提问参考模版:
- nebula 版本:3.1
- 部署方式: 单机
- 安装方式: RPM
- 是否为线上版本 N
- 硬件信息
- 磁盘( 推荐使用 SSD) HDD
- CPU、内存信息
- 问题的具体描述
- 相关的 meta / storage / graph info 日志信息(尽量使用文本形式方便检索)
先使用client方式导入数据,查看正常。
然后使用SST方式导入数据,设置了spark的分区数为15,repartitionWithNebula: true,生成的SST文件一个文件夹里边是24个
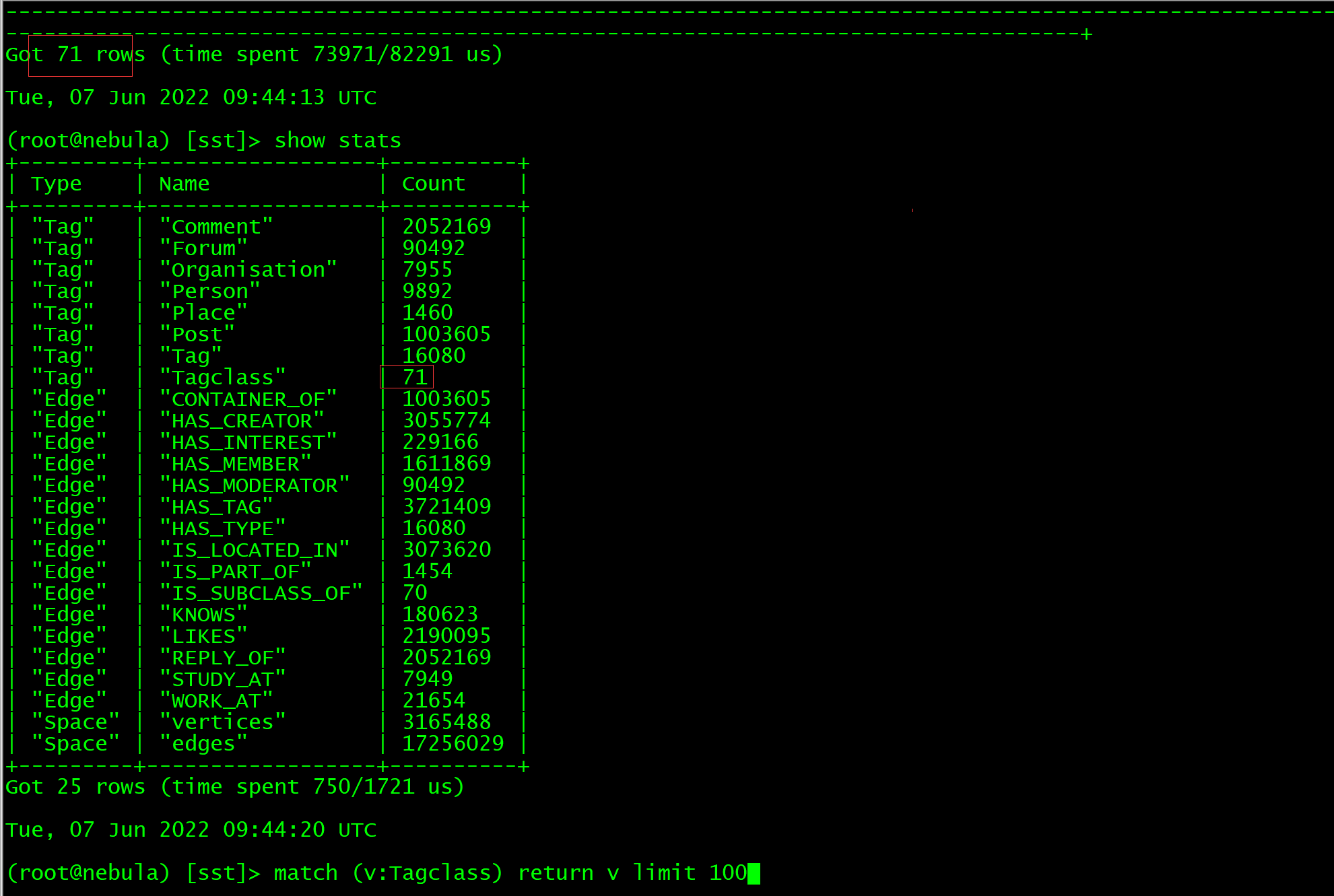
但是某些点查询不到,但是show stats的结果跟client方式的结果一样,数据量是对的。

我自己造的数据,email1一直到email900,但是只能查询到一部分。
这个该怎么排查呢。
没有创建全文索引,这是我直接新创建一个图,然后生成SST文件导入的。
您试试:
分别通过client和sst ingest方式。 fetch下,看看结果是否一样。。。先别用match
或者你ingest 完之后,rebuld index,然后用match 语句试试
使用fetch一样查询不到结果,rebuild index 提示我没有创建索引。

但是某些点查询不到,但是show stats的结果跟client方式的结果一样,数据量是对的。
client 和ingest这两种方式操作之前。环境都是干净的吗?
