- nebula 版本:v.3.1.0
- 部署方式:分布式
- 安装方式:K8S (meta3, graph3, storage*3)
- 是否为线上版本:Y
- 硬件信息
- 磁盘 800G SSD
- CPU 、内存信息 64cores128G
- 导入SF100数据(num_partitions=24, replicas=3)后,通过k6进行多跳的测试 (go 2 steps from {} over knows yield dst(edge),),在QPS=100的情况下,二跳返回的latency如下
latency..............: avg=4743680.659449 min=1216 med=4332954 max=30955973 p(90)=8473740.8 p(95)=10153952.6
因此有如下问题:
- 通过资源监控 每个storaged 的CPU使用~2cores,内存~11G,可见资源未被完全利用下性能较慢,CPU使用率是否有方式调整?
- 导入过程中发现,一部分数据的tagid丢失(整体数据量正确),是否会影响多跳查询效率?
多谢,期待回复 
1 个赞
1、可以同时监控一下,网络,磁盘IO,综合来看 瓶颈出现在哪里
2、部分数据缺失 和 多跳查询效率没有关系,除非缺失的数据正好是 要查询的数据,会造成查找不到
1 个赞
go 2 steps from {} over knows yield dst(edge)
改成go 2 steps from {} over knows yield knows._dst试试
1 个赞
多谢回复,修改查询语句后,有显著提升,可以麻烦解释下原因吗?
avg=898347.51358 min=869 med=700645.5 max=11541728 p(90)=1884146.6 p(95)=2439667.55
dst(edge) 会取 schema中所有边的属性,
knows._dst 只会取 knows边中的 dst 属性
还有就是partition_num我觉得可以适当调大,磁盘的20倍,咱3个SSD就设置成60,性能应该还能提升一些,另外第一个问题,2跳查询的话我认为资源都用在graphd上,storaged恐怕不会消耗太多。如果性能还需继续优化的话建议把stroage的配置贴出来看看
1 个赞
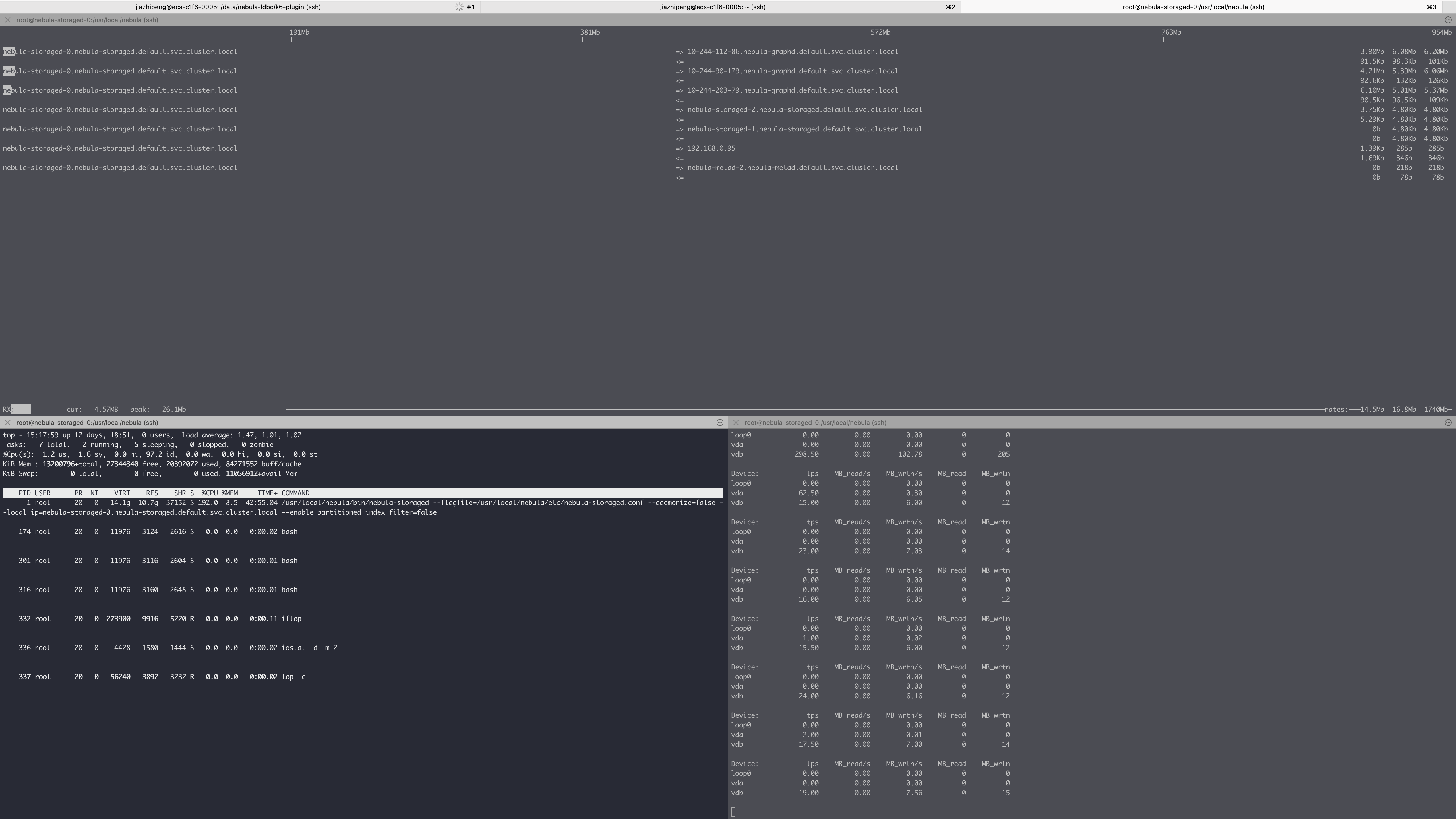
感谢回复,上图收集到的对应的cpu/io/网络的监控数据,以及在测试过程通过console,对一条查询做对应的profiling的结果,我自己分析
- CPU和磁盘IO都不算高,但是相对来说是不是网络比较慢?
