xjyou
1
环境:
采用三台虚拟机(在一台物理机上),metad, graphd, storaged节点数都为3.
数据量:几十亿条数据。
机器配置:cpu核数:16核;内存:16G;硬盘:1TB。
nebula-console版本与nebula版本一致:v3.0.x。
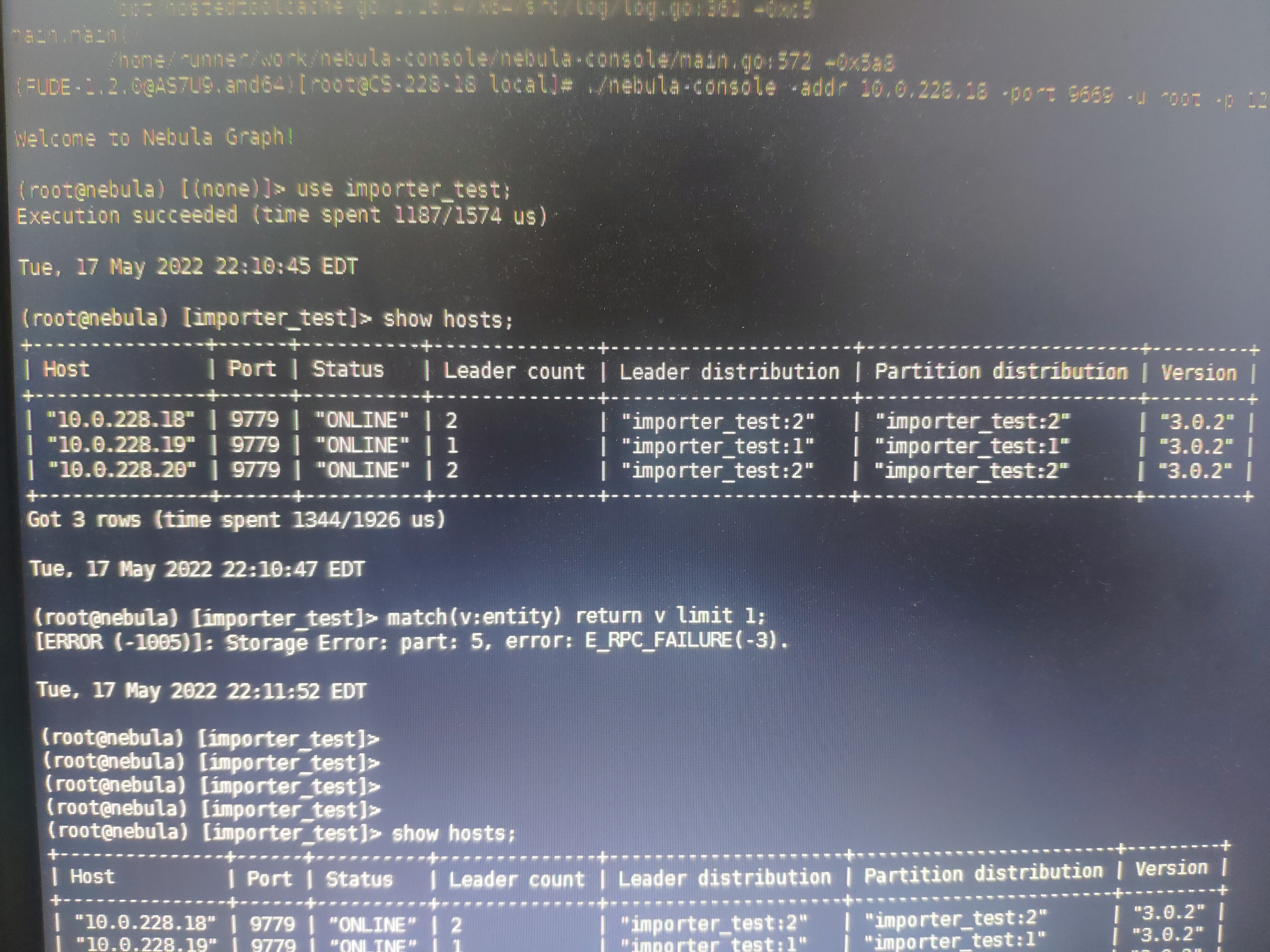
使用console客户端查询语句如下:
match (v:entity{type:"1030028", value:"14328875954"}) return v
错误如下:
storage Error: part:5, error: E_RPC_FAILURE(-3)
昨天还能查,今天就这样了。
尝试过的解决办法:
1.重启(无效)
2.换另外的查询语句(同样报错)
3.使用show hosts,能够查询,且集群正常。
4.console没有日志,没有办法定位到问题。
