- nebula 版本:v3.1.0
- 部署方式:单机
- 安装方式:Docker
- 是否为线上版本: N
- 硬件信息
- 磁盘:SSD
- CPU、4.8g,Ubantu20,i7
- 问题的具体描述
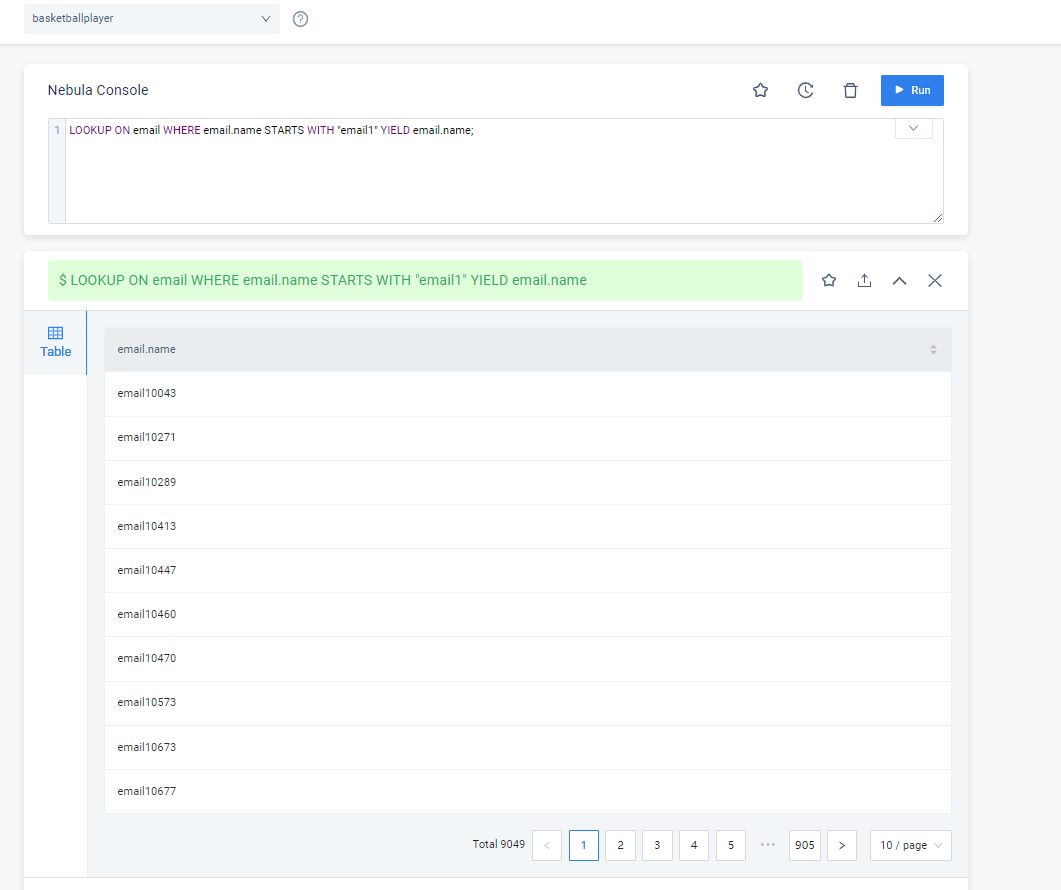
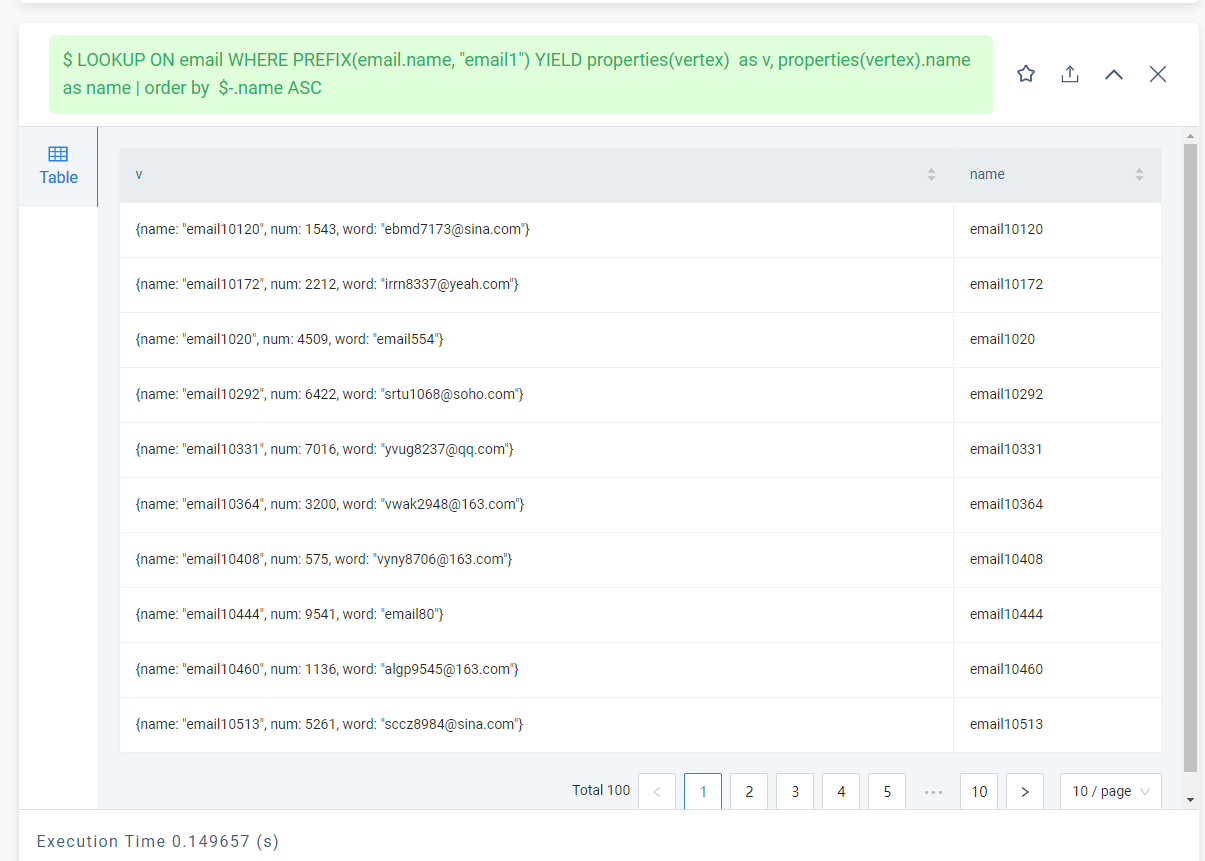
