提问参考模版:
- nebula 版本:3.1.0
- 部署方式:分布式
- 安装方式:Docker
- 是否为线上版本:Y
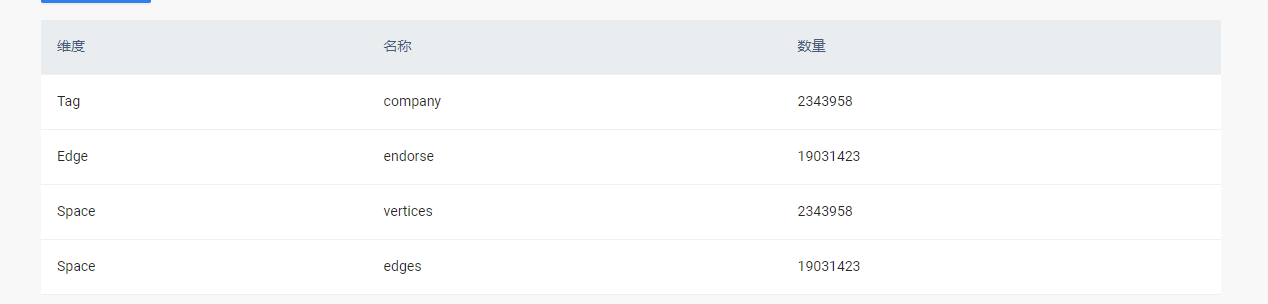
- 硬件信息
meta1- CPU:请求1核 限制1.5核 内存:请求512m 限制2g
meta2- CPU:请求1核 限制1.5核 内存:请求512m 限制2g
meta3- CPU:请求1核 限制1.5核 内存:请求512m 限制2g
graph1- CPU:请求1核 限制1.5核 内存:请求2g 限制4g
graph2- CPU:请求1核 限制1.5核 内存:请求2g 限制4g
storage1-CPU:请求1核 限制1.5核 内存:请求512m 限制2g
storage2-CPU:请求1核 限制1.5核 内存:请求512m 限制2g
每台机子都单独挂载了200m的数据盘 - 问题的具体描述
执行NGQL数据返回正常
MATCH p=(v1:company{name:"金科地产集团股份有限公司"})-[e:endorse*1..3]->(v2:company{name:"江苏天力建设集团有限公司"}) RETURN p
改为
···
MATCH p=(v1:company{name:“金科地产集团股份有限公司”})-[e:endorse*]->(v2:company{name:“江苏天力建设集团有限公司”}) RETURN p
···
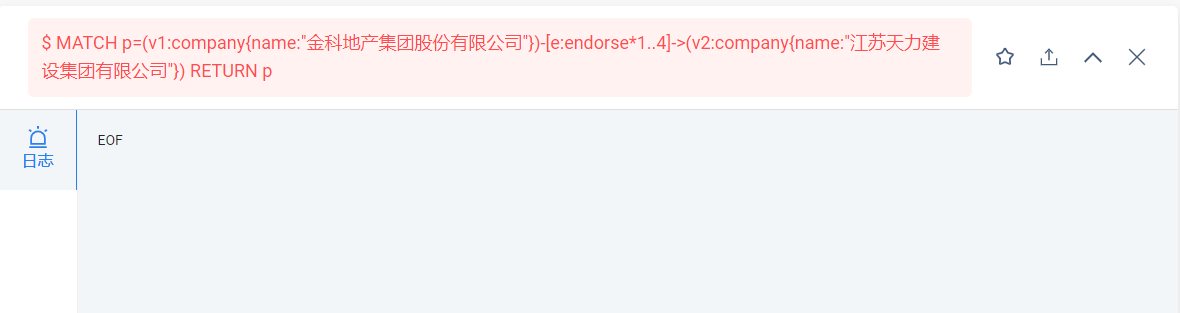
直接导致graph服务挂掉
- 相关的 graph ERROR日志
E20220712 11:24:48.196960 21 Serializer.h:43] Thrift serialization is only defined for structs and unions, not containers thereof. Attemping to serialize a value of type `nebula::Value`.