steam
2
你们数据量大概多少,你可以 profile 加在 match 语句那边看看。
xjyou
3
数据量大概是13亿节点,8亿的边。好 ,profile加在 match的前面么,好
xjyou
5
很奇怪,上午执行语句
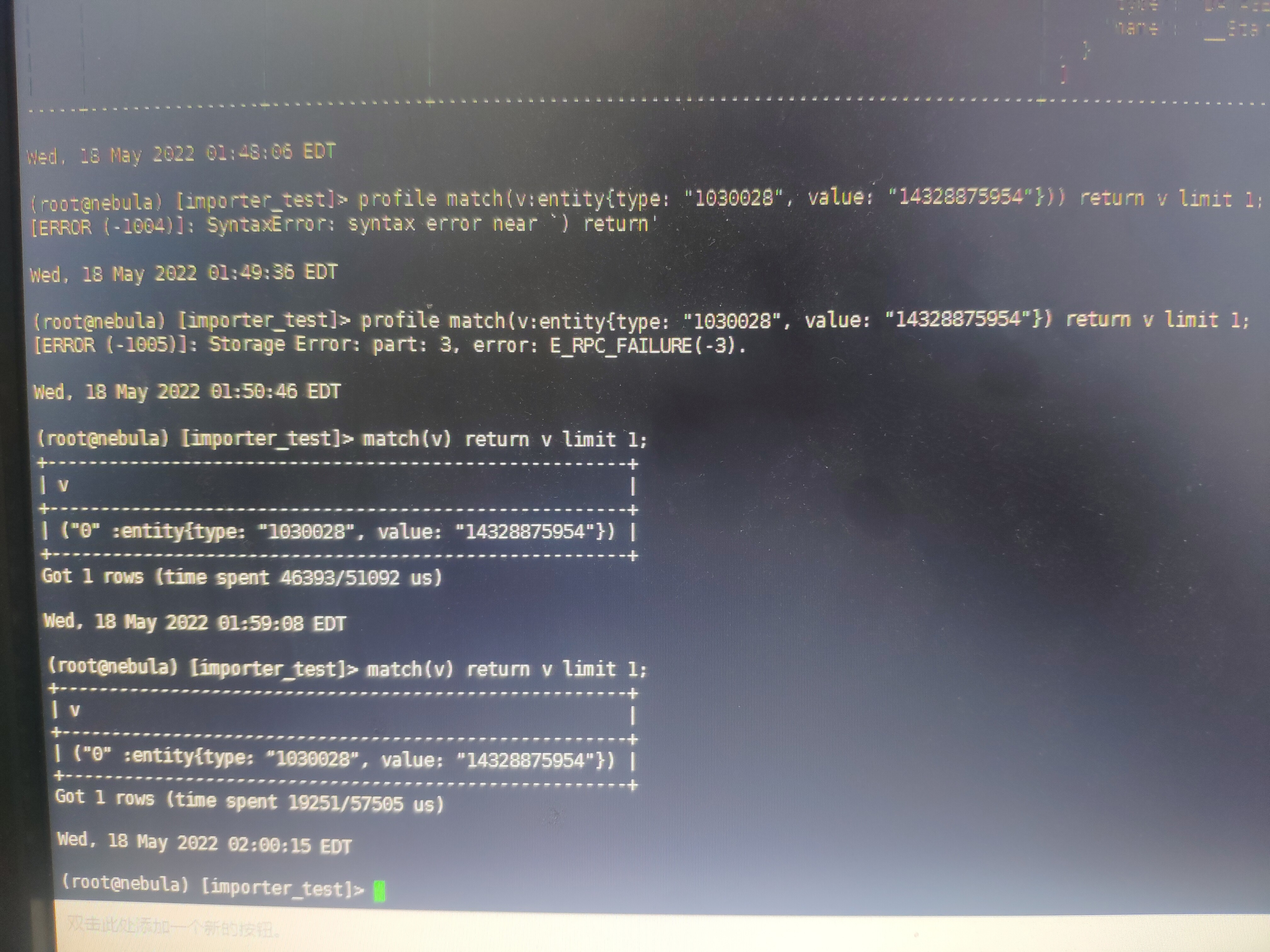
match(v) return v limit 1
时候还报错误,下午就可以执行了。
不过,根据属性查询特定节点还是报错,加上profile也是报错。
profile match (v:entity{type:"1030028", value:"14328875954"}) return v
类似storage Error: part:5, error: E_RPC_FAILURE(-3)
steam
11
storage 服务起来到退出,之间没有做任何操作吗? 有日志吗?