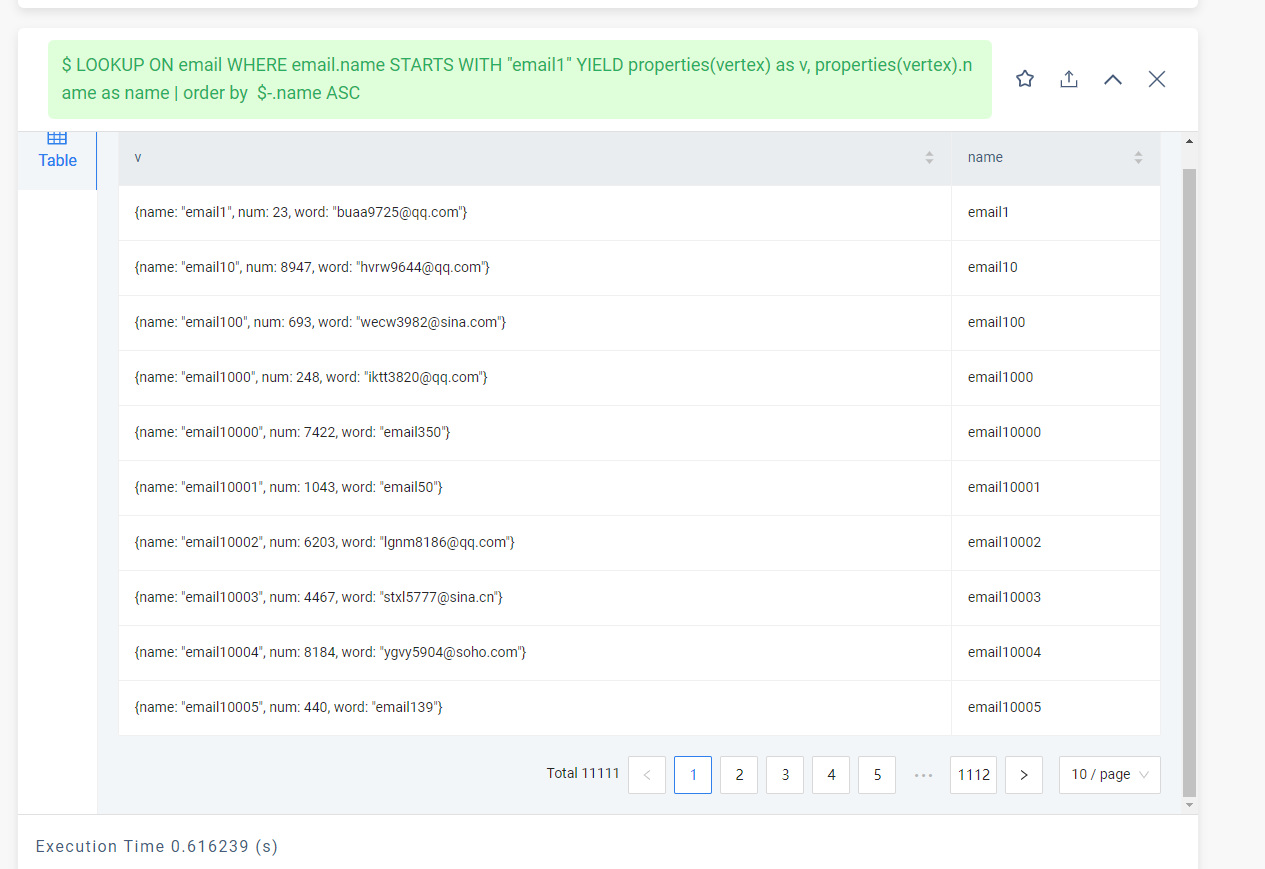
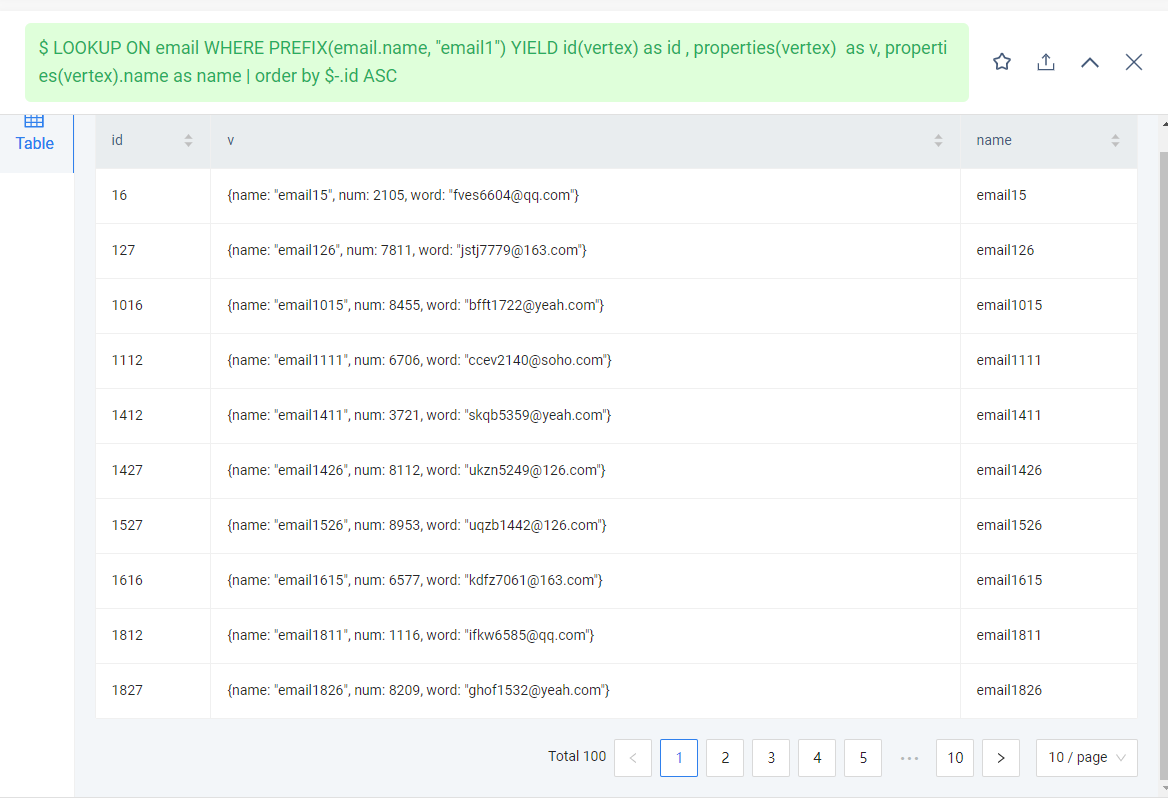
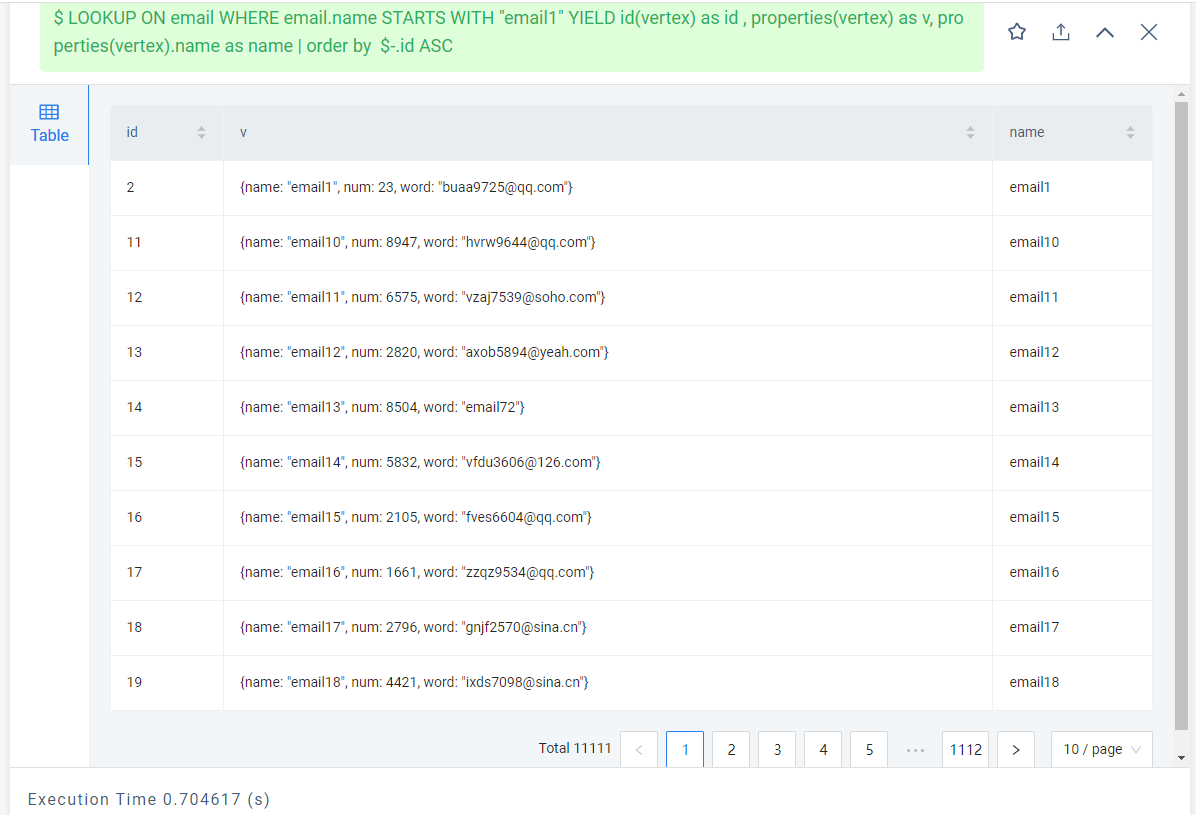
创建了同样的数据,不同的图空间,普通索引返回的数据量是全文索引的100倍左右