- 在profiling的结果里一跳GetNeighbors时total_rpc_time: 998(us),二跳GetNeighbors时 total_rpc_time: 769697(us),是否说明耗时为graph和storage之间?
storage的配置如下,多谢
check_plan_killed_frequency=8
cluster_id_path="cluster.id"
expired_time_factor=5
failed_login_attempts=0
heartbeat_interval_secs=10
meta_client_retry_interval_secs=1
meta_client_retry_times=3
meta_client_timeout_ms=60000
password_lock_time_in_secs=0
storage_client_retry_interval_ms=1000
storage_client_timeout_ms=60000
log_disk_check_interval_secs=10
log_min_reserved_bytes_to_error=67108864
log_min_reserved_bytes_to_fatal=4194304
log_min_reserved_bytes_to_warn=268435456
containerized=0
system_memory_high_watermark_ratio=0.8
gflags_mode_json="share/resources/gflags.json"
ca_path=""
cert_path=""
enable_graph_ssl=0
enable_meta_ssl=0
enable_ssl=0
key_path=""
password_path=""
conn_timeout_ms=1000
timezone_file="share/resources/date_time_zonespec.csv"
timezone_name="UTC+00:00:00"
redirect_stdout=1
stderr_log_file="stderr.log"
stdout_log_file="stdout.log"
daemonize=0
data_path="data/storage"
listener_path=""
local_ip="nebula-storaged-0.nebula-storaged.default.svc.cluster.local"
meta_server_addrs="nebula-metad-0.nebula-metad.default.svc.cluster.local:9559,nebula-metad-1.nebula-metad.default.svc.cluster.local:9559,nebula-metad-2.nebula-metad.default.svc.cluster.local:9559"
pid_file="pids/nebula-storaged.pid"
wal_path=""
disk_check_interval_secs=10
minimum_reserved_bytes=1073741824
ft_bulk_batch_size=100
ft_request_retry_times=3
listener_commit_batch_size=1000
listener_commit_interval_secs=1
listener_pursue_leader_threshold=1000
snapshot_batch_size=524288
snapshot_part_rate_limit=10485760
auto_remove_invalid_space=1
clean_wal_interval_secs=600
custom_filter_interval_secs=86400
engine_type="rocksdb"
num_workers=4
cluster_id=0
skip_wait_in_rate_limiter=0
balance_expired_sesc=86400
move_files=0
cache_bucket_exp=8
disable_page_cache=0
enable_partitioned_index_filter=0
enable_rocksdb_prefix_filtering=1
enable_rocksdb_statistics=1
enable_rocksdb_whole_key_filtering=0
num_compaction_threads=0
rocksdb_backup_dir=""
rocksdb_backup_interval_secs=300
rocksdb_batch_size=4096
rocksdb_blob_compression="snappy"
rocksdb_block_based_table_options="{"block_size":"8192"}"
