- nebula 版本:2.6.1(为节省回复者核对版本信息的时间,首次发帖的版本信息记得以截图形式展示)
- 部署方式: 集群
- 安装方式:RPM
- 是否为线上版本:N
- 硬件信息
- 问题的具体描述: importor导入数据出现oom,修改生产环境下的配置后storaged起不来,数据量500G,集群有三台机器,都作为meta,graph和storage
- 相关的 meta / storage / graph info 日志信息(尽量使用文本形式方便检索)
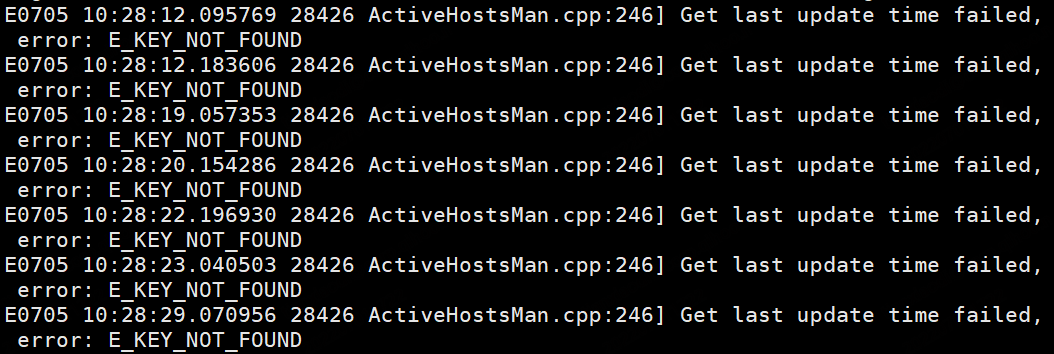
nebula-metad.ERROR:
nebula-storaged.ERROR
如果有日志或者代码,记得用 Markdown 语法(下面语法)包裹它们提高阅读体验,让回复者更快解决问题哟~~
代码 / 终端输出 / 日志…
最后烦请删掉本模版和问题无关的信息之后,再提交提问,Thx
是不是以前加入过别的集群呢?集群cluster不对,建议清理相关的环境。
如果修改配置,可能是配置影响了集群id
比如meta地址之类的
1 个赞
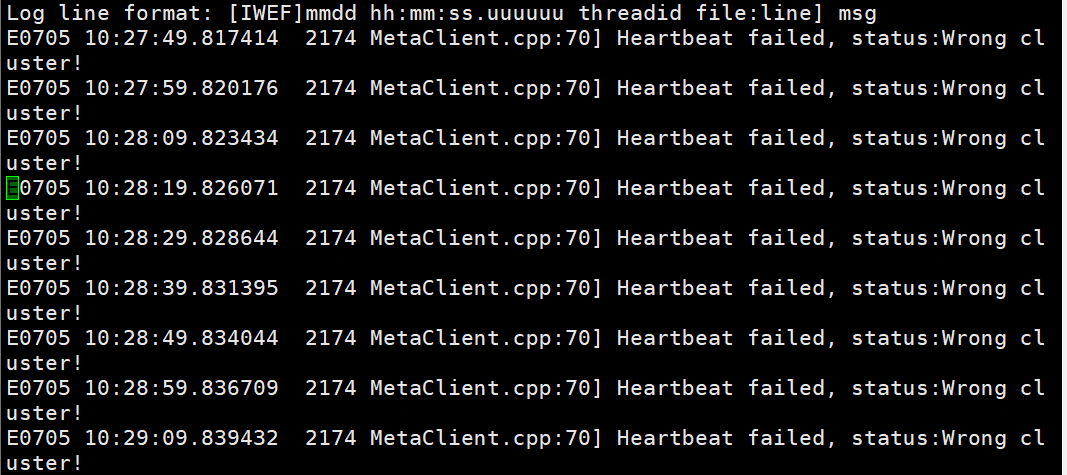
nebula-graphd.ERROR:
Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg
E0705 10:16:06.866331 32589 MetaClient.cpp:636] Send request to “xxxxxx”:9559, exceed retry limit
E0705 10:16:06.866737 32577 MetaClient.cpp:94] RPC failure in MetaClient: N6apache6thrift9transport19TTransportExceptionE: AsyncSocketException: connect failed, type = Socket not open, errno = 111 (Connection refused): Connection refused
E0705 10:16:06.866784 32577 GraphService.cpp:43] Failed to wait for meta service ready synchronously.
E0705 10:16:06.866817 32577 GraphDaemon.cpp:158] Failed to wait for meta service ready synchronously.
我重新安装nebula-graph了,不管用,怎么清理环境呢,meta地址没变过,就是之前都用的etc下的conf.default,现在都换成conf.production了
删除安装目录的cluster.id解决了问题,谢谢
您好,我点和边数据大小共100G(14亿节点和边),部署的3个机器的集群,importer导入数据过程中每个机器安装目录下的data都900G,目前导入了1/3,照这样子下去磁盘肯定撑不住(共1.5T),请问是我哪里设置的不对吗,需要怎么调整一下呢
1 个赞
可以试试把wal_ttl时间减少一点
如果是过量日志也可以检查一下,定期删除
system
关闭
8
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。