CREATE SPACE `test` (vid_type = FIXED_STRING(30)) ;
USE `test`;
CREATE TAG email(word string, name string, num int64);
CREATE TAG INDEX IF NOT EXISTS email_index ON email(name(30));
REBUILD TAG INDEX;
CREATE FULLTEXT TAG INDEX `nebula_email_index` on `email`(`name`)
REBUILD FULLTEXT index;
导入数据
email.csv (4.4 MB)
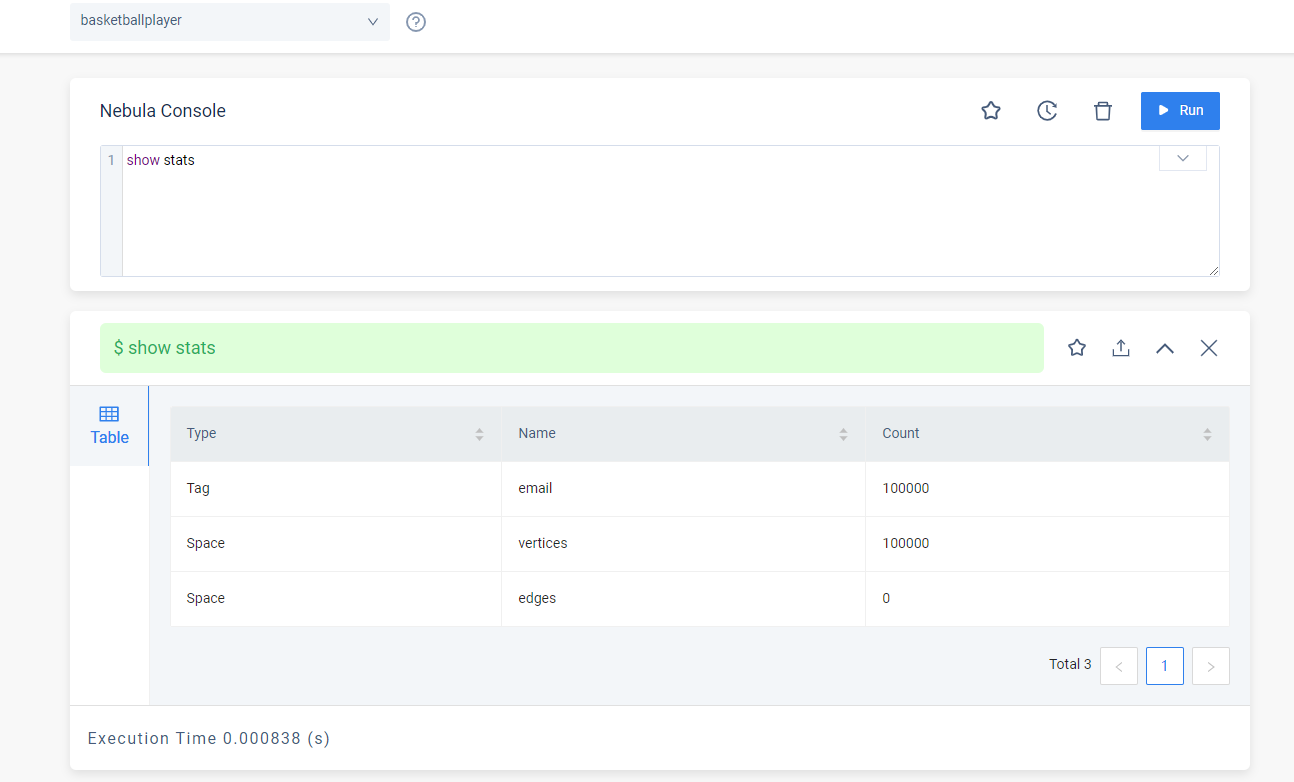
导入10万数据,show stats 只有 8万多条
