求助,docker-swarm 修改后部署失败,求官方大手支援
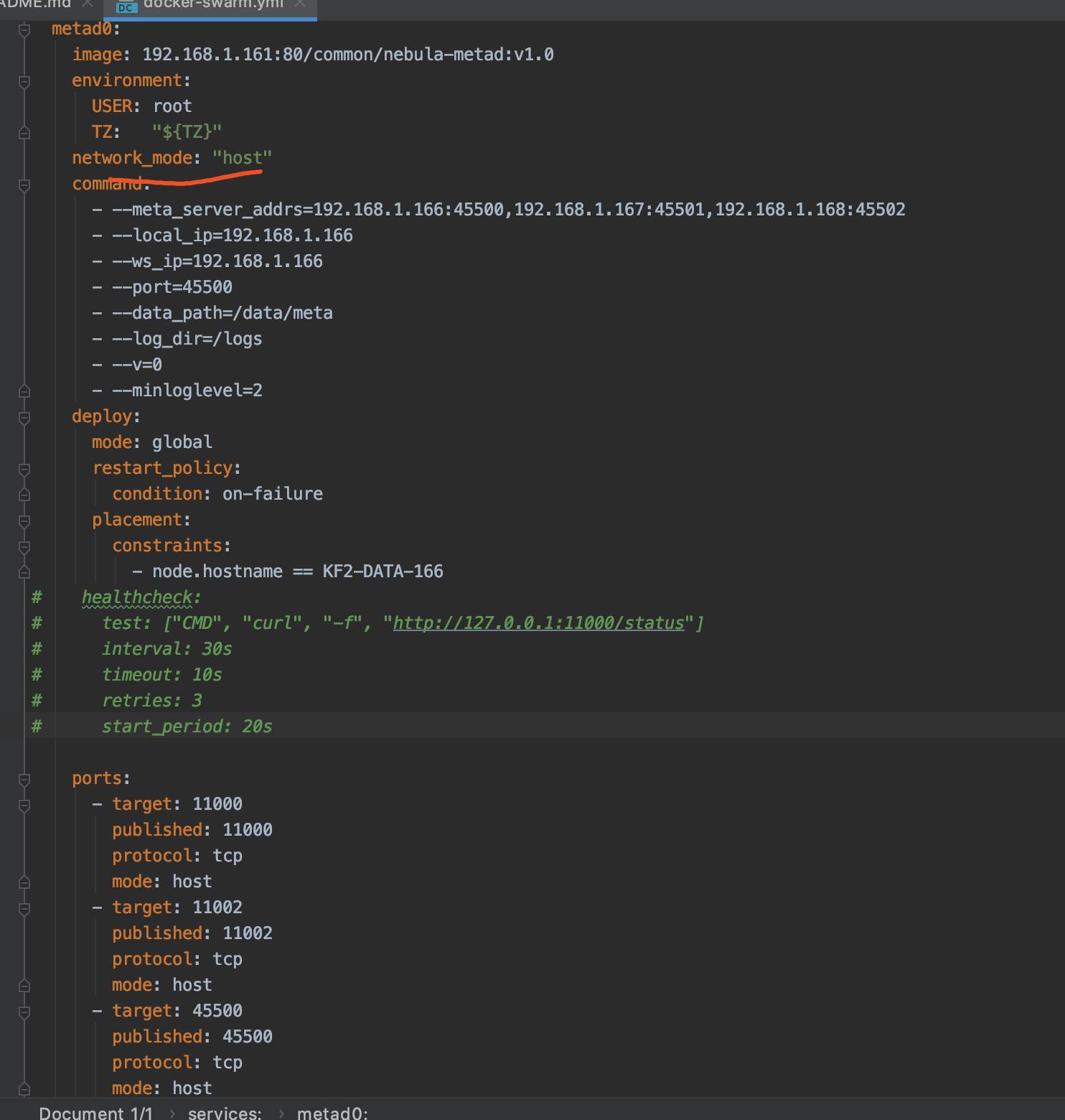
docker-swarm文件
version: '3.4'
services:
metad0:
image: 192.168.1.161:80/common/nebula-metad:v1.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=192.168.1.166:45500,192.168.1.167:45501,192.168.1.168:45502
- --local_ip=192.168.1.166
- --ws_ip=192.168.1.166
- --port=45500
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=2
deploy:
mode: global
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname == KF2-DATA-166
healthcheck:
test: ["CMD", "curl", "-f", "http://192.168.1.166:11000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- target: 11000
published: 11000
protocol: tcp
mode: host
- target: 11002
published: 11002
protocol: tcp
mode: host
- target: 45500
published: 45500
protocol: tcp
mode: host
volumes:
- ./data/meta0:/data/meta
- ./logs/meta0:/logs
networks:
- nebula-net
metad1:
image: 192.168.1.161:80/common/nebula-metad:v1.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=192.168.1.166:45500,192.168.1.167:45501,192.168.1.168:45502
- --local_ip=192.168.1.167
- --ws_ip=192.168.1.167
- --port=45500
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=2
deploy:
mode: global
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname == KF2-DATA-167
healthcheck:
test: ["CMD", "curl", "-f", "http://192.168.1.167:11001/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- target: 11000
published: 11001
protocol: tcp
mode: host
- target: 11002
published: 11002
protocol: tcp
mode: host
- target: 45500
published: 45501
protocol: tcp
mode: host
volumes:
- ./data/meta1:/data/meta
- ./logs/meta1:/logs
networks:
- nebula-net
metad2:
image: 192.168.1.161:80/common/nebula-metad:v1.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=192.168.1.166:45500,192.168.1.167:45501,192.168.1.168:45502