rocksdb_block_cache=4
rocksdb_bottommost_compression="disable"
rocksdb_column_family_options="{"write_buffer_size":"67108864","max_write_buffer_number":"4","max_bytes_for_level_base":"268435456"}"
rocksdb_compact_change_level=1
rocksdb_compact_target_level=-1
rocksdb_compression="lz4"
rocksdb_compression_per_level=""
rocksdb_db_options="{}"
rocksdb_disable_wal=1
rocksdb_enable_blob_garbage_collection=1
rocksdb_enable_kv_separation=0
rocksdb_kv_separation_threshold=100
rocksdb_rate_limit=0
rocksdb_row_cache_num=16000000
rocksdb_stats_level="kExceptHistogramOrTimers"
rocksdb_table_format="BlockBasedTable"
rocksdb_wal_dir=""
rocksdb_wal_sync=0
max_appendlog_batch_size=128
max_outstanding_requests=1024
raft_rpc_timeout_ms=500
max_batch_size=256
raft_heartbeat_interval_secs=30
raft_snapshot_timeout=300
trace_raft=0
snapshot_io_threads=4
snapshot_send_retry_times=3
snapshot_send_timeout_ms=60000
snapshot_worker_threads=4
wal_buffer_size=8388608
wal_file_size=16777216
wal_sync=0
wal_ttl=14400
default_mvcc_ver=0
max_edge_returned_per_vertex=2147483647
query_concurrently=0
reader_handlers=32
reader_handlers_type="cpu"
rebuild_index_batch_size=131072
rebuild_index_part_rate_limit=524288
store_type="nebula"
trace_toss=0
waiting_catch_up_interval_in_secs=30
waiting_catch_up_retry_times=30
waiting_new_leader_interval_in_secs=5
waiting_new_leader_retry_times=5
local_config=0
num_io_threads=16
num_worker_threads=32
port=9779
storage_http_thread_num=3
storage_kv_mode=0
max_concurrent_subtasks=10
resume_interval_secs=10
toss_worker_num=16
ws_http_port=19779
ws_ip="0.0.0.0"
ws_threads=4
codel_enabled=0
thrift_cpp2_protocol_reader_container_limit=0
thrift_cpp2_protocol_reader_string_limit=0
thrift_server_request_debug_log_entries_max=10000
service_identity=""
thrift_abort_if_exceeds_shutdown_deadline=1
thrift_ssl_policy="disabled"
folly_memory_idler_purge_arenas=1
dynamic_cputhreadpoolexecutor=1
codel_interval=100
codel_target_delay=5
dynamic_iothreadpoolexecutor=1
threadtimeout_ms=60000
observer_manager_pool_size=4
logging=""
folly_hazptr_use_executor=1
flagfile="/usr/local/nebula/etc/nebula-storaged.conf"
fromenv=""
tryfromenv=""
undefok=""