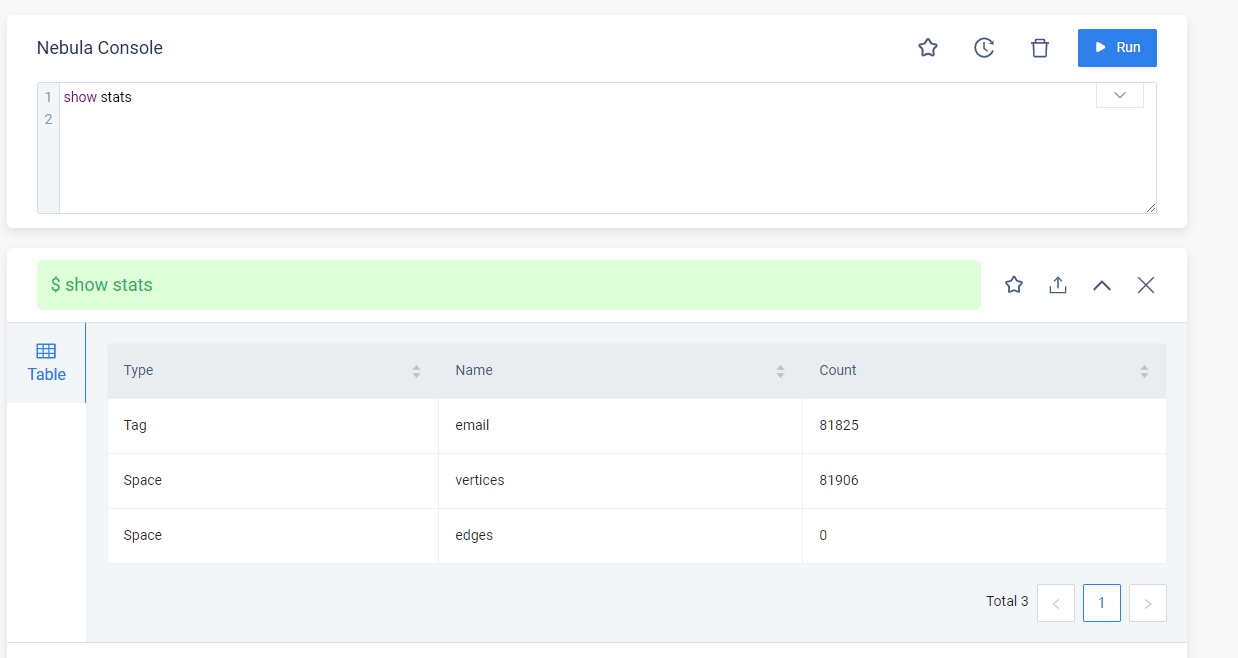
es 显示显示的数据量也有区别

查询
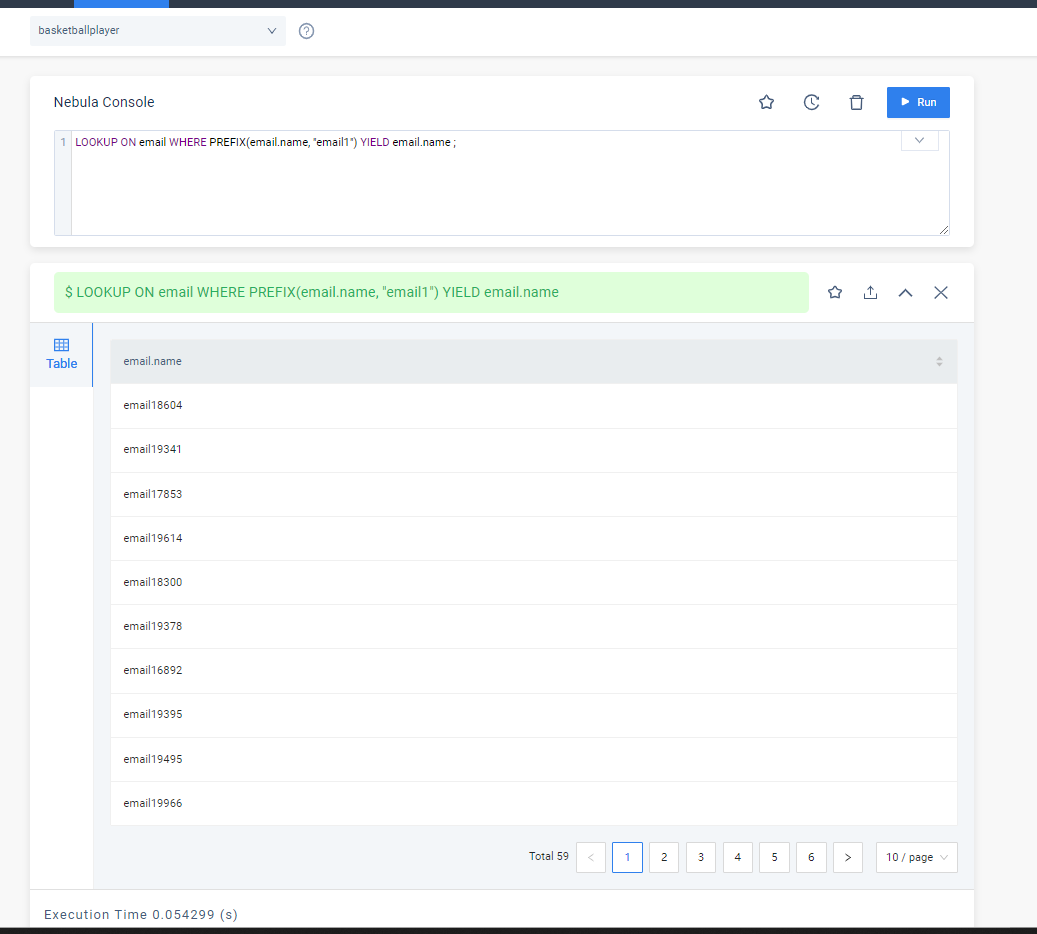
LOOKUP ON email WHERE PREFIX(email.name, "email1") YIELD email.name;