- --local_ip=192.168.1.168
- --ws_ip=192.168.1.168
- --port=45500
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=2
deploy:
mode: global
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname == KF2-DATA-168
healthcheck:
test: ["CMD", "curl", "-f", "http://192.168.1.168:11003/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- target: 11000
published: 11003
protocol: tcp
mode: host
- target: 11002
published: 11004
protocol: tcp
mode: host
- target: 45500
published: 45502
protocol: tcp
mode: host
volumes:
- ./data/meta2:/data/meta
- ./logs/meta2:/logs
networks:
- nebula-net
storaged0:
image: 192.168.1.161:80/common/nebula-storaged:v1.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=192.168.1.166:45500,192.168.1.167:45501,192.168.1.168:45502
- --local_ip=192.168.1.166
- --ws_ip=192.168.1.166
- --port=44500
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=2
deploy:
mode: global
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname == KF2-DATA-166
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://192.168.1.166:12000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- target: 12000
published: 12000
protocol: tcp
mode: host
- target: 12002
published: 12002
protocol: tcp
mode: host
volumes:
- ./data/storage0:/data/storage
- ./logs/storage0:/logs
networks:
- nebula-net
storaged1:
image: 192.168.1.161:80/common/nebula-storaged:v1.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=192.168.1.166:45500,192.168.1.167:45501,192.168.1.168:45502
- --local_ip=192.168.1.167
- --ws_ip=192.168.1.167
- --port=44500
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=2
deploy:
mode: global
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname == KF2-DATA-167
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://192.168.1.167:12003/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- target: 12000