有日志吗?
xjyou
12
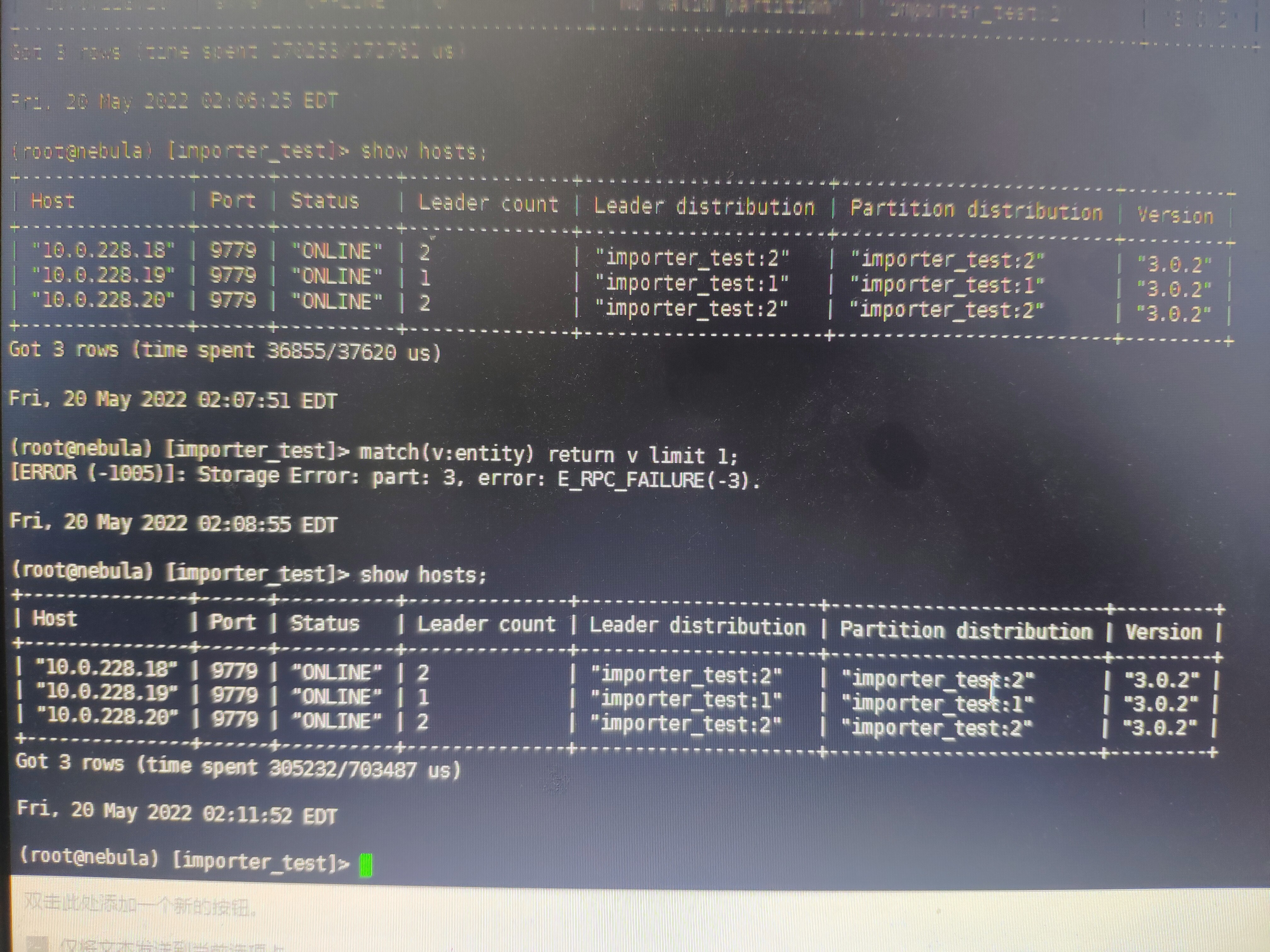
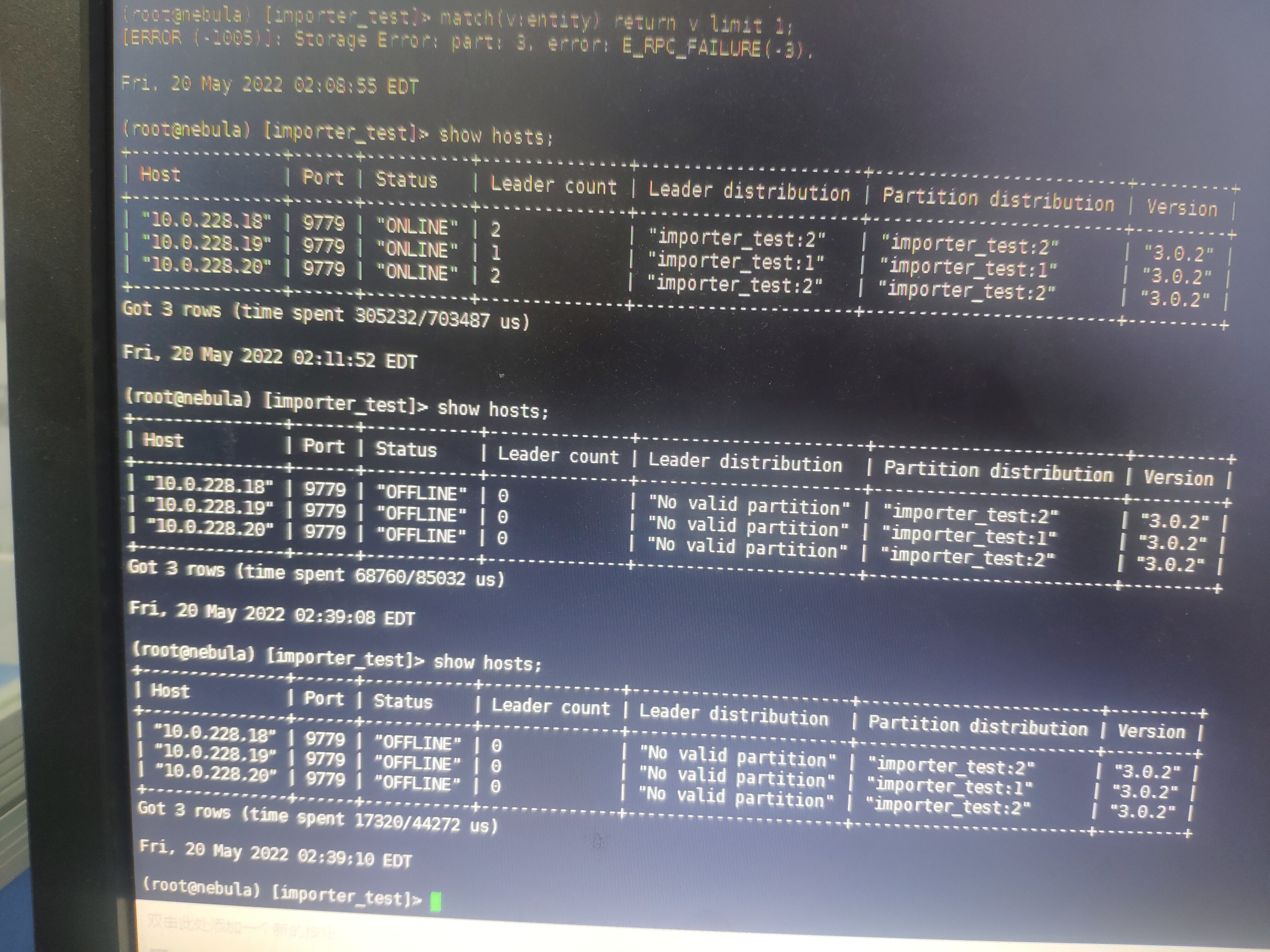
起来之后,查了一下match(v) return v limit 1。然后报错类似storage Error: part:5, error: