nebula 版本:3.1.0
部署方式:分布式
安装方式:deb
是否为线上版本:N
硬件信息
磁盘 机械
CPU、内存信息 Inter 12G
3台机器都分别都安装了graphd, storaged,metad
其中一台安装dashboard,studio
主要后期业务需要用到图关系的场景,这次只是看下在已有测试环境下的性能
7.25
3台机器从nebula3.0.2升到到3.1.0后,做数据导入操作,其中有四个任务插入数据相对多.
执行导入用的是spark connecter
其中数量大的导入有这几个
- 顶点2千万
- 顶点8千万
- 1.5亿 边
- 8.7亿 边
任务是都是串行的操作,只有最后插入边时有个任务失败后,发现后再次重启才有两个任务并行插入数据.任务再次失败之后再查原因,这其中伴随nebula storaged进程经常挂,
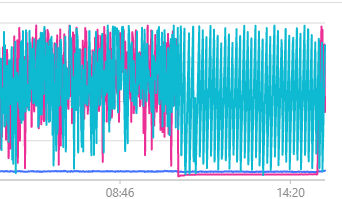
在dashboard监控也看到内存及CPU有些不太正常,其中下图
其中在16:06时已经停止对nebula任何操作了
7.26
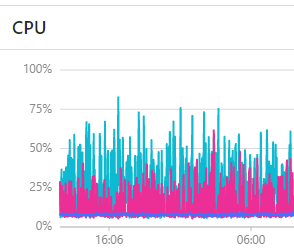
其中有storaged有启动后就挂了,过了几个小时后再资尝试变成正常启动
下图是红框正常启动后的监控图

想验证是不是无标签顶点没有被删除,
集群虽然每个进程都正常运行,但由于内存问题,导致不可用.
用查询语句会出现E_LEADER_LEASE_FAILED
网络IO图

通过查询后发现是都是storaged进程引起的.
7.27
其中一台部署bashboard studio也就是浅蓝色线条,不能ping通,但机器仍在运行,再
存放数据的目录其中有两个data点1.6G,另外一台现在都ping不通了
对nebula停止任何操作后,还是如下图(由于其中一台机为器bashboard在运行但不能ping通,也只能用同一张图了)
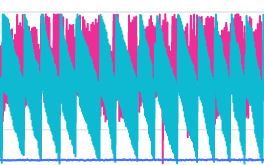
7.26(三台机器还能正常访问)
仍然对图没有任何额外操作,自以为是数据太多,nebula再加载到内存,还没加载完内存就占满,之后内存释放重新再次加载.
之后想删除图数据做验证
drop tag edge 操作
clear space 操作
结果这样操作完,
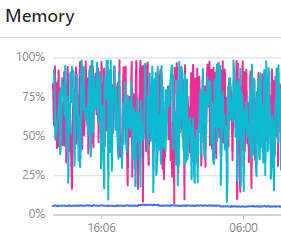
共三台机器,台内存都为12G. 由于其中两台storaged占用内存有些异常,如图.
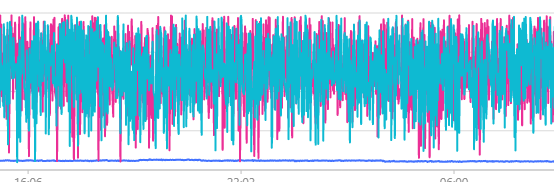
把所有数据都删除,之后发现两台机器仍有相同的问题
之后重启有问题那两个storaged进程,其中一个进程就不能启动成功,另外一台重启进程是正常启动,但占用内存问题仍存在.
内存:
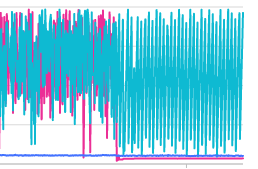
其中不能启动的storaged.error日志
Log file created at: 2022/07/25 10:52:57
Running on machine: node5
Running duration (h:mm:ss): 0:00:00
Log line format: [IWEF]yyyymmdd hh:mm:ss.uuuuuu threadid file:line] msg
F20220725 10:52:57.987545 20089 RaftPart.cpp:1782] Check failed: lastLogIdCanCommit == lastCommitId (88297 vs. -1)
隔两三个小时再次重启不能启动的storaged进程,成功启动,如图红框

