调度平台增加Nebula数据导入
将在 Dolphin Scheduler 中增加导入数据到 Nebula Graph 的数据迁移任务节点。
目前有两种方案(并行开发):
对于方案一还是我的思路呦,提前分享一哈,有什么问题,欢迎大家一起讨论。
而方案二已经接近开发尾声,是自己蹚过的经验分享一哈。
一:通过 Exchange 将数据导入到 Nebula Graph。
这种方式的优点是:易开发,已维护,因为 Nebula Graph 已经非常友好地支持了这一支持操作,只需要将插入的信息提前以hive表的形式保存即可。
下面是对应数据格式的预先准备条件:
①对应 Vertex 的一些 hive 表,包含点ID、点Tag及其属性值。
在这里,关于 Vertex 的表结构又分为两类:
1)表只有一列,VID —— 不包含 tag 的点 或者 是只包含无属性 tag 的点
2)表包含VID以及当前所有 tag 的属性值 —— 包含含有属性的 tag 点
如下图:需要在编译Exchange后,在配置中添加导入涉及到的 Tag
a. 指定在 Nebula 中的 tag name(name)
b. 指定他们的来源,以及输出(type)
c. 指定来源的数据查询sql(exec)
d. 将 source 查询结果的列名和 sink 里 tag 中的属性名对应起来
e. 最后指定 vid 来自于 source 的哪一列
f. 导入时的其他限制条件

②对应 Edge 的一些 hive 表,包含边
对于边这里,也同样有两类表结构:
1)表只有两列,分别代表起始点的 VID —— 无属性边
2)表除了有代表起始点 VID 的两列,还有当前边的属性 —— 有属性边
如下图:同样需要在配置中添加 Edge Type
a. 指定在 Nebula 中的 edge name(name)
b. 指定他们的来源,以及输出(type)
c. 指定来源的数据查询sql(exec)
d. 分别指定起始两个点的对应列 (source、target)
e. 根据需求决定是否指定 rank 值(ranking)
f. 导入时的其他限制条件

③最后一步是提交 spark 任务
${SPARK_HOME}/bin/spark-submit --master “local” --class com.vesoft.nebula.exchange.Exchange <nebula-exchange-3.0.0.jar_path> -c <hive_application.conf_path> -h
在这里,我的计划是在 Dolphin Scheduler 中,执行任务前,通过前端传来用户的输入,转换成对应的配置文件,最后通过打入服务器运行命令结合配置执行数据导入。
这里是手册链接(对于我的方案一,更详细的说明在官方手册):Exchange hive to nebula
二:直接通过 Java Client 实现自动化导入
Source:我这里的方案是通过前端传入的一个大sql,查出一个宽表结果,所有准备导入的点、tag属性、边和边属性,通过传到后端,解析出一列一列的数据。
Sink:而Nebula方面,准备好实体类嵌套,将所有的点和边集成在一起,统一通过 NGQL 插入。
当前前端可视化输入已完成,如下图所示:
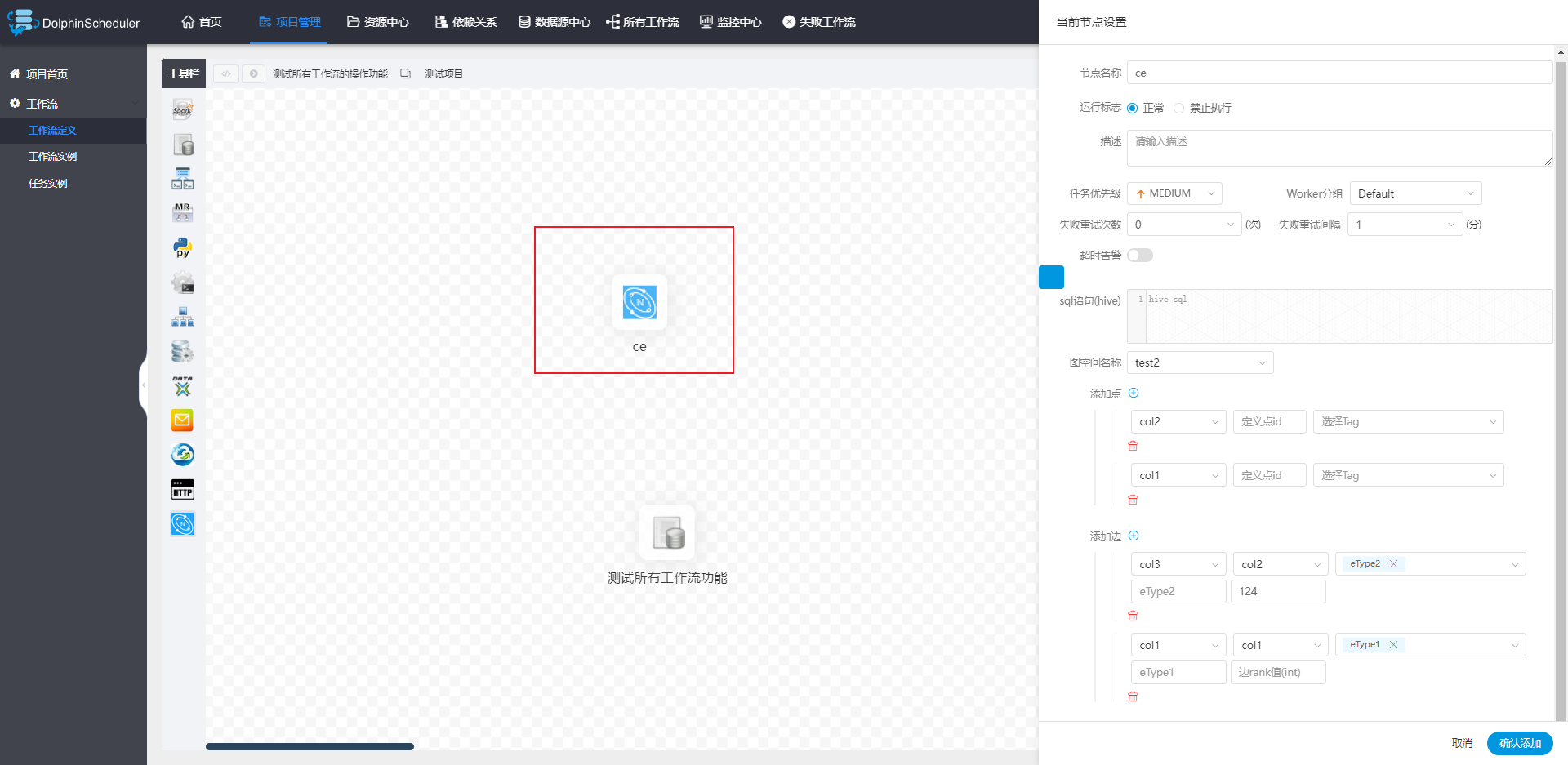
通过前端用户选择图空间,然后后端接口调出对应图空间的 Tag 和 Edge 信息,赋予到下拉框中,而通过解析hive sql 的查询结果,将对应的列名赋予到下拉框中,以便用户选择。
到了导入逻辑时,只需要根据用户填入的信息去对应转换即可。
由于开发还没有真正完成,期待后续补充和同样使用 Nebula Graph 的大神们共同分享。
本文正在参加 首届Nebula征文活动 1,如果你觉得本文对你有所帮助可以给我点个
,以示鼓励~
谢谢(#^.^#)
