充足的信息能提高解决问题的速度
提问之前,记得在【本论坛】和【文档】下搜索是否已有解决方案存在哟 ^^
为了更快地定位、解决问题,麻烦参考下面模版提问(不符合提问规范的问题,会被隐藏待补充相关信息之后再发布)
提问参考模版:
- nebula 版本:(为节省回复者核对版本信息的时间,首次发帖的版本信息记得以截图形式展示)
- 部署方式:分布式
- 安装方式:tar.gz
- 是否为线上版本: N
- 硬件信息 虚拟机
- 磁盘
- CPU 16核 、内存信息 可用256g
- 问题的具体描述
请问
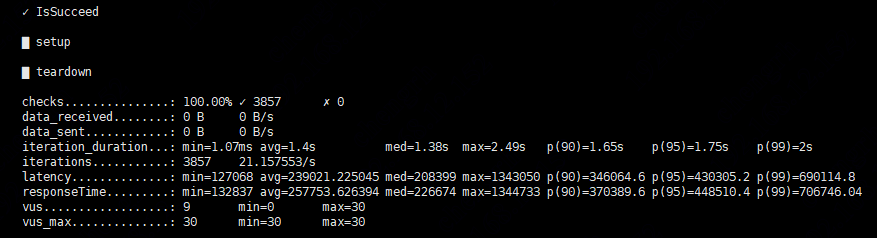
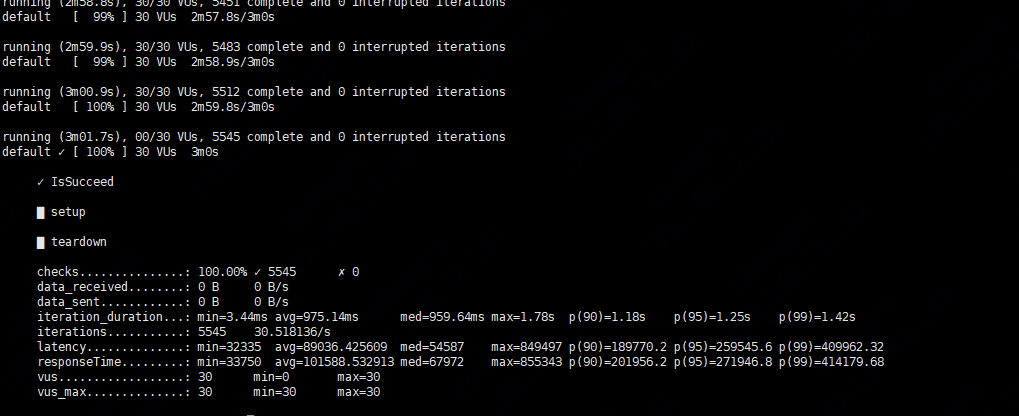
我使用 nebula-importer 导入测试数据集(k6生成的数据集 2000万行),space 30个分区,副本为1
最终消耗 50s 全部导入,这么计算的话 qps:400000
可是 使用k6测试 插入点 batch-size 10000 并发 10,qps为 148000
插入边 batch-size 10000 并发 10,qps为 219000
无论插入点还是插入边 的性能 都达到不了 nebula-importer 的插入数据性能
问题 :nebula-importer 的并发数是多少? 什么导致了插入点还是插入边 的性能 都达到不了 nebula-importer 的插入数据性能?