E_RPC_FAILURE(-3),然后show host,状态正常。 过几分钟后,再show host,就全部OFFLINE了。
有新增的ERROR级别的metad日志。storaged没有ERROR级别的日志。
。还有一个现象就是,我用start all命令启动metad, storaged, graphd服务的时候,storaged服务总是会exited,需要单独再用start graphd命令。
麻烦贴点storage INFO日志 然后描述清楚是啥时候的日志
xjyou
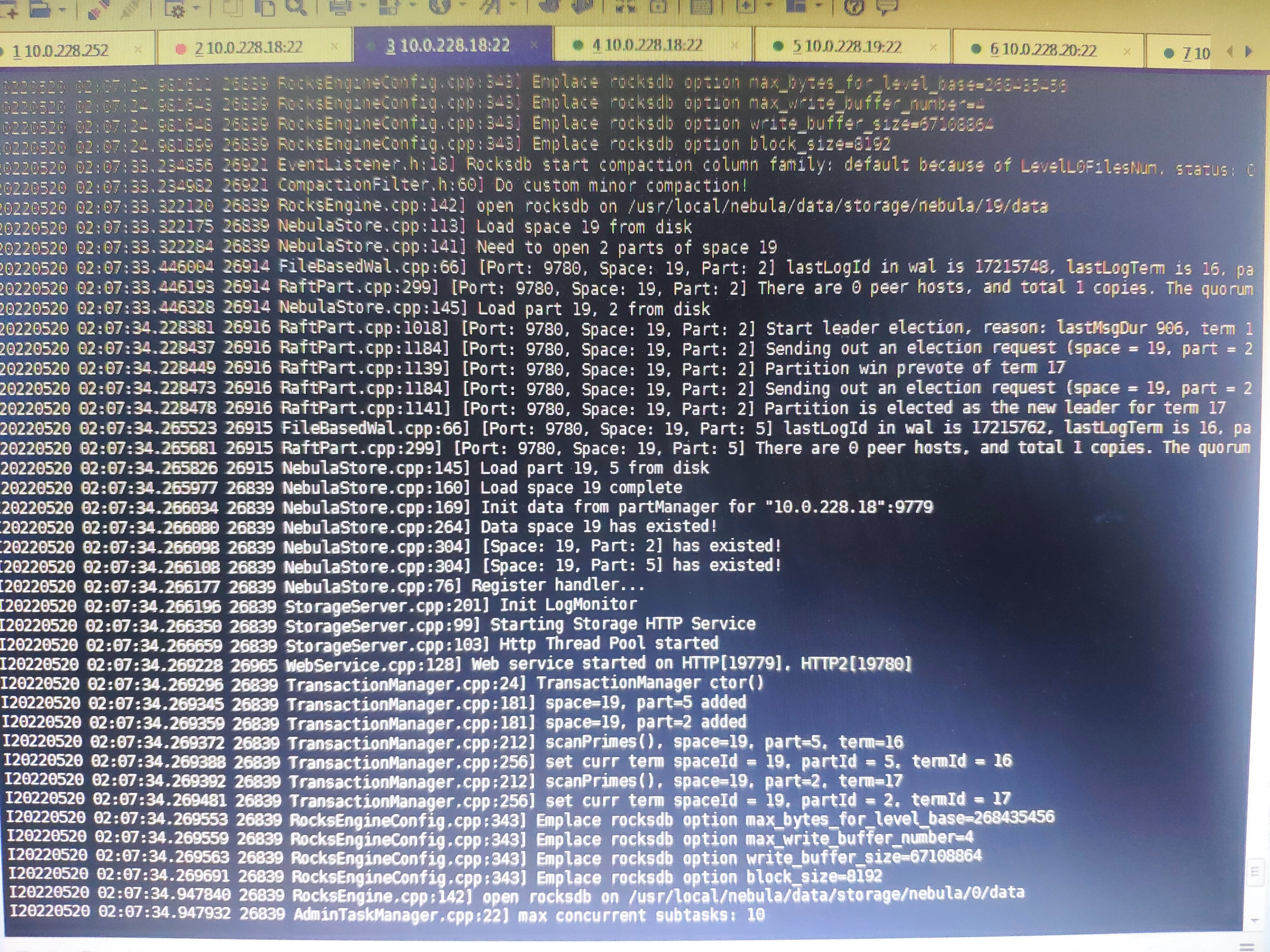
14
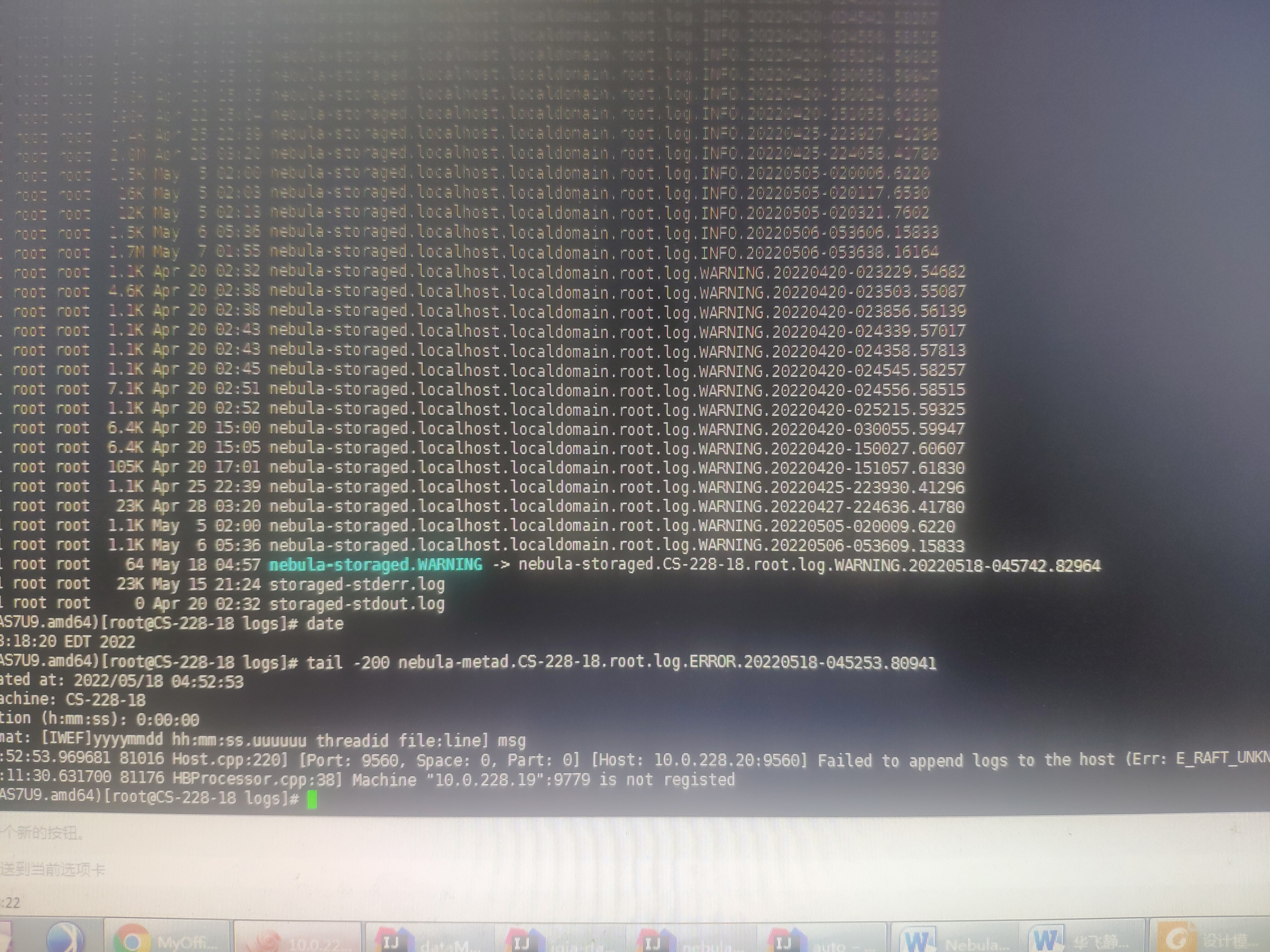
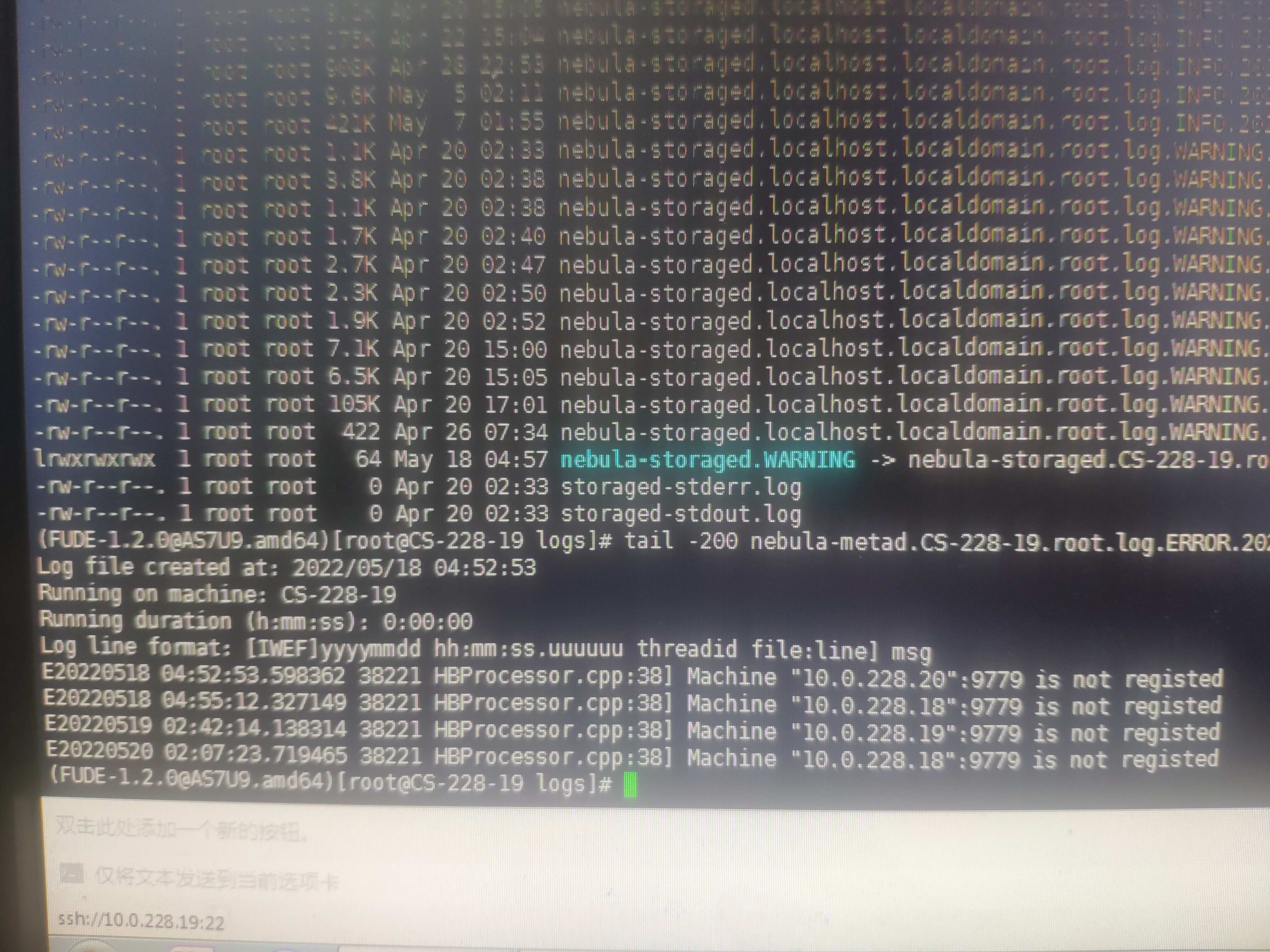
