一、选择Nebula的原因
性能优越
- 查询速度极快
- 架构分离,易扩展(目前的机器配置低,后续可能扩展)
- 高可用(由于是分布式,所以从使用到现在没有出现过宕机情况)
上手容易
- 介绍全(熟悉架构和性能)
- 部署快(经过手册的洗礼,快速部署简单的集群)
- 使用简便(遇到需要的数据,查询手册获取对应的GNQL,针对性查询)
- 答疑优秀(遇到问题,可以先翻论坛,如果没有,那就发布帖子,开发人员的帮助很及时)
开源,且技术稳定
- 因为实践企业多,用起来放心。
二、业务需求背景介绍
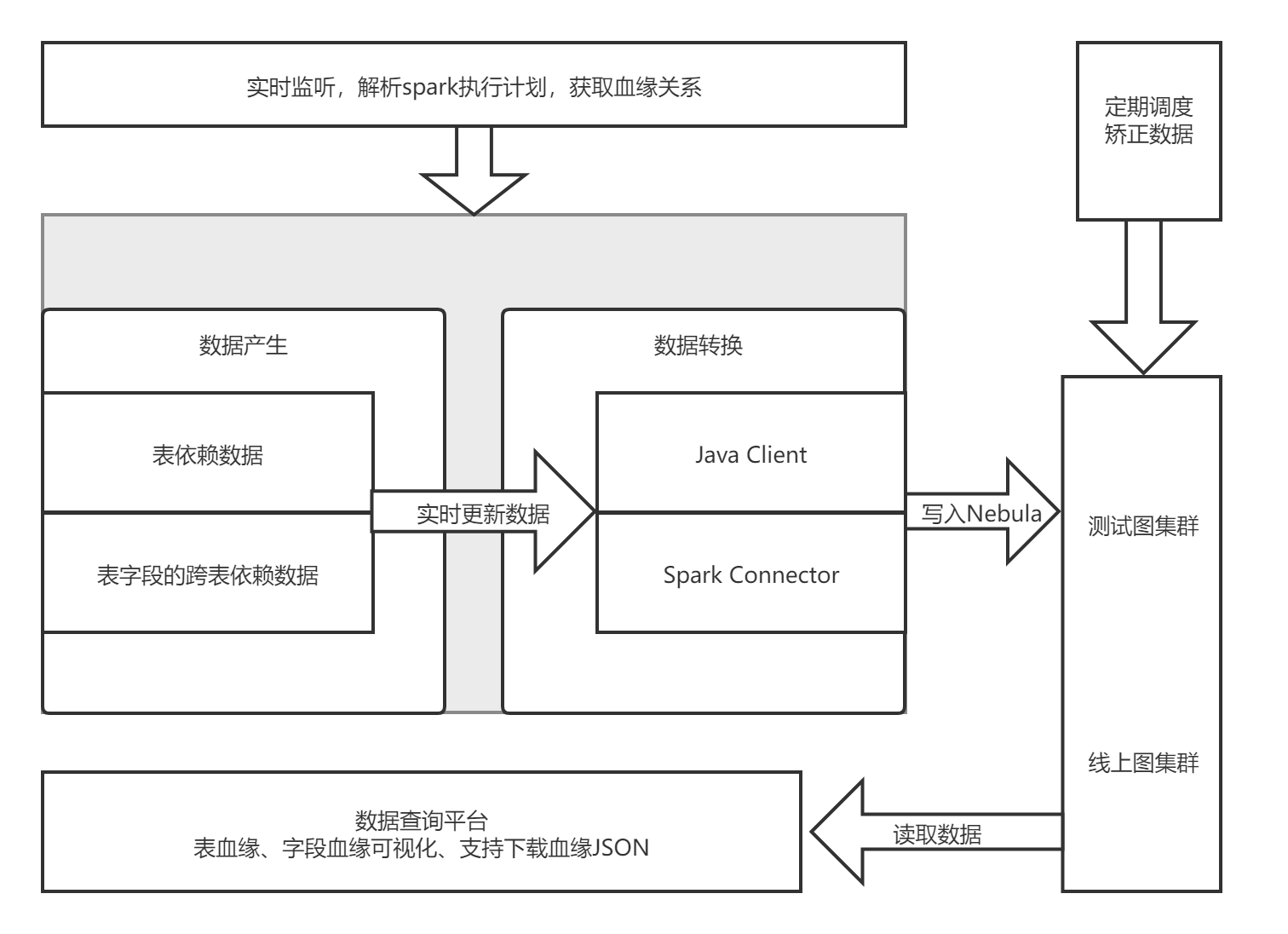
为方便数据治理、元数据管理及数据质量监控,将调度系统生成的数仓血缘保存起来。
血缘数据流程
从采集、存储到平台展示的数据全流程:
在查询平台的部分数据查询展示:

三、我的具体实践
1、版本选择
Nebula 3.0.0、Nebula Java Client 3.0.0
Nebula和Java客户端两个相兼容的版本。
2、集群部署
① 机器配置:
四台实体机,同配置:
10C * 2 / 16G * 8 / 600G
② 安装方式
RPM安装。
a. 通过wget拉取安装包后安装。
b. 更改配置文件
主要更改参数
Meta服务的所有机器 —— meta_server_addrs=ip1:9559, ip2:9559, ip3:9559
当前机器ip(如果是meta/graph/storage,填对应meta/graph/storage机器的ip,) —— local_ip
c. 启动后通过 console 简单测试
add hosts ip:port 增加自己的机器ip后,show hosts,如果是online,即可开始测试相关NGQL
3、数据导入
目前分两种情况更新数据。
a. 实时监控调度平台
监控每个任务实例,通过依赖节点获取上下游的关系,将关系实时打入到mysql和Nebula中,更新Nebula数据通过Spark Connector实现。
(mysql做备份,因为Nebula不支持事务,可能存在数据偏差)
b. 定时调度矫正数据
通过mysql中的血缘关系,通过Spark任务定时矫正Nebula数据,更新数据同样通过Spark Connector实现。
Spark Connector的使用:NebulaConnectionConfig初始化配置,然后通过连接信息、插入的点与边的相关参数及实体Tag、Edge创建WriteNebulaVertexConfig 和 WriteNebulaEdgeConfig 对象,以备写入点和边的数据。
4、数据平台查询
数据平台查询血缘的应用:
a. 获取Nebula数据实现过程
通过初始化连接池 Nebula pool,实现单例工具类,方便在整个项目中调用并使用Session。
这里一定要注意,连接池只可以有一个,而Session可以通过 Max Connection Num 设置连接数,根据实际业务来判断具体参数(平台查询越频繁,连接数就要设置的越多一些)。而每次Session使用完毕也是要释放的。
b. 查询数据,转换为 ECharts 需要的json
① 通过 getSubGraph 获取当前表或字段的所有上下游相关点,这一点通过获取子图的方法,很方便。
② 需要通过结果,解析出其中两个方向数据的点,然后递归解析,最后转为一个递归调用自己的Bean类对象。
③ 写一个满足前端需要的json串的toString方法,得到结果后即可。
这里分享一下自己的工具类,和核心逻辑代码
工具类:
object NebulaUtil {
private val log: Logger = LoggerFactory.getLogger(NebulaUtil.getClass)
private val pool: NebulaPool = new NebulaPool
private var success: Boolean = false
{
//首先初始化连接池
val nebulaPoolConfig = new NebulaPoolConfig
nebulaPoolConfig.setMaxConnSize(100)
// 初始化ip和端口
val addresses = util.Arrays.asList(new HostAddress("10.88.100.88", 9669))
success = pool.init(addresses, nebulaPoolConfig)
}
def getPool(): NebulaPool = {
pool
}
def isSuccess(): Boolean = {
success
}
//TODO query: 创建空间、进入空间、创建新的点和边的类型、插入点、插入边、执行查询
def executeResultSet(query: String, session: Session): ResultSet = {
val resp: ResultSet = session.execute(query)
