nebula 版本:3.1.0
部署方式:分布式 ,replica=3,partition_num=15
硬件信息 :3台4核cpu、16G内存、256G ssd
问题的具体描述:
测试环境中发现有一个namespace下执行一些简单的lookup查询特别慢,大概需要200ms,而其他namespace中执行同样的查询都不会超过10ms,性能相差了几十倍吧。ngql语句示例如下:
lookup on Site where Site.id == “xxx” yield Site.name
后来进行了各种排查,最终发现虽然这个namesapce下的数据总量并不多,只有几百万个顶点,但查询速度慢和这个namespace下索引个数太多有直接关系。
为了排除其他因素的干扰,下面新建一个namespace,做一些对比试验。
首先在这个namespace中创建10000个Tag类型,但是只为其中一个类型建立索引,并对这个类型创建100万个顶点,然后执行以下查询:
lookup on Site0 where Site0.id == “id0” yield Site0.name
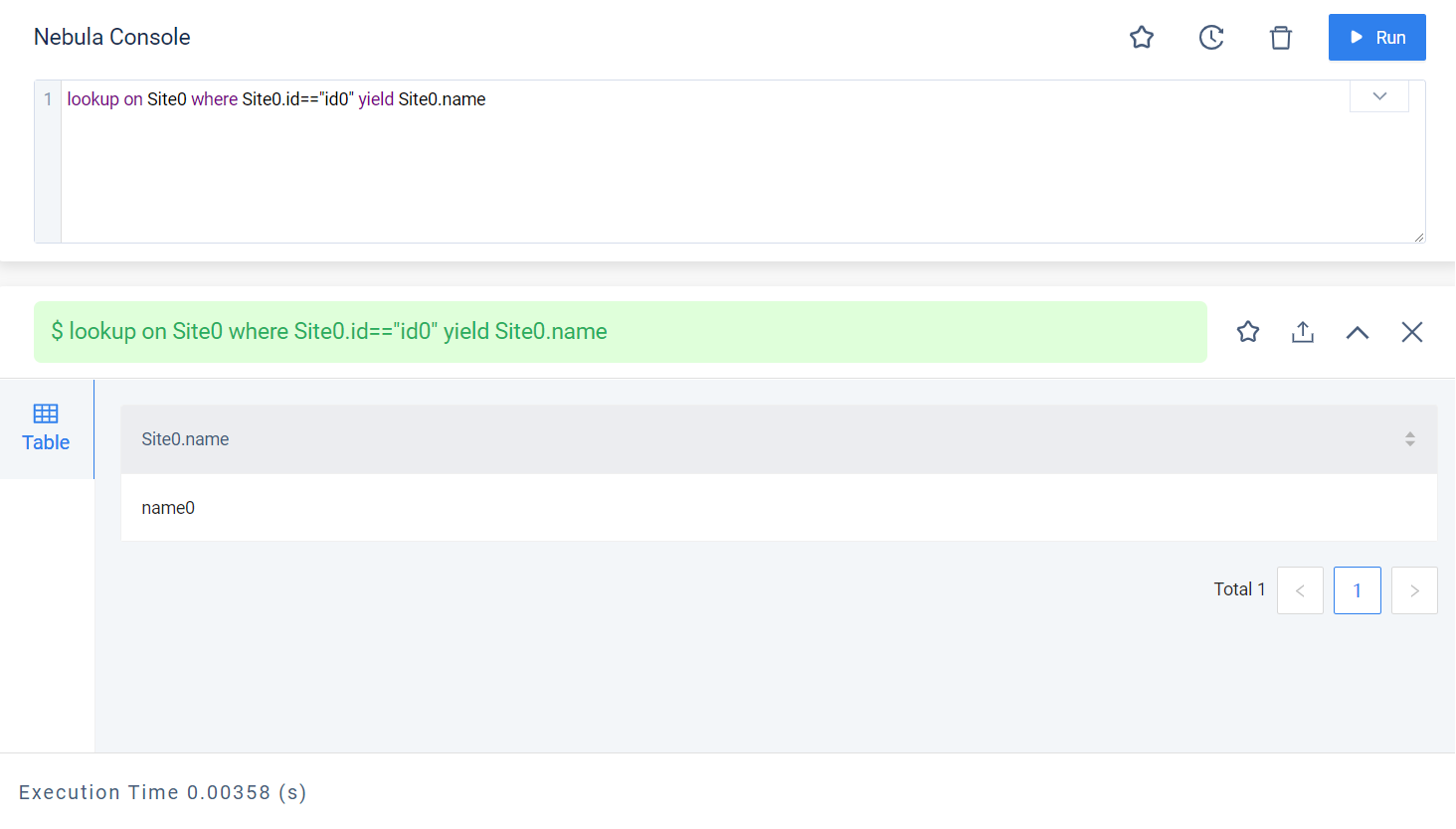
可以看到此时查询在服务端执行速度非常快,只耗时3ms。
然后为其他的每个Tag类型也都创建一个索引,总共10000个索引,但并不插入任何数据,可以认为其他9999个索引都是空索引。此时再执行前面的查询操作。
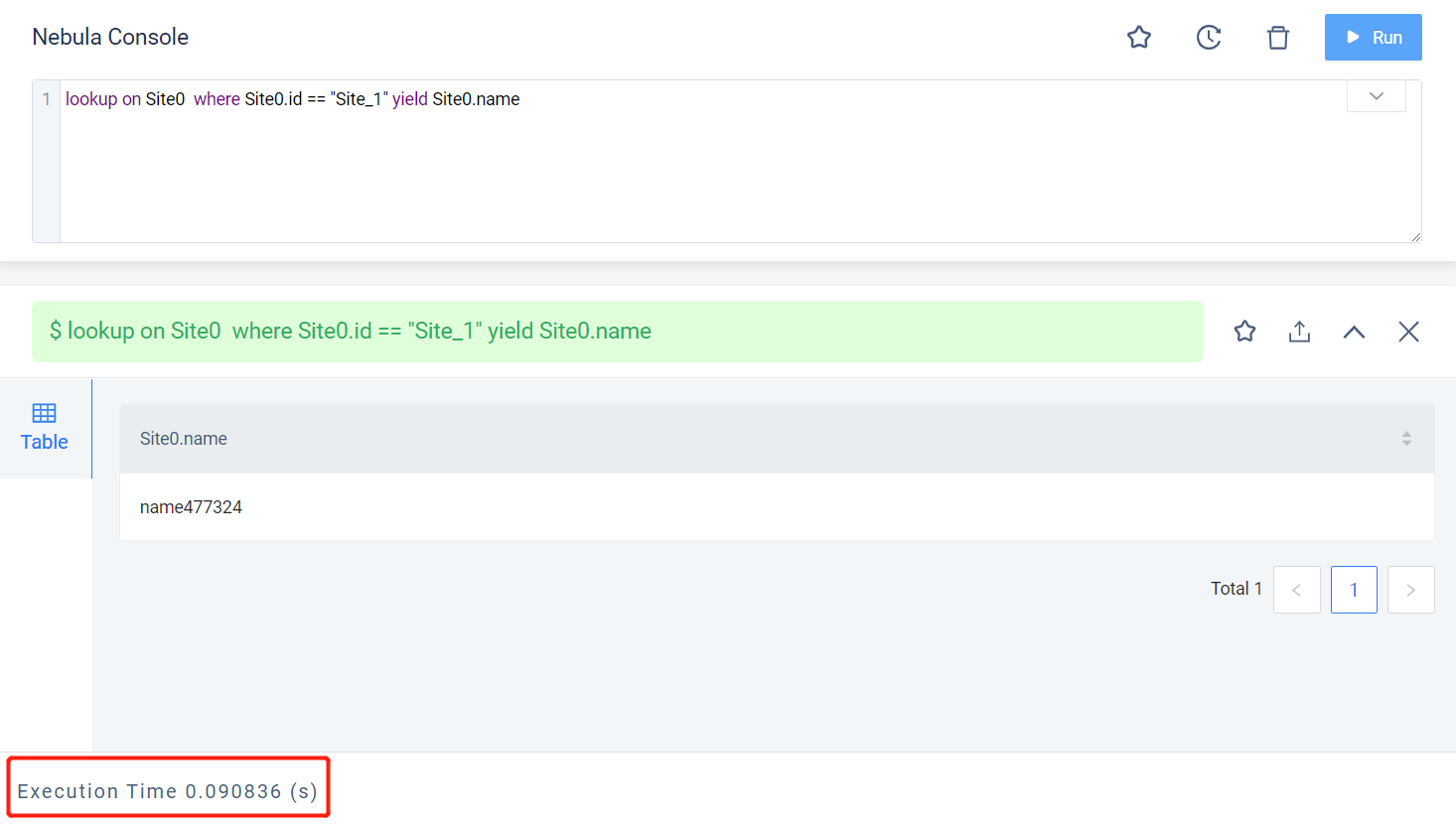
可以看到此时查询在服务端耗时已经高达90ms,但和之前唯一的变化只是多创建了9999个空索引
继续为每个Tag类型再创建一个索引,总共20000个索引,仍旧不插入任何数据,再执行前面的查询:
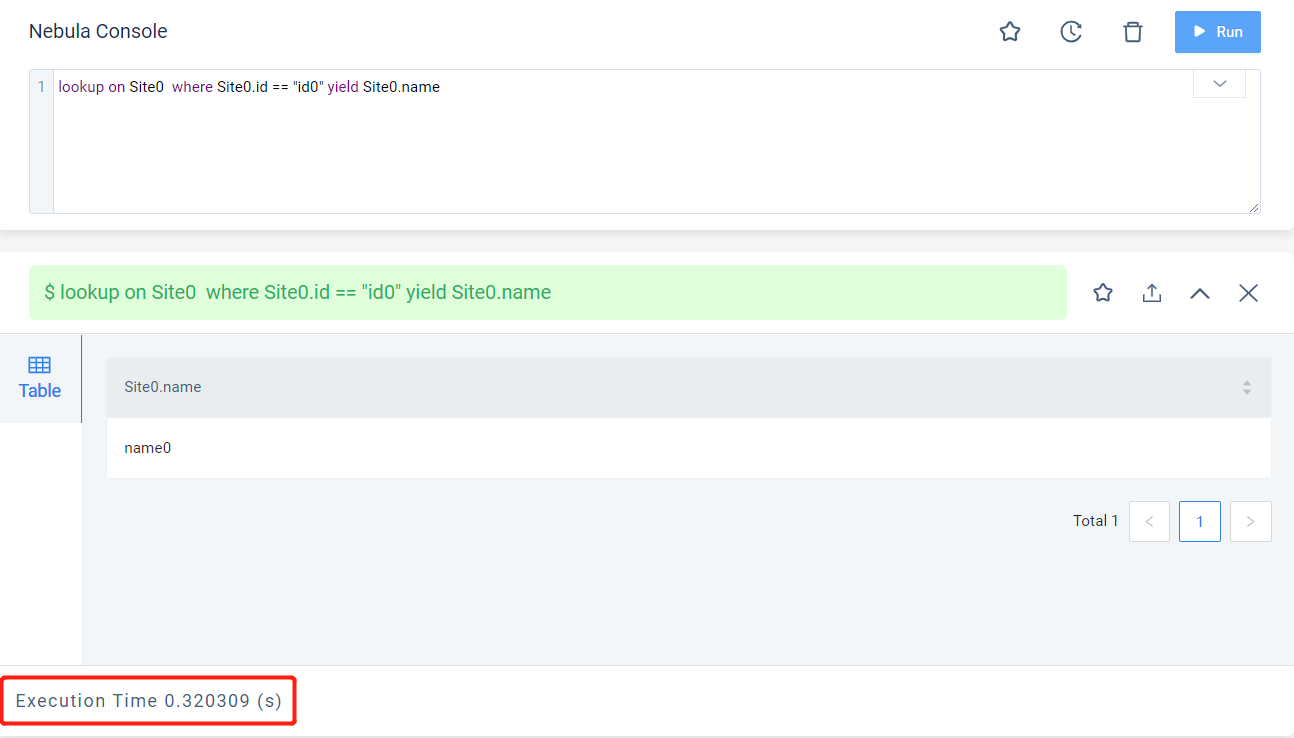
