schema:
CREATE EDGE GID_UID(create_time timestamp,update_time timestamp);
CREATE EDGE INDEX index_0 on GID_UID(update_time);
edge导入的数据量有100GB+
查询
LOOKUP ON GID_UID WHERE GID_UID.update_time > 1592582400 | limit 10;
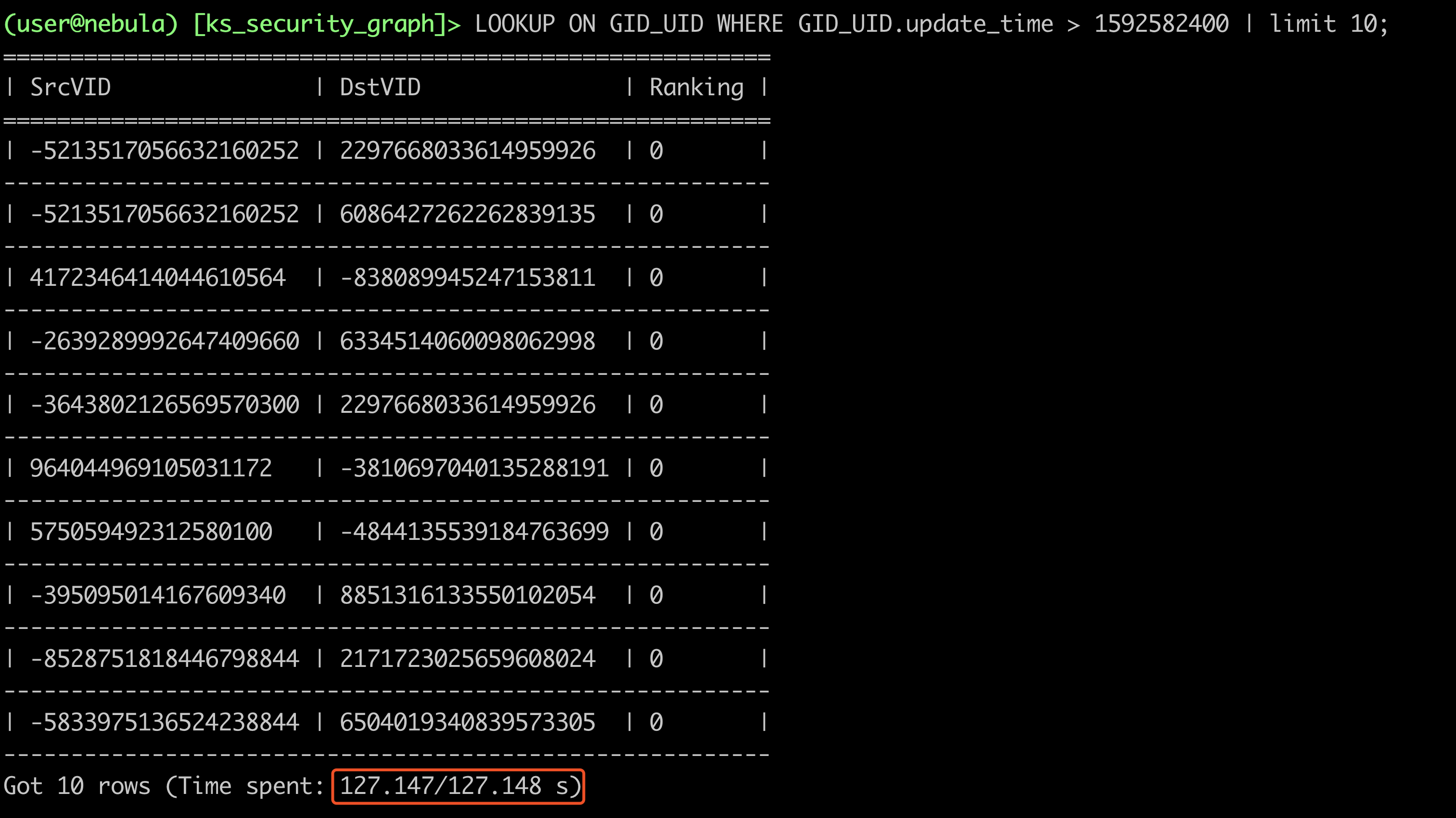
问题一、请问查询索引耗时这么长的原因可能是?
另外,看官方关于索引的设计介绍https://nebula-graph.com.cn/posts/how-indexing-works-in-nebula-graph/

需求是查vertexA 的所有update_time 在一个时间范围内的所有边
之前用go 查实际并不走索引
go from hash(‘000000000a264302’) over GID_DID where GID_DID.update_time >=1592582400 yield GID_DID.create_time,GID_DID.update_time;
问题二、有个想法是用lookup查,不知道是否支持,试了一下报语法错误
LOOKUP ON GID_UID WHERE GID_UID.update_time > 1592582400 and GID_UID.SrcVID = vid