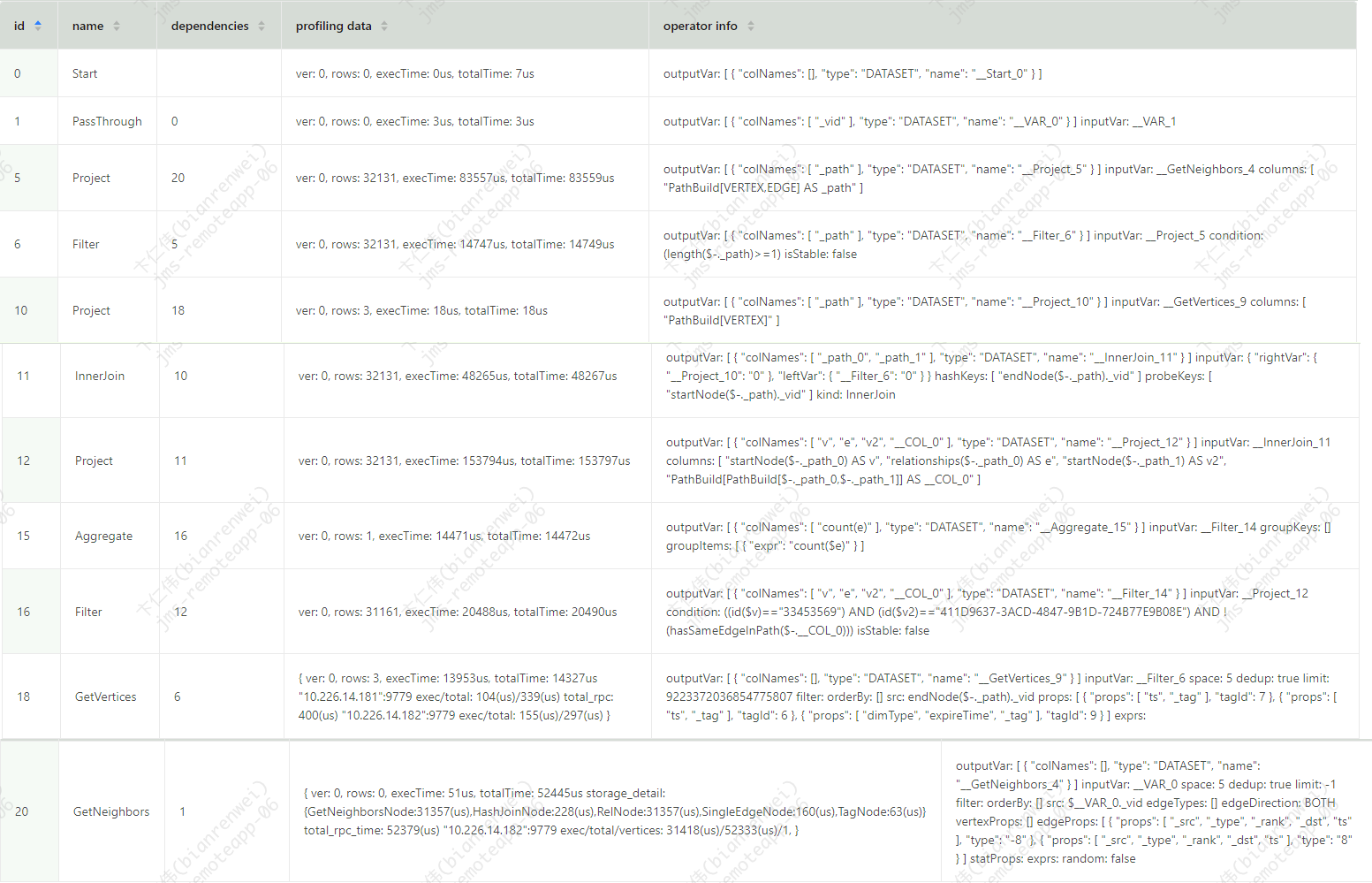
测试逻辑
查询指定的两个点之间的明细边关系数量
查询语句
MATCH (v)-[e:useridtodeviceid1]-(v2)
where id(v) == '1588’
and id(v2) == '411*********08E’
RETURN count(e);
测试结果:
边关系数据量3W
平均响应时间在2.6秒, 95线 3.5秒 QPS:40 客户端服务的CPU 利用率20%
nebula机器的cpu占25%左右
边关系数据量1K
平均响应时间在111毫秒, 95线 144毫秒 QPS: 950 客户端服务的cpu利用率30%
nebula机器的cpu占23%左右
边关系数据量300
平均响应时间在38毫秒, 95线 49毫秒 QPS: 2780,客户端服务的cpu利用率 60% nebula的cpu占30%左右
边关系数据量2
平均响应时间在17毫秒, 95线 22毫秒 QPS 达到5300 客户端服务的cpu利用率达到100%
nebula的cpu占20%左右
服务的响应速度和吞吐量随着明细边数量的增加而下降,边数量达到1千以上时平均响应时间突破100ms。边为个位数时,平均响应时间十几毫秒。并且数量的统计没办法做到超过多少个直接返回。
问题:
如何提升这样统计数据的查询效率?