if (!resp.isSucceeded){
log.error(String.format("Execute: `%s', failed: %s", query, resp.getErrorMessage))
System.exit(1)
}
resp
}
def executeJSON(queryForJson: String, session: Session): String = {
val resp: String = session.executeJson(queryForJson)
val errors: JSONObject = JSON.parseObject(resp).getJSONArray("errors").getJSONObject(0)
if (errors.getInteger("code") != 0){
log.error(String.format("Execute: `%s', failed: %s", queryForJson, errors.getString("message")))
System.exit(1)
}
resp
}
def executeNGqlWithParameter(query: String, paramMap: util.Map[String, Object], session: Session): Unit = {
val resp: ResultSet = session.executeWithParameter(query, paramMap)
if (!resp.isSucceeded){
log.error(String.format("Execute: `%s', failed: %s", query, resp.getErrorMessage))
System.exit(1)
}
}
//获取ResultSet中的各个列名及数据
//_1 列名组成的列表
//_2 多row组成的列表嵌套 单个row的列表 包含本行每一列的数据
def getInfoForResult(resultSet: ResultSet): (util.List[String], util.List[util.List[Object]]) = {
//拿到列名
val colNames: util.List[String] = resultSet.keys
//拿数据
val data: util.List[util.List[Object]] = new util.ArrayList[util.List[Object]]
//循环获取每行数据
for (i <- 0 until resultSet.rowsSize) {
val curData = new util.ArrayList[Object]
//拿到第i行数据的容器
val record = resultSet.rowValues(i)
import scala.collection.JavaConversions._
//获取容器中数据
for (value <- record.values) {
if (value.isString) curData.add(value.asString)
else if (value.isLong) curData.add(value.asLong.toString)
else if (value.isBoolean) curData.add(value.asBoolean.toString)
else if (value.isDouble) curData.add(value.asDouble.toString)
else if (value.isTime) curData.add(value.asTime.toString)
else if (value.isDate) curData.add(value.asDate.toString)
else if (value.isDateTime) curData.add(value.asDateTime.toString)
else if (value.isVertex) curData.add(value.asNode.toString)
else if (value.isEdge) curData.add(value.asRelationship.toString)
else if (value.isPath) curData.add(value.asPath.toString)
else if (value.isList) curData.add(value.asList.toString)
else if (value.isSet) curData.add(value.asSet.toString)
else if (value.isMap) curData.add(value.asMap.toString)
}
//合并数据
data.add(curData)
}
(colNames, data)
}
