有两个疑问:
1、VID长度为200会影响性能吗?
2、为后期扩展想长度留大一些,那么在内容长度为100的情况下,使用FIXED_STRING(100)和FIXED_STRING(200)在存储空间和性能上有区别吗?
谢谢!
有两个疑问:
1、VID长度为200会影响性能吗?
2、为后期扩展想长度留大一些,那么在内容长度为100的情况下,使用FIXED_STRING(100)和FIXED_STRING(200)在存储空间和性能上有区别吗?
谢谢!
首先抛一个结论,VID的长度是会影响性能的。
如果个别记录的主键特别长,但绝大多数记录的主键都很短的情况,不要将FIXED_STRING()的N设置成超大,这会浪费大量内存和硬盘,也会降低性能。建议此时可以通过BASE64,MD5,hash 编码加拼接的方式来生成,以此来平衡VID的长度,以至于不会使个别主键过长。
谢谢,第二个问题呢?
使用FIXED_STRING(100)和FIXED_STRING(200)在存储空间和性能上是有区别的。
假定你设定的FIXED_STRING为200,即使你使用的长度都小于100,系统仍然会将其长度补齐为200,所以FIXED_STRING的长度设定直接影响了存储空间和性能。
你好,论坛终于恢复了,昨天一直打不开,有紧急事情请教:
搭建了最新集群:三台32核64G机器,增强ssd,3个服务都在每台机器上有,安装最版3.1.0;
