作者介绍
大家好,我是 Anyzm,graph-ocean(GitHub:https://github.com/nebula-contrib/graph-ocean ) 项目发起人,目前就职于 360数科,岗位是高级 JAVA 开发工程师。
介绍完自己,这里来介绍下 graph-ocean 是什么?
graph-ocean 简介
graph-ocean 是一款基于 nebula-java 客户端的 ORM(Object Relational Mapping)框架,熟悉 ORM 的小伙伴应该都知道 ORM 是创建可在编程语言里使用的“虚拟对象数据库”,让开发人员更高效地开发业务。
而我将 Java ORM 取名为 graph-ocean 源自 Ocean 与 Nebula Graph 的 Nebula(星辰)相呼应,意为星辰大海。
为什要设计一款 Java ORM
社区用户如果对 360数科熟悉的话,读过我们技术团队写的《JanusGraph 到 NebulaGraph 迁移》(链接:https://discuss.nebula-graph.com.cn/t/topic/1172)便知道我们在 Nebula Graph 很早期便开始使用它,在官方正式发布 v1.0.0 之前就已经在测试环境跑起来了。
在 360数科使用 Nebula Graph v1.0.0 过程中,我们 Java 客户端是用枚举来呈列用到的 Tag 和 Edge 数据,而将 API 解析成 nGQL 的过程中也强依赖枚举,对业务代码侵入性强。
所以,在后来接触项目的过程中我就决心改变这种局面。
解决代码入侵问题
我们都知道无论是什么框架与数据库连接,框架最终都是会解析成数据库所能识别的语言。对于 Nebula Graph 而言,用户可以使用 openCypher,也可以使用 Nebula Graph 原生查询语言 nGQL。
在我们项目中习惯于使用 nGQL,所以将业务代码解析成 nGQL 这一步骤在使用 v1.0.0 的过程中已经完成了很大一部分。业务代码侵入性的特性是由于顶点和边的枚举所带来的,枚举的作用是定位 Tag 或者 Edge,而想要从实体类上无侵入地获取这些信息,我想到了模仿 JPA(Java Persistence API)注解的方式。
于是,graph-ocean 在脑海中便有了初步模样,实体类一旦确定,对应的 Tag 或者 Edge 应该也是确定的,所以可以用到缓存来提高性能。
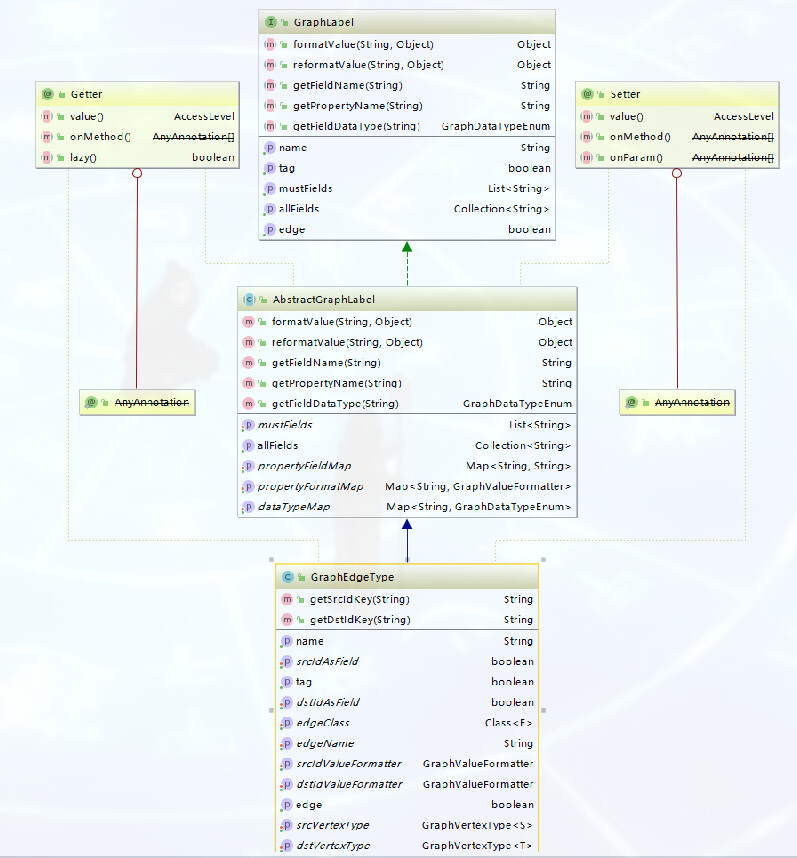
(整体设计图)
简单设计之后,graph-ocean 就诞生了。开发出来之后,我和同事们用起来都感觉很爽,于是便决定将框架开源出来反哺给社区。
graph-ocean 特性
graph-ocean 可以让开发者更加优雅、更加灵活地对 Nebula Graph 读写,并且可以帮助我们快速地将实体和数据库数据实现互转(这也是 ORM 框架的特点),同时因为有缓存存在,所以性能方面也不必担心。
graph-ocean 的简单使用
graph-ocean 是由 Java 注解、反射、缓存、字符串拼接、nebula-java 连接池、session 管理等部分组成的。使用者如果有熟练的反射和连接池的开发经验就可以快速上手了,如果没有也没关系,主要抓住 NebulaSessionPoolManager(session 管理)、GraphMapper(基础的数据库操作类)、@GraphEdge(边注解)、@GraphVertex(顶点注解)、@GraphProperty(属性注解)、GraphQuery(查询API)、QueryResult(查询结果)这几个类或者接口就可以了。
graph-ocean 的未来规划
graph-ocean 目前还未支持 Nebula Graph 所有的内置函数(不过也已经满足大部分业务场景),由于 graph-ocean 依赖 nebula-java,所以随着 nebula-java 的版本更替,graph-ocean 也需要长期维护版本问题。
由于 graph-ocean 目前基本是由我一人在维护,文档也还不齐全,还有很多需要完善的点。
所以,下阶段是逐步完善使用文档,以及完善 API,同时希望有更多志同道合的人一起参与进来,维护 graph-ocean 这片星辰大海。
 太强了
太强了
 目前框架已经发布graph-ocean 3.0.0
目前框架已经发布graph-ocean 3.0.0