(右侧memory图红框画错了,应该在其它紧挨着左旁都是浅蓝色,两条红和蓝都接近0)
7.27
今天上午过来发现其中有问题的那台(安装dashboard,studio)不能ping能通,但机器还在运行.
重新启动后,一切都监控突然变得非常正常,通过监控图可以发现昨天大约晚6点出现变化,这个时间回想下也没做其它什么,但应该是晚5点多,由于可能是无标签顶点问题,做过查询,之后又出来水位不足,之后做过改完做过restart all操作,依然有同样问题
重启那台机器现在监控图看起来就很正常,如图红框,XXXX
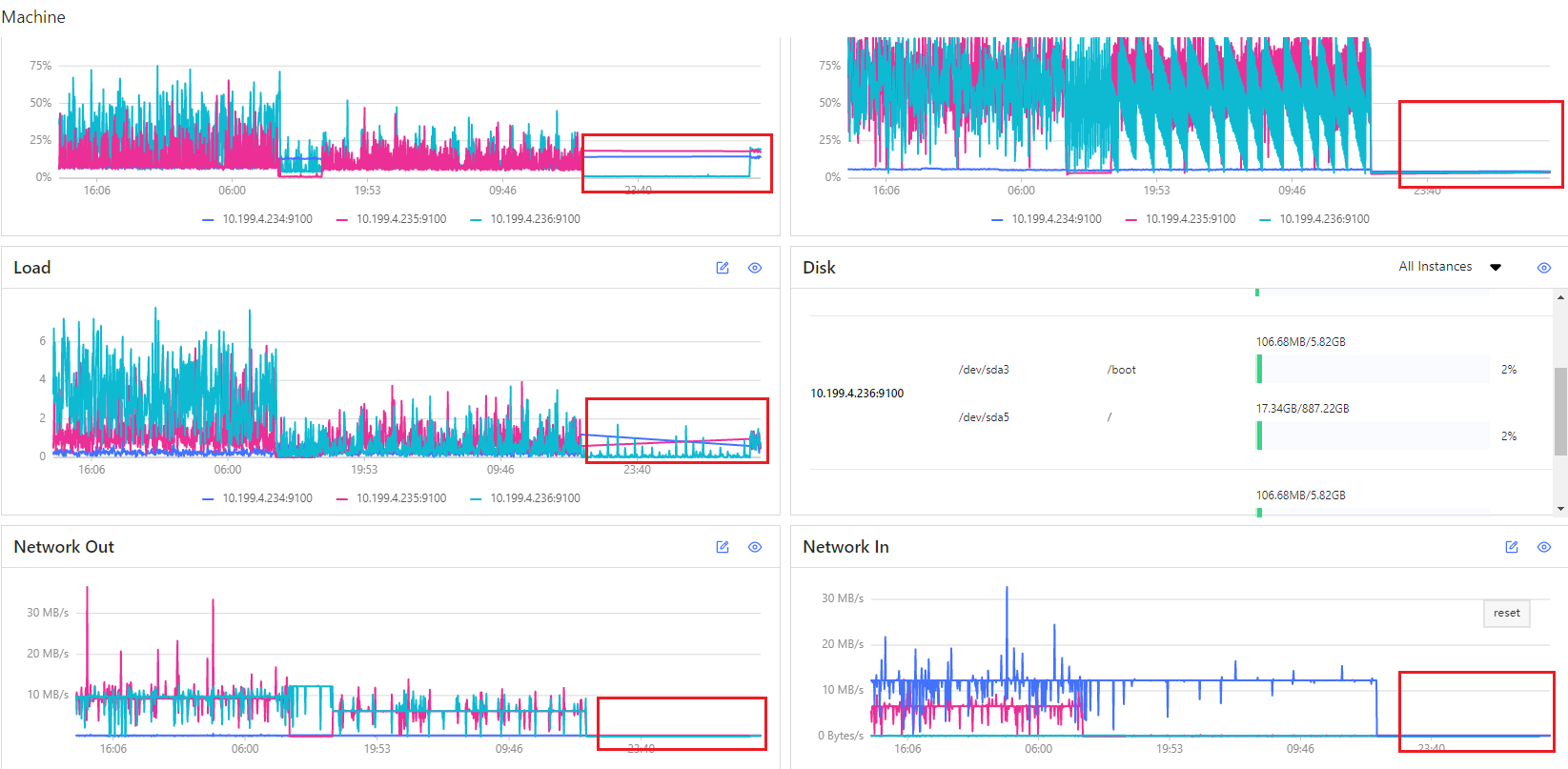
有以下几个问题
1 为什么其中两台服务器占用内存是折线方式,而有另外一台(蓝)则占用非常少.
2 数据已经清空,为什么那两台还是以这种方式继续占用内存
3 为什么其中一台关闭后就不能启动了,持续5分钟. 而过后两个小时又能启动了?
4 数据清空已经删除,这3台也没有其它程序或人在用,为什么网络会这么这么大的流量(流量都是两台服务器最终把数据指定到蓝色的nebula storage端口)