



也不是第一提问啊,补充下你做了什么操作,报了上面的错误,然后把你的内核以及 Python 客户端版本也补充下。
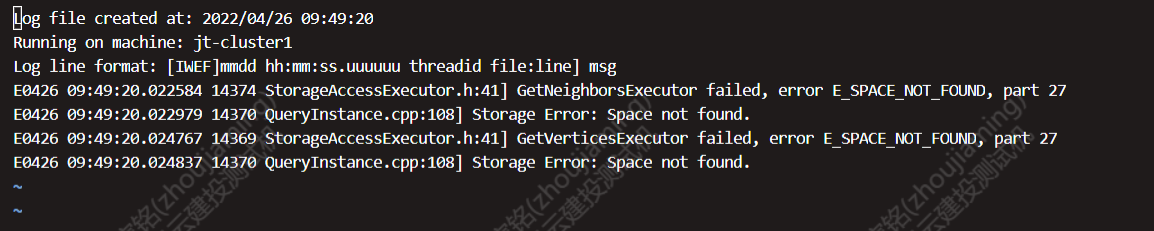
我把集群重新布了一下,我把主节点的图空间删除了,重新创建了一下,好了。顺便提问一下,版本2.6.1,一开始我使用单节点服务,后期我改变成集群,增加两个节点,修改一下配置,图空间和Tag这些信息在单节点时主节点中创建的,增加两个节点变成集群也没有重新创建,然后使用"MATCH (v) WHERE id(v) == ‘{}’ RETURN v;",这个命令。就报错了。报错原因跟单节点变集群有关系吗?
你 show hosts 看下集群的数据分布呢。
当时查看了,Leader_count 那一栏 都是 0
方便贴一下 show hosts 的结果吗?
现在没有了,我重新配置了集群之后 现在正常了。当时hosts 没有分片数量,都展示0。其实我想问,单节点改成集群方式,只是增加两个节点配置一下,不重新创建图空间、tag、edge、数据是不是会影响MATCH查询?所有节点的nebula的账号密码需要保持一致吗?
- 不会影响查询, 增加 graph 节点对单条查询性能没有影响, 但是如果是并发查询的话增加 graph 吞吐量会增加
- 账号密码在集群内的一致性是自动维护的, 在 node1创建的用户会同步到 meta 上, 在 node2 登陆的时候会从 meta 拉取用户信息
1 个赞
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。