def close(): Unit = {
pool.close()
}
}
核心代码:
//bean next 指针为可变数组
//获取子图
//field_name 起始节点, direct 子图方向(true 下游, false 上游)
def getSubgraph(field_name: String, direct: Boolean, nebulaSession: Session): FieldRely = {
// field_name 所在节点
val relyResult = new FieldRely(field_name, new mutable.ArrayBuffer[FieldRely])
// out 为下游, in 为上游
var downOrUp = "out"
// 获取当前查询的方向
if (direct){
downOrUp = "out"
} else {
downOrUp = "in"
}
//1 查询语句 查询下游所有子图
val query =
s"""
| get subgraph 100 steps from "$field_name" $downOrUp field_rely yield edges as field_rely;
|""".stripMargin
val resultSet = NebulaUtil.executeResultSet(query, nebulaSession)
//[[:field_rely "dws.dws_order+ds_code"->"dws.dws_order_day+ds_code" @0 {}], [:field_rely "dws.dws_order+ds_code"->"tujia_qlibra.dws_order+p_ds_code" @0 {}], [:field_rely "dws.dws_order+ds_code"->"tujia_tmp.dws_order_execution+ds_code" @0 {}]]
//非空则获取数据
if (!resultSet.isEmpty) {
//非空,则拿数据,解析数据
val data = NebulaUtil.getInfoForResult(resultSet)
val curData: util.List[util.List[Object]] = data._2
//正则匹配引号中数据
val pattern = Pattern.compile("\"([^\"]*)\"")
// 上一步长的所有节点数组
// 判断节点的父节点, 方便存储
var parentNode = new mutable.ArrayBuffer[FieldRely]()
//2 首先获取步长为 1 的边
curData.get(0).get(0).toString.split(",").foreach(curEdge =>{
//拿到边的起始和目的点
val matcher = pattern.matcher(curEdge)
var startPoint = ""
var endPoint = ""
//将两点赋值
while (matcher.find()){
val curValue = matcher.group().replaceAll("\"", "")
// 上下游的指向是不同的 所以需要根据上下游切换 开始节点和结束节点的信息获取
// out 为下游, 数据结构是 startPoint -> endPoint
if(direct){
if ("".equals(startPoint)){
startPoint = curValue
}else{
endPoint = curValue
}
}else {
// in 为上游, 数据结构是 endPoint -> startPoint
if ("".equals(endPoint)){
endPoint = curValue
}else{
startPoint = curValue
}
}
}
//合并到起点 bean 中
relyResult.children.append(new FieldRely(endPoint, new ArrayBuffer[FieldRely]()))
})
//3 并初始化父节点数组
parentNode = relyResult.children
//4 得到其余所有边
for (i <- 1 until curData.size - 1){
//储存下个步长的父节点集合
val nextParentNode = new mutable.ArrayBuffer[FieldRely]()
val curEdges = curData.get(i).get(0).toString
//3 多个边循环解析, 拿到目的点
curEdges.split(",").foreach(curEdge => {
//拿到边的起始和目的点
val matcher = pattern.matcher(curEdge)
var startPoint = ""
