- nebula 版本:3.1.0
- 部署方式:分布式
- 安装方式:RPM
- 是否为线上版本:Y
- 硬件信息
- 磁盘 300hdd
- CPU、内存信息 4c8g
- 问题的具体描述
大家好,初次使用nebula,查看相关GO语句文档后还不是很会,想问一下在nebula中如何使用GO语句查询如下结构:
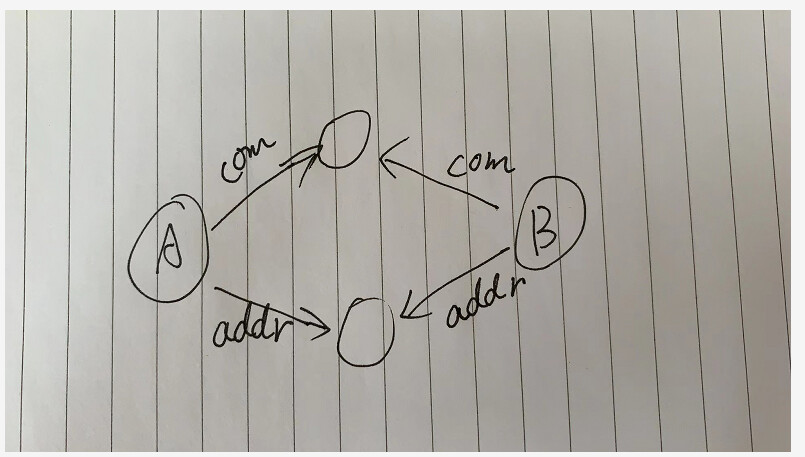
要求:
tag A 经过一些where条件过滤比如 time 是近30天
tag B 经过一些where条件过滤 time 大于60天
并且 A vid <> B vid,最后结果返回 A一列,B一列
大家好,初次使用nebula,查看相关GO语句文档后还不是很会,想问一下在nebula中如何使用GO语句查询如下结构:
要求:
tag A 经过一些where条件过滤比如 time 是近30天
tag B 经过一些where条件过滤 time 大于60天
并且 A vid <> B vid,最后结果返回 A一列,B一列
建议, 你可以先写下你觉得可行的语句,这样可以更有针对性地学习 nGQL。
你可以先写下你觉得可行的语句,这样可以更有针对性地学习 nGQL。
MATCH(A:acc)-[:com]->(attr:comtag)<-[:com]-(B:acc)
where A.time >= ‘2022-05-01 00:00:00’
and (B.time >=‘2022-04-01 00:00:00’ or B.timeflg=0)
and A.flgid=attr.flgid
and B.flgid = attr.flgid
and A.flgid = B.flgid
and A.accid <> B.accid
and (A)-[:addr]->(flgid:{attr.flgid})<-[:addr]-(B)
return distinct A,B
大致是这种match应该如何换成go语句?
GO FROM <A>/* 这里需要是id */ over com WHERE $^.acc.time >= "" yield e1._dst AS dst, $^.acc.flgid AS flgid
| GO FROM $-.dst OVER com REVERSELY WHERE $^.acc.time >= "" AND $^.acc.timeflg==0 AND $-.flgid=$$.comtag.flgid /*其他过滤属性同理*/ YIELD $-.src AS A, com._src AS B
UNION
/* 仿照上面的写法实现第二条路径的go */
你好,请问e1是什么?
就是 com,改成 com 就行应该是写错了
请问对于数据量比较大的查询应如何进行优化?因为GO语句后面必须跟的是vid,而业务场景下,是不确定vid的,需要初始进行一次LOOKUP查询,后续怎么能在使用GO语句的情况下做语句优化避免触发high watermark(0.8)
上述提及的语句我改写成
LOOKUP ON acc
WHERE acc .time >= ‘2022-05-01 00:00:00’
YIELD id(vertex) as Aid |
GO FROM $-.Aid
OVER com
WHERE properties($^).flgid == properties($$).flgid
YIELD DISTINCT dst(edge) as attrid, properties($$).flgid as flgid , $^ as A | /到这里能出结果2082条/
GO FROM $-.attrid
OVER com REVERSELY
WHERE $-.flgid == properties($$).flgid
AND id($-.A) <> id($$)
YIELD DISTINCT $-.A as A, $$ as B /到这里就报watermark(0.8)异常,并且尝试如果没有WHERE条件,并且YIELD edge起点或者终点可以查回结果,如果添加WHERE条件则不行/
增加watermark或者把watermark关掉
etc/nebula-graphd.conf:# System memory high watermark ratio, cancel the memory checking when the ratio greater than 1.0
etc/nebula-graphd.conf:–system_memory_high_watermark_ratio=0.8
查询优化
如果有超级顶点或出入度比较大,可以把max_edge_returned_per_vertex改小点,参考配置
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。