可以看到此时查询在服务端耗时高达320ms,耗时已经变成最初3ms的100倍了
通过profile命令分析执行计划:
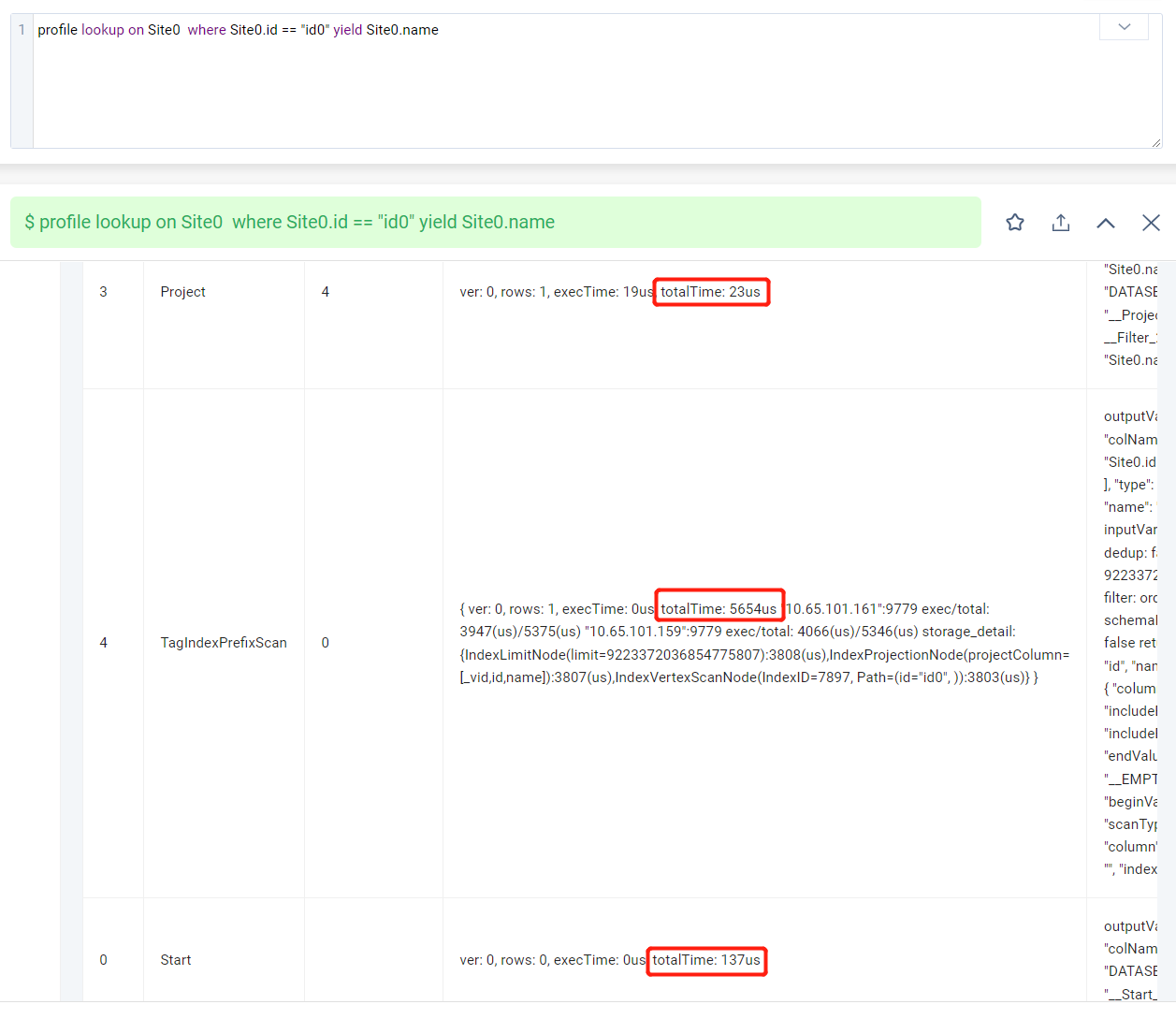
可以看到图中的三步执行步骤都执行得很快,加起来也才不到6ms,和整体的320ms相差甚远。其中最关键的TagIndexPrefixScan这步也只耗时5654us。
下面来分析下nebula中点的索引的存储结构,如下图所示:

其中indexId是索引的唯一标识,index binary 是将所有 index column 的属性值编码连接存储的字段。
lookup查询语句一是要解析查询的字段,匹配对应的indexId以及索引的其他元数据,二是通过字段拼接直接得到index binary,然后通过PartitionId+IndexId+index binary来前缀匹配获取VertexId,这步对应TagIndexPrefixScan,图中只耗时5654us,执行是非常快的。
执行过程中唯一可能和索引数量有关的,应该就是通过查询的字段匹配对应的indexId以及索引的其他元数据这步了,不太清楚这部分逻辑是怎么实现的,是不是存在一些性能问题,官方后续能否进行优化?
上述测试中虽然创建了上万个索引,但是大部分都是空索引,所以实际的数据量其实很少。但即使创建的是空索引,查询性能还是受到了显著的影响,这个结果是让人有点难以接受的。
最后想问下这块查询慢的具体原因是什么?如果和前面猜测的一致,是不是存在优化的办法?
 ,在存储的同学们回答您之前,我好奇您的场景下 TAG 数量真的需要这么大么?另外,查询一定是需要索引的对么?有没有可能通过拼接常用查询条件为 vid 的方式绕过索引依赖?
,在存储的同学们回答您之前,我好奇您的场景下 TAG 数量真的需要这么大么?另外,查询一定是需要索引的对么?有没有可能通过拼接常用查询条件为 vid 的方式绕过索引依赖?