创建一个没有全文索引的图空间
CREATE SPACE `test1` (vid_type = FIXED_STRING(30)) ;
USE `test1`;
CREATE TAG cemail(word string, name string, num int64);
CREATE TAG INDEX IF NOT EXISTS cemail_index ON cemail(name(30));
REBUILD TAG INDEX;
导入数据
email.csv (4.4 MB)
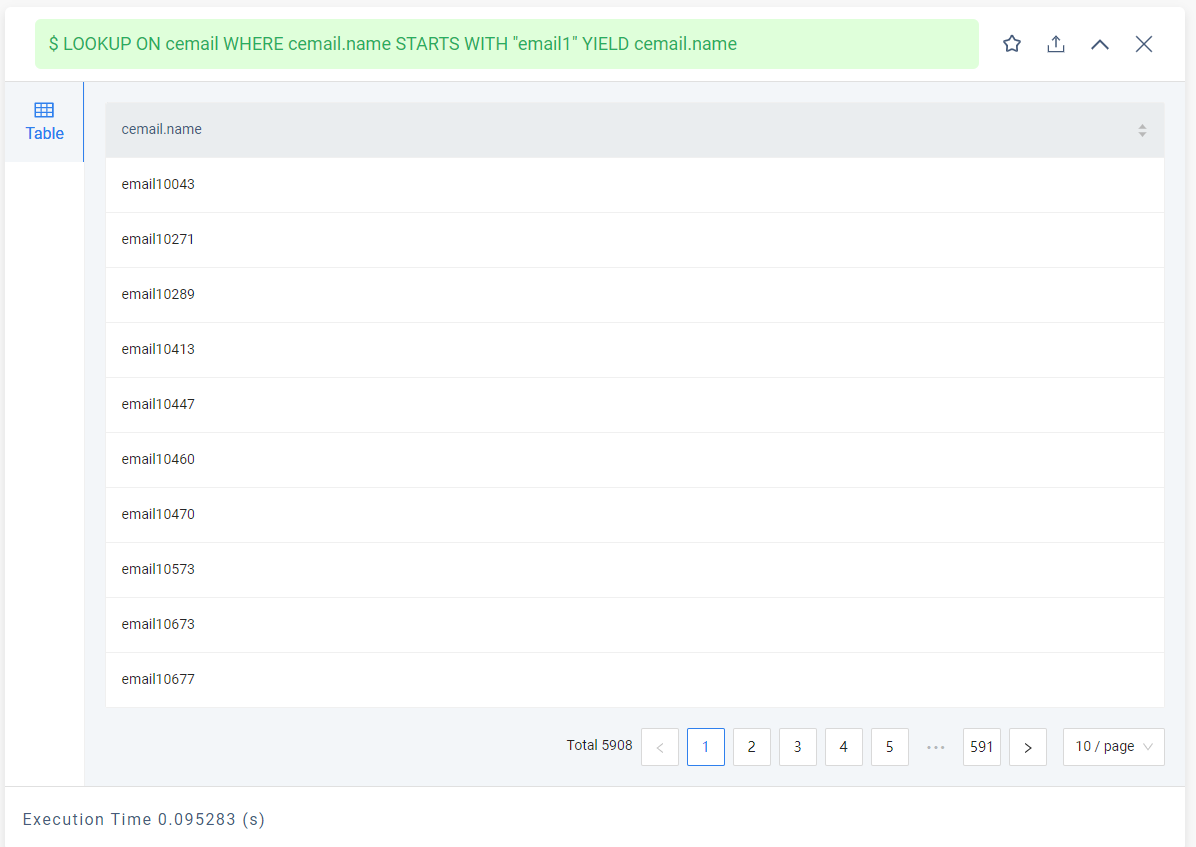
LOOKUP ON cemail WHERE cemail.name STARTS WITH "email1" YIELD cemail.name;