使用exchange导入了大概1亿个点,1.4亿条边,导入之后手动执行compact并完成:
开始发现match语句极度低效,测试环境更低版本,更低配置的似乎还更快:
match p=(v0:t_uid)-[*2]-(v2:t_uid)
where id(v0) == “5efd66d2103509d80099e4a5” and id(v2) == “5c6d5c6655af547334feba5f”
// where id(v0) == “5f94ee4ba0378d0001ae7ba1” and id(v2) == “61050cbce5bb26000143b59e”
return p;
边长度是2或者2…4,发现第一组id查询10ms级别,第二组id查询20s+,4个id都是真实存在的,点和边本身也有建索引的,也尝试过重新rebuild,执行计划如下:
谢谢!定位下来,确实中间有个超级节点,把这个节点处理掉就正常了!
另外有个match语句:
profile match p=(v0:t_uid)-[*2…4]-(v2:t_uid)
where id(v0) == ‘62315f8db89b68000160d76a’ and id(v2) == ‘623308f9560c0f00018befa3’ and v0 != v2
return count(p);
两端id *2 路径内分别有1000左右的path,这个查询耗时20s了,根据官方文档说超过1万度才算超级节点?
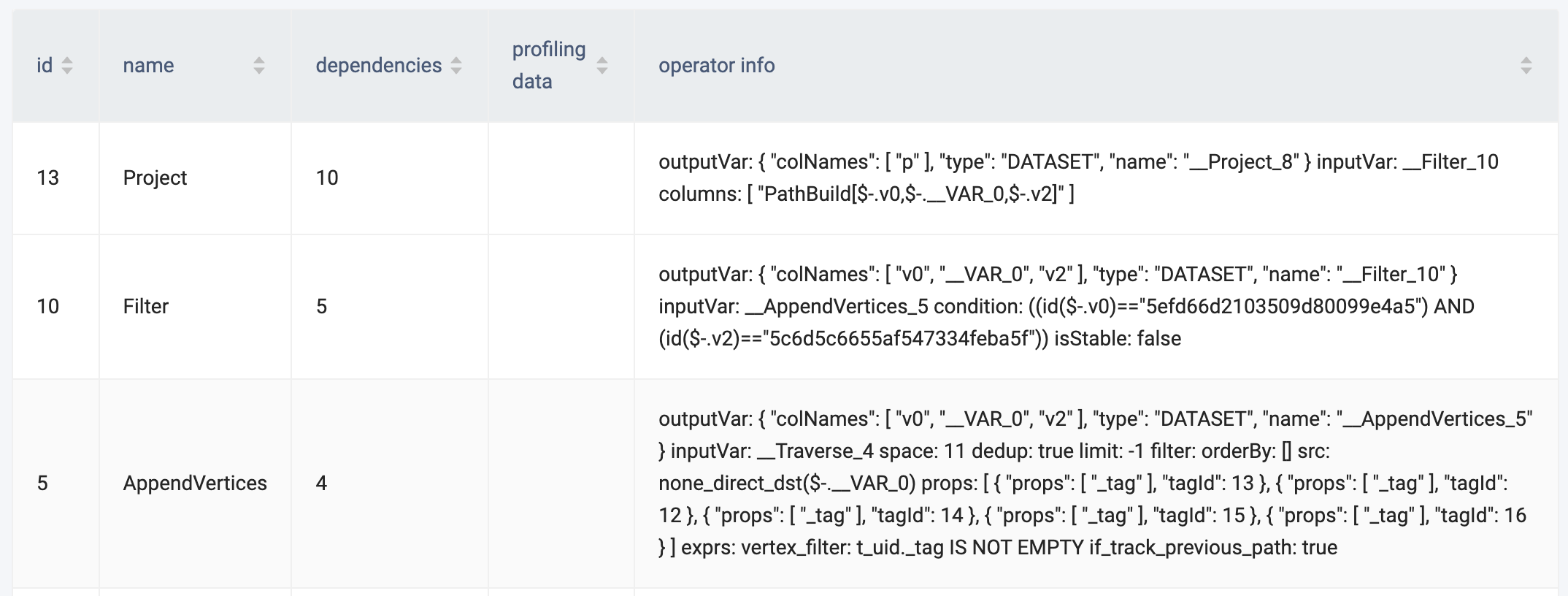
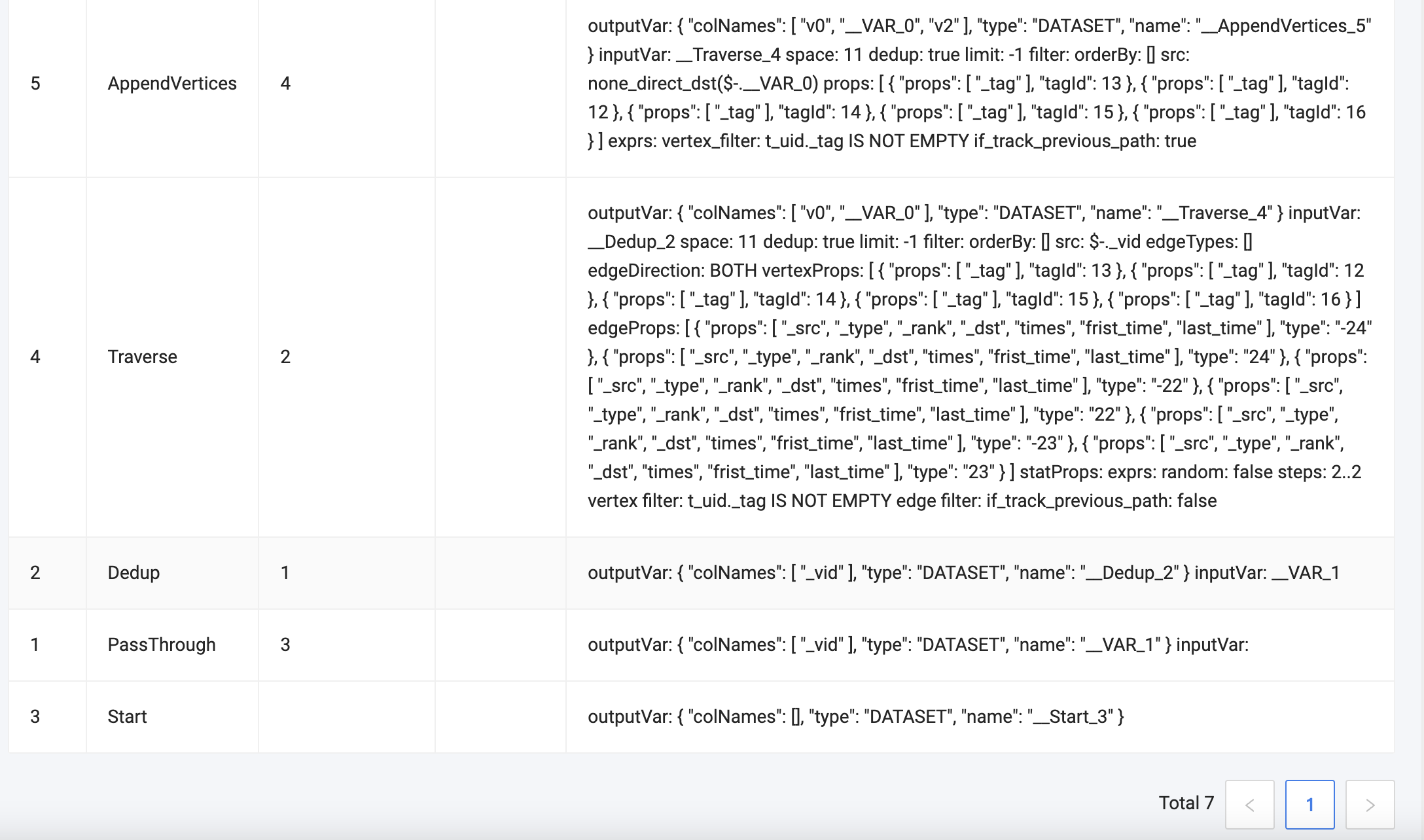
profile还不太会看:
如楼上
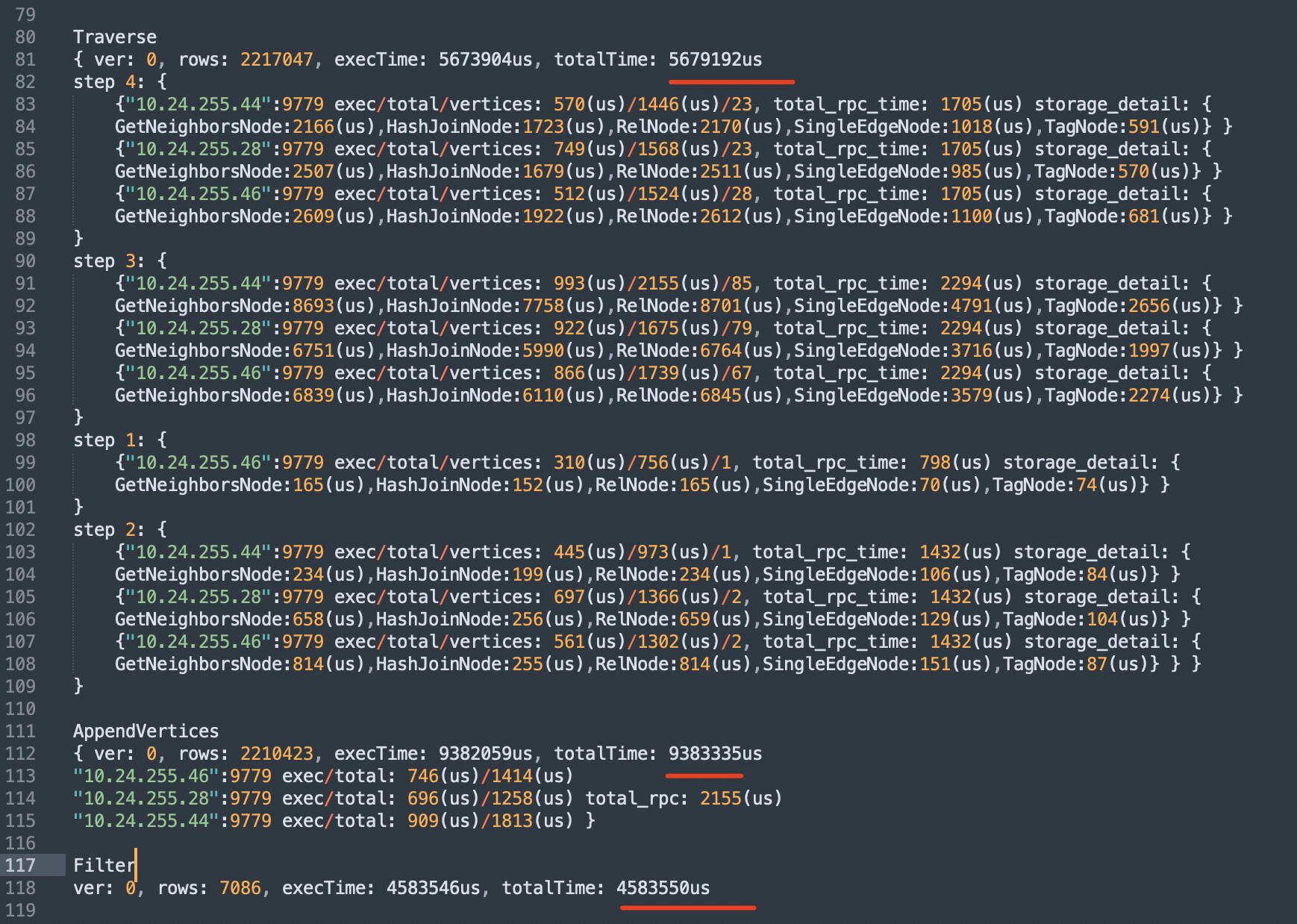
Traverse 中的 rows 是 2217047,这个算子里内部 会构造路径,是计算密集型操作,会占用很多时间
AppendVertices 和 traverse的情况类似
Filer 算子 做过滤 200多万数据消耗了 4s
请问您的机器的硬件配置是什么
机器配置在帖子前面几楼有贴呢,辛苦往上翻翻。
另外提供一个信息,find ALL path查询同样参数,30ms以内返回,打算用这个语句呢
FIND ALL PATH FROM “62315f8db89b68000160d76a” TO “623308f9560c0f00018befa3” OVER * BIDIRECT UPTO 4 STEPS YIELD path AS p
| YIELD count($-.p) as paths
嗯嗯,是的呢
嗯, 现在 traverse、appendVertices 和 filter 都是单线程算子, 没有将空闲 CPU核心 完全利用起来。 这个在持续改进当中。
感谢回复!