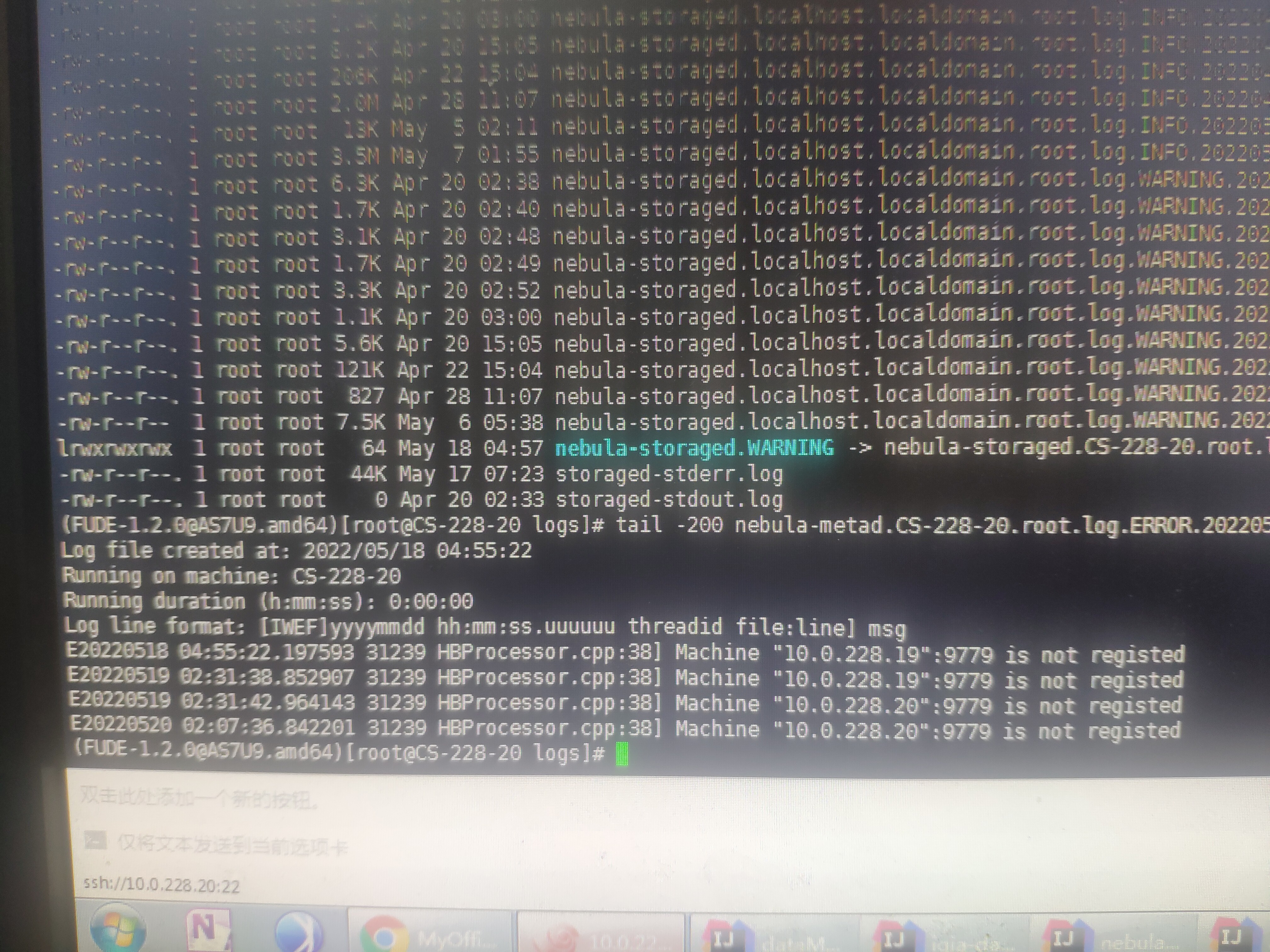
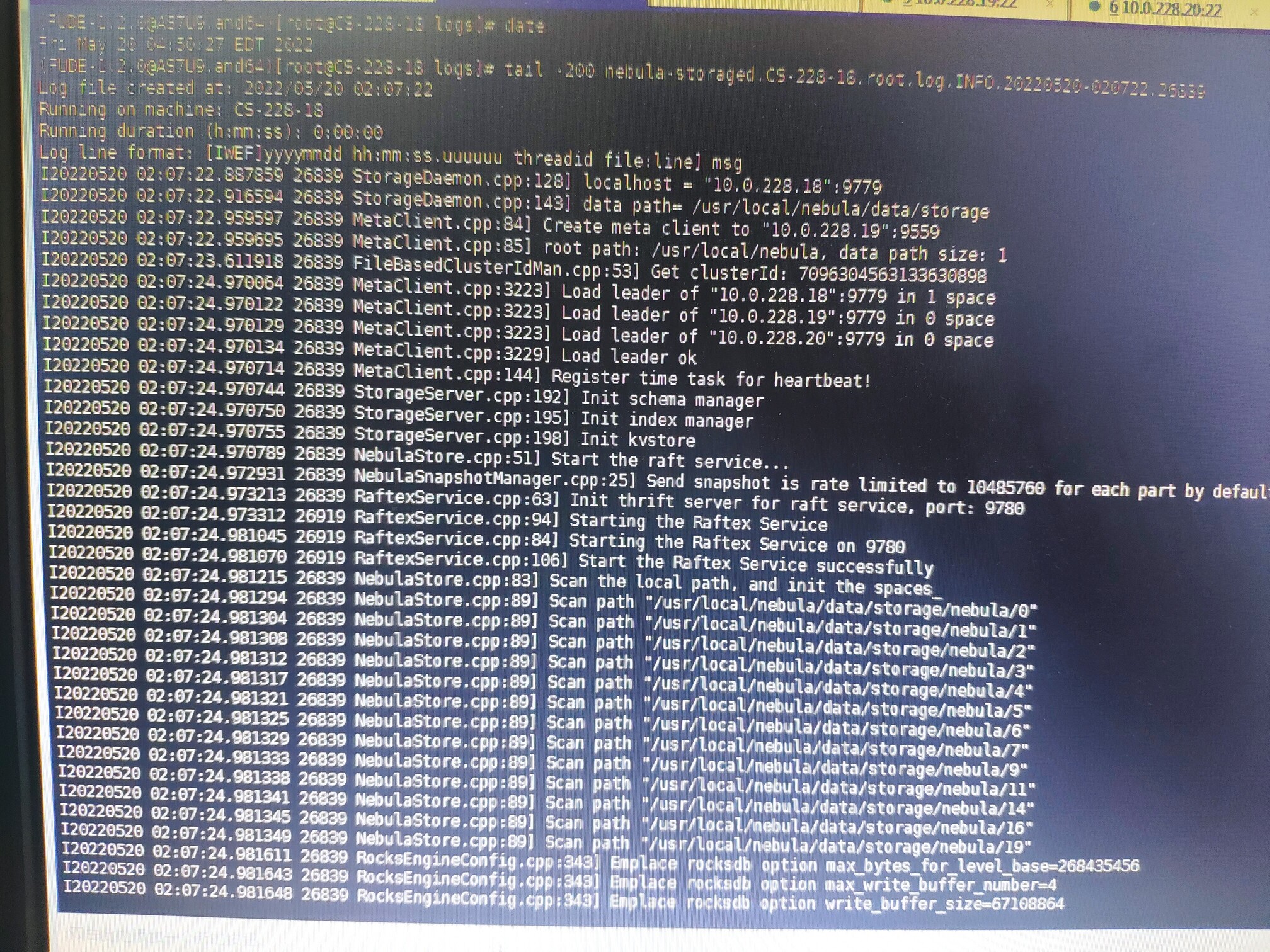
服务器系统的时间是错的。可以参考第一张图片的时间。date命令的时间s是May 5 04:50:27,Storaged INFO日志的时间是May 5 02:07:22,也就是说这是今天的日志。图片从上到下是一个完整的日志。环境原因,只能以这种方式贴一下日志,望见谅。
我看着启动没啥问题 这个时候会报E_RPC_FAILURE?
另外盘是HDD?
有个超时参数可以改大点 我猜要么query太大了 超时了
1 个赞
xjyou
17
启动的时候不会报E_RPC_FAILURE,查询的时候会报这个。
xjyou
19
调整了,只有一个超时参数session_redarm_interval_secs,由默认的10s调整为60s,还是一样的。现象就是:我在console查match(v:entity)return v limit 1; 然后卡住,然后报错E_RPC_FAILURE(-3)
steam
20
不是这个参数啊。storage_client_timeout_ms 这个调整下