published: 12003
protocol: tcp
mode: host
- target: 12002
published: 12004
protocol: tcp
mode: host
volumes:
- ./data/storage1:/data/storage
- ./logs/storage1:/logs
networks:
- nebula-net
storaged2:
image: 192.168.1.161:80/common/nebula-storaged:v1.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=192.168.1.166:45500,192.168.1.167:45501,192.168.1.168:45502
- --local_ip=192.168.1.168
- --ws_ip=192.168.1.168
- --port=44500
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=2
deploy:
mode: global
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname == KF2-DATA-168
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://192.168.1.168:12005/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- target: 12000
published: 12005
protocol: tcp
mode: host
- target: 12002
published: 12006
protocol: tcp
mode: host
volumes:
- ./data/storage2:/data/storage
- ./logs/storage2:/logs
networks:
- nebula-net
graphd:
image: 192.168.1.161:80/common/nebula-graphd:v1.0
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=192.168.1.166:45500,192.168.1.167:45501,192.168.1.168:45502
- --port=3699
- --ws_ip=192.168.1.166
- --log_dir=/logs
- --v=0
- --minloglevel=2
deploy:
mode: global
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname == KF2-DATA-166
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-f", "http://192.168.1.166:13000/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- target: 3699
published: 3699
protocol: tcp
mode: host
- target: 13000
published: 13000
protocol: tcp
mode: host
- target: 13002
published: 13002
protocol: tcp
mode: host
volumes:
- ./logs/graph:/logs
networks:
- nebula-net
networks:
nebula-net:
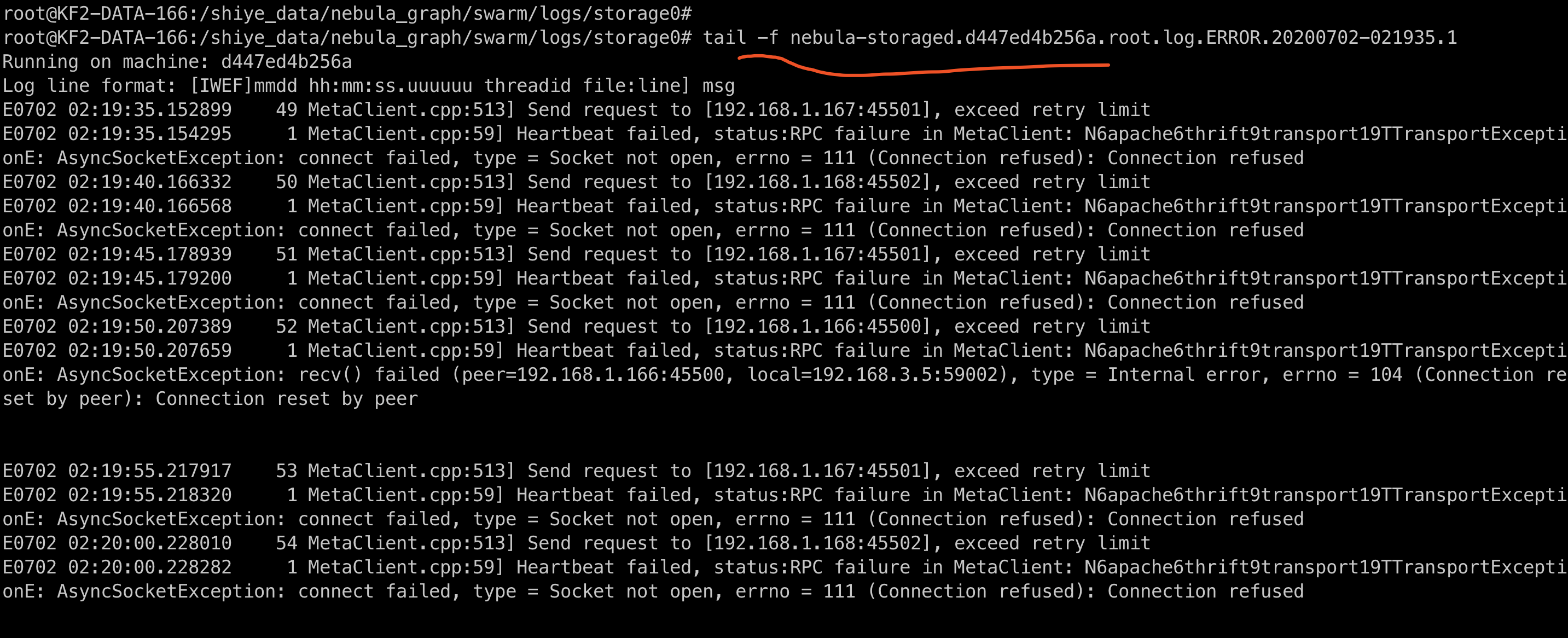
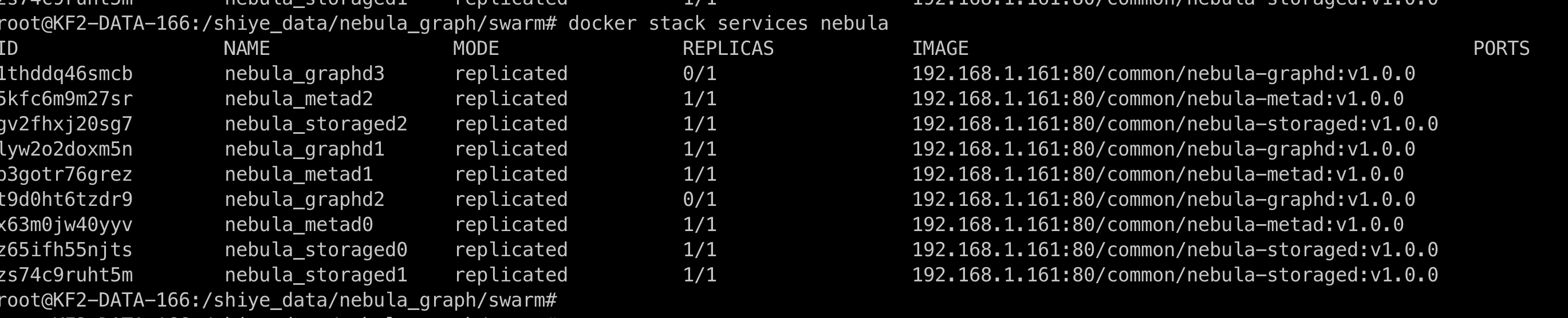
问题截图


格式有点问题,欢迎联系
邮箱:henson_wu@foxmail.com
vx: wu88888888000