val endNode = new FieldRely("")
//将两点赋值
while (matcher.find()){
val curValue = matcher.group().replaceAll("\"", "")
// logger.info(s"not 1 curValue: $curValue")
if(direct) {
if ("".equals(startPoint)){
startPoint = curValue
}else{
endNode.name = curValue
endNode.children = new mutable.ArrayBuffer[FieldRely]()
nextParentNode.append(endNode)
}
}else {
if ("".equals(endNode.name)){
endNode.name = curValue
endNode.children = new mutable.ArrayBuffer[FieldRely]()
nextParentNode.append(endNode)
}else{
startPoint = curValue
}
}
}
//通过 startPoint 找到父节点, 将 endPoint 加入到本父节点的 children 中
var flag = true
//至此, 一条边插入成功
for (curFieldRely <- parentNode if flag){
if (curFieldRely.name.equals(startPoint)){
curFieldRely.children.append(endNode)
flag = false
}
}
})
//更新父节点
parentNode = nextParentNode
}
}
// logger.info(s"relyResult.toString: ${relyResult.toString}")
relyResult
}
bean toString:
class FieldRely {
@BeanProperty
var name: String = _ // 当前节点字段名
@BeanProperty
var children: mutable.ArrayBuffer[FieldRely] = _ // 当前节点对应的所有上游或下游子字段名
def this(name: String, children: mutable.ArrayBuffer[FieldRely]) = {
this()
this.name = name
this.children = children
}
def this(name: String) = {
this()
this.name = name
}
override def toString(): String = {
var resultString = ""
//引号变量
val quote = "\""
//空的话直接将 child 置为空数组的json
if (children.isEmpty){
resultString += s"{${quote}name${quote}: ${quote}$name${quote}, ${quote}children${quote}: []}"
}else {
//child 有数据, 添加索引并循环获取
var childrenStr = ""
// var index = 0
for (curRely <- children){
val curRelyStr = curRely.toString
childrenStr += curRelyStr + ", "
// index += 1
}
// 去掉多余的 ', '
if (childrenStr.length > 2){
childrenStr = childrenStr.substring(0, childrenStr.length - 2)
}
resultString += s"{${quote}name${quote}: ${quote}$name${quote}, ${quote}children${quote}: [$childrenStr]}"
}
resultString
}
}
c. 得到的优化结果
在查询子图步长接近20的情况下,基本上接口返回数据可以控制在200ms内(包含后端复杂处理逻辑)
本文正在参加 首届Nebula征文活动,如果你觉得本文对你有所帮助可以给我点个
,以示鼓励~
谢谢(#^.^#)
我是数据开发的实习生,目前在途家的数据开发岗位上工作四个月左右的时间了,期间负责开发数据平台的功能。
因为其中一些数据的读写性能较低,所以在调研后,选择部署一个Nebula 集群,它的技术体系也是比较成熟的,社区也比较完善,对刚刚接触的它的人非常友好。所以很快就开始投入使用了。在使用过程中,有一些自己的见解,和遇到的一些问题及解决方法,在这里向大家分享一下自己的使用经验。


 ,感谢分享!
,感谢分享!