是的,show stats的结果是一致的,我第一次测试是在原图,clear space之后 再compact之后才导入的。
第二次直接创建了一个新图导入,两次结果都是一样的,都是某些点没有查询到
spark 我不熟悉哈。
然后使用SST方式导入数据,设置了spark的分区数为15,repartitionWithNebula: true,生成的SST文件一个文件夹里边是24个
你确定spart part个数和space里面的part个数一样吗
还有一个问题:我设置repartitionWithNebula: false之后,生成的SST文件变多了,直接360个,分区数已经设置15了,数据量不大才100多万,导入很慢,除了改这个repartitionWithNebula的配置还有什么办法降低呢。
repartitionWithNebula修改之前

repartitionWithNebula修改之后
这导入太慢了…
spark的分区数与part数没啥关系吧,因为我看了别的帖子有提到这个,最终生成的sst文件夹里边是15个,跟part个数一样,每个文件夹里边是24个,这个我就不知道原因了。
repartitionWithNebula 设置为true之后clear图库重新导入,点没了。。。
(root@nebula) [req_test1]> show stats
+---------+--------------------+---------+
| Type | Name | Count |
+---------+--------------------+---------+
| "Tag" | "address" | 0 |
| "Tag" | "company" | 0 |
| "Tag" | "email" | 0 |
| "Tag" | "idcard" | 0 |
| "Tag" | "ip" | 0 |
| "Tag" | "phone" | 0 |
| "Tag" | "reqno" | 0 |
| "Edge" | "addressid" | 100000 |
| "Edge" | "addressreqno" | 100000 |
| "Edge" | "companyid" | 100000 |
| "Edge" | "companyreqno" | 100000 |
| "Edge" | "emailid" | 100000 |
| "Edge" | "emailreqno" | 100000 |
| "Edge" | "idreqno" | 100000 |
| "Edge" | "ipid" | 100000 |
| "Edge" | "ipreqno" | 100000 |
| "Edge" | "phoneid" | 100000 |
| "Edge" | "phonereqno" | 100000 |
| "Edge" | "workaddressid" | 100000 |
| "Edge" | "workaddressreqno" | 100000 |
| "Edge" | "workphoneid" | 100000 |
| "Edge" | "workphonereqno" | 100000 |
| "Space" | "vertices" | 740065 |
| "Space" | "edges" | 1500000 |
+---------+--------------------+---------+
Got 24 rows (time spent 1218/2376 us)
但是vertexs有值,刚好还是对的值。。
建图语句如下:
DROP SPACE IF EXISTS req_test;
CREATE SPACE IF NOT EXISTS req_test1(partition_num=15, replica_factor=1, vid_type=FIXED_STRING(200));
USE req_test;
CREATE TAG idcard(name string, word string, num int64, isblack int64);
CREATE TAG reqno(word string, name string, num int64);
CREATE TAG email(word string, name string, num int64);
CREATE TAG phone(word string, name string, num int64);