tab_completion_columns=80
tab_completion_word=""
help=0
helpfull=0
helpmatch=""
helpon=""
helppackage=0
helpshort=0
helpxml=0
version=0
alsologtoemail=""
alsologtostderr=0
colorlogtostderr=0
drop_log_memory=1
log_backtrace_at=""
log_dir="logs"
log_link=""
log_prefix=1
log_utc_time=0
logbuflevel=0
logbufsecs=0
logemaillevel=999
logfile_mode=436
logmailer=""
logtostderr=0
max_log_size=1800
minloglevel=0
stderrthreshold=0
stop_logging_if_full_disk=0
timestamp_in_logfile_name=1
symbolize_stacktrace=1
v=4
vmodule=""
zlib_compressor_buffer_growth=2024
s2shape_index_cell_size_to_long_edge_ratio=1
s2shape_index_default_max_edges_per_cell=10
s2shape_index_tmp_memory_budget_mb=100
s2cell_union_decode_max_num_cells=1000000
s2debug=0
s2loop_lazy_indexing=1
s2polygon_decode_max_num_vertices=50000000
s2polygon_decode_max_num_loops=10000000
s2polygon_lazy_indexing=1
dcache_unit_test=0
有几个参数需要调整
rocksdb_block_cache=32768(BlockBasedTable 的默认块缓存大小,这个参数配置了storage内存使用率会上来)
rocksdb_enable_kv_separation=true (是否启用 BlobDB KV 分离存储功能。开启后可以提高查询性能,但是需要做一次compaction,按需调整吧)
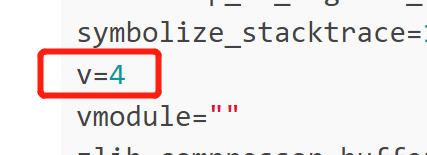
这个是日志级别,如果不做调试设置成0,4的话记录太多日志会影响查询性能
2 个赞
query_concurrently改成true试试 
partition的数目
这个问题比较复杂,跟数据量、并发量都有关系,举个例子,一个query发过来,如果我的partition数目是60,而我cpu的总cores大于60,那我可以用60个线程去取数据,同理partition数量越大,只要不超过总cores数那理论上我取数据的速度就越快,但是这只是一个query,如果高并发情况partiton数量多了反而会造成线程排队,导致性能下降。所以还是要看具体的业务场景。磁盘数量的20倍是一个建议值,可以满足大部分的场景。
日志这块因为设计容器我不是很擅长,需要其他大佬帮忙看下
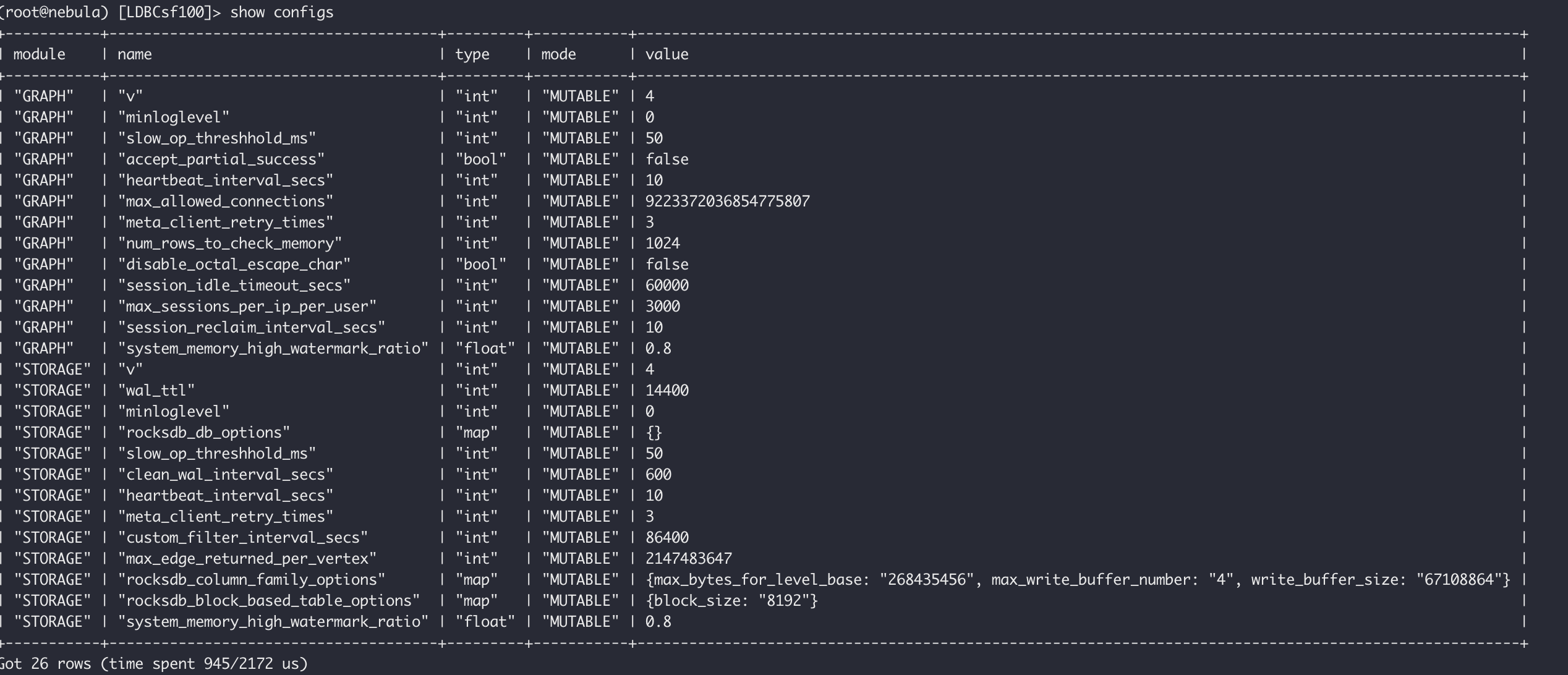
graph和storage的配置会保存在metad里,文件配置会被本地配置覆盖,你用show configs看看实际的v是多少,update一下就行了。
再麻烦请教一下,再修改日志的输出级别之后,有显著提升,如下
avg=5099.330122 min=479 med=3638 max=67686 p(90)=10445.5 p(95)=14385.75
但是这里提到的另外两个参数调整后,测试并无显著变化,同时内存大小也并无变化,我看我们的文档里对于内存的计算方式如下
- rocksdb_block_cache 这个是用于调整block cache的大小,不会影响bloom filter的内存使用情况?因此如果调整后没变化的话?是不是说明这个参数没生效?是和刚提到的meta存储的配置信息有关吗?但是通过console并未查看到对应的配置信息
- 上述的内存计算方式里提到的点边数量是针对全量数据计算的?还是针对当前节点持有的leader分区计算?感觉是前者,因为leader切换不影响内存用量,但是全量数据的话,大小又对不上
不会影响bloom filter,block_cache其实就是缓存,这个设置了之后执行query会有一部分数据被缓存掉,所以变化可能不会那么显著。我一般是靠这个命令看配置的curl 127.0.0.1:19779/flags
针对全量数据,这个内存的计算方式是建议值。
1 个赞
1.是的,缓存数据用的
2.跟block cache没有关系,是bloomfilter的数据
1 个赞
system
关闭
19
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。