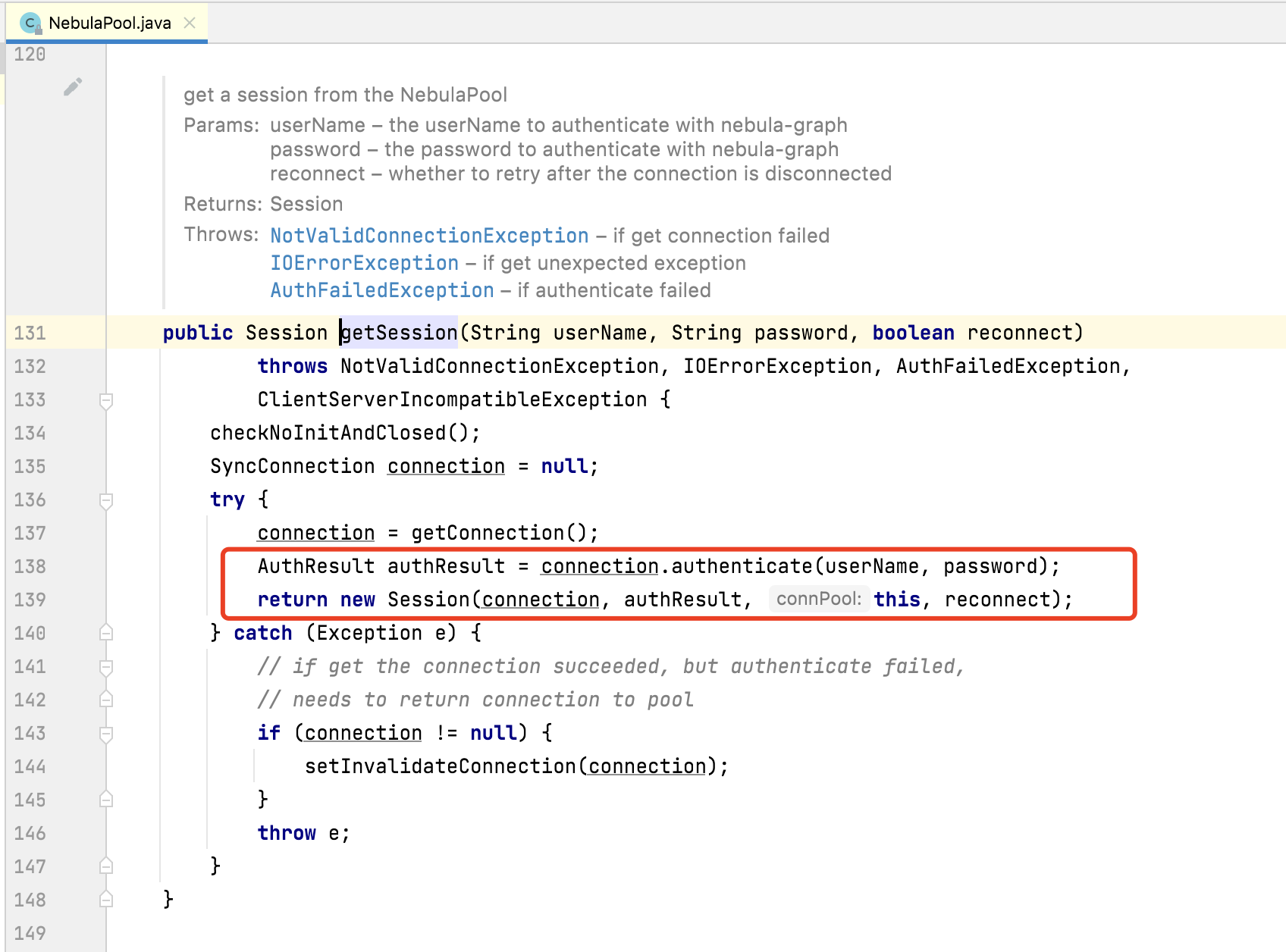
追加一个问题,我在使用java api 3.0版本,代码粗鲁看了,发现:
nebulaPool.getSession方法每次都传递用户名,密码,从代码来看getSession 每次都需要进行 用户名密码的鉴权吗?
非常疑惑,登录态不是复用吗,这么做岂不是性能非常低?
你的疑惑是对的哈,建议的在线系统使用的做法是自己维护一个 session 的池子,用的时候按需取,用过了放回去,避免 authentication 开销哈。
了解了,nebulaPool有点误导性,不看代码以为是通常意义上的连接池
嗯嗯,这里我们有很大空间重新封装一下,或者保持原来的connPool,新增加一个 connQueue 之类的已经登录着了的。
如果您有意愿也可以来 github 讨论、贡献。