CREATE TAG address(word string, name string, num int64);
CREATE TAG company(word string, name string, num int64);
CREATE TAG ip(word string, name string, num int64);
CREATE EDGE idreqno(word string, eventtime int64);
CREATE EDGE emailid(word string, eventtime int64);
CREATE EDGE phoneid(word string, eventtime int64);
CREATE EDGE workphoneid(word string, eventtime int64);
CREATE EDGE addressid(word string, eventtime int64);
CREATE EDGE workaddressid(word string, eventtime int64);
CREATE EDGE companyid(word string, eventtime int64);
CREATE EDGE ipid(word string, eventtime int64);
CREATE EDGE emailreqno(word string, eventtime int64);
CREATE EDGE phonereqno(word string, eventtime int64);
CREATE EDGE workphonereqno(word string, eventtime int64);
CREATE EDGE addressreqno(word string, eventtime int64);
CREATE EDGE workaddressreqno(word string, eventtime int64);
CREATE EDGE companyreqno(word string, eventtime int64);
CREATE EDGE ipreqno(word string, eventtime int64);
数据里边的vid,有固定的字符比如:email1,email2…email900,其他vid都是随机字符
随机字符不好验证,所以验证的固定字符,email100之后的vid都查询不到。
1 个赞
sst文件是在3.x版本中生成的吗?还是2.x中生成的sst,然后ingest到了3.1里?两个版本的数据格式不一样
用的最新的exchange,是3.0版本的,我贴个数据吧
email.csv (4.4 MB)
henry
17
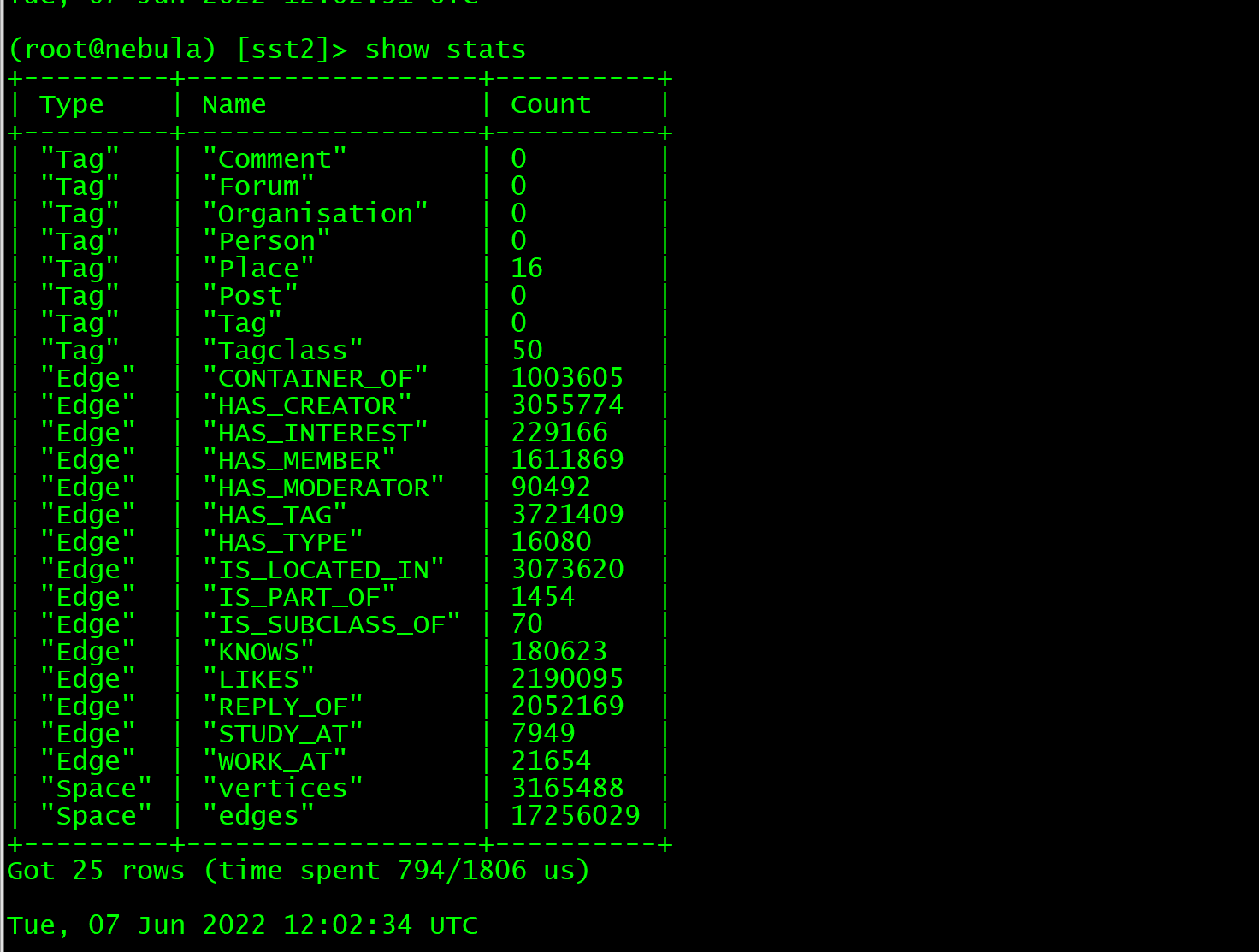
这个地方在确认下,是repartitionWithNebula设置为false时出现tag都是0的情况,如果是这是一个已知的issue会在之后修复,参考:
repartitionWithNebula 设置true ,sst文件少,统计信息正确,但是部分点查询不到
repartitionWithNebula 设置false ,sst文件多,统计信息节点为0
henry
19
之前那个repartitionWithNebula: true时缺数据这个问题我们尝试复现了,但没有碰到,所以麻烦把操作过程在描述下,看看在我们这里能否复现。
repartitionWithNebula: true
repartitionWithNebula: false
要不你用一下我的数据和schema尝试一下
exchange配置
{
name: email
type: {
source: csv
sink: sst
}
path: "hdfs://10.100.2.90:8020/user/graph_dev/nodeedge/email.csv"
fields: [_c1,_c2,_c3]
nebula.fields: [word,name,num]
vertex: {
field:_c0
# policy:hash
}
separator: ","
header: false
batch: 2560
partition: 32
repartitionWithNebula: true
}
跑出来的文件我自己执行命令下载下来放在指定的space id目录下,手动执行ingest导入
导入后查询,email1,email10,email500,email900这些点是否存在