nebula 版本:v3.0.0
部署方式:单机
安装方式: RPM
硬件信息
磁盘 :SSD
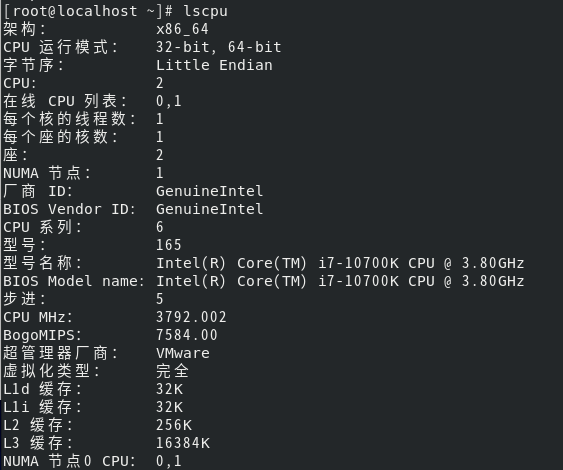
CPU、内存信息
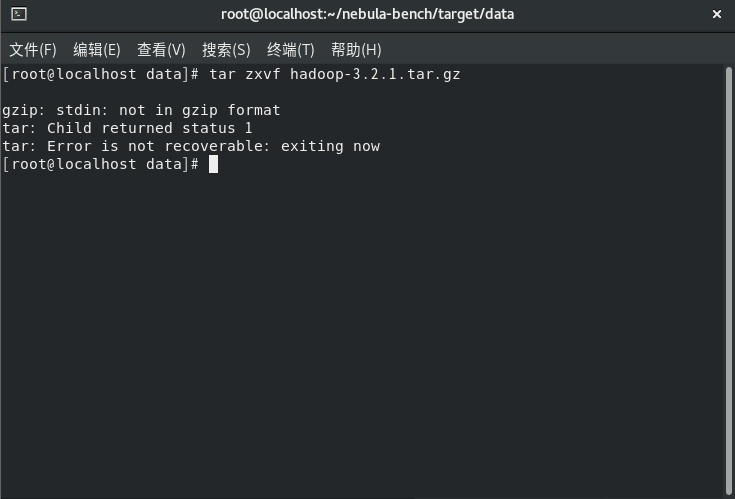
在运用nebula-bench对nebula进行k6的测试中,按照https://github.com/vesoft-inc/nebula-bench/blob/master/README_cn.md中的步骤进行执行,在数据集生成过程中也就是Python3 run.py data语句后会出现这样的问题
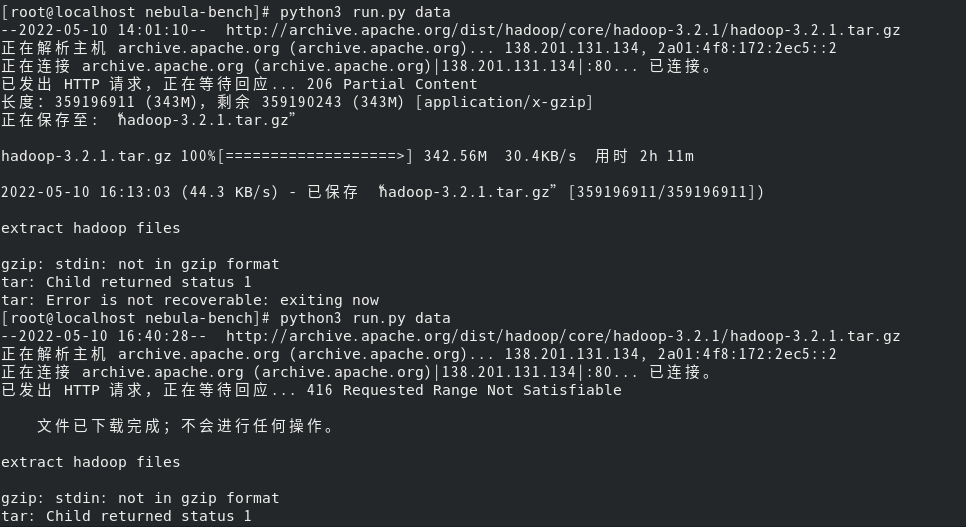
请问应该怎么解决呢,并且想知道这里生成的数据集是什么数据集,是不是3.0.0测试报告中提到的ldbc snb sf100的那个数据集,如果不是,如果想生成这个sf100的数据集应该怎么去操作,并且如果想把sf100的数据集导入nebula并运用k6去进行一个单机的测试,虚拟机的存储空间最少需要多少的硬盘空间?
望解答,谢谢