- nebula 版本:3.1.0
- 部署方式:腾讯云单机部署
- 安装方式: RPM
- 是否为线上版本: N
- 硬件信息
- 磁盘 100G
- CPU: 4核
- 内存信息 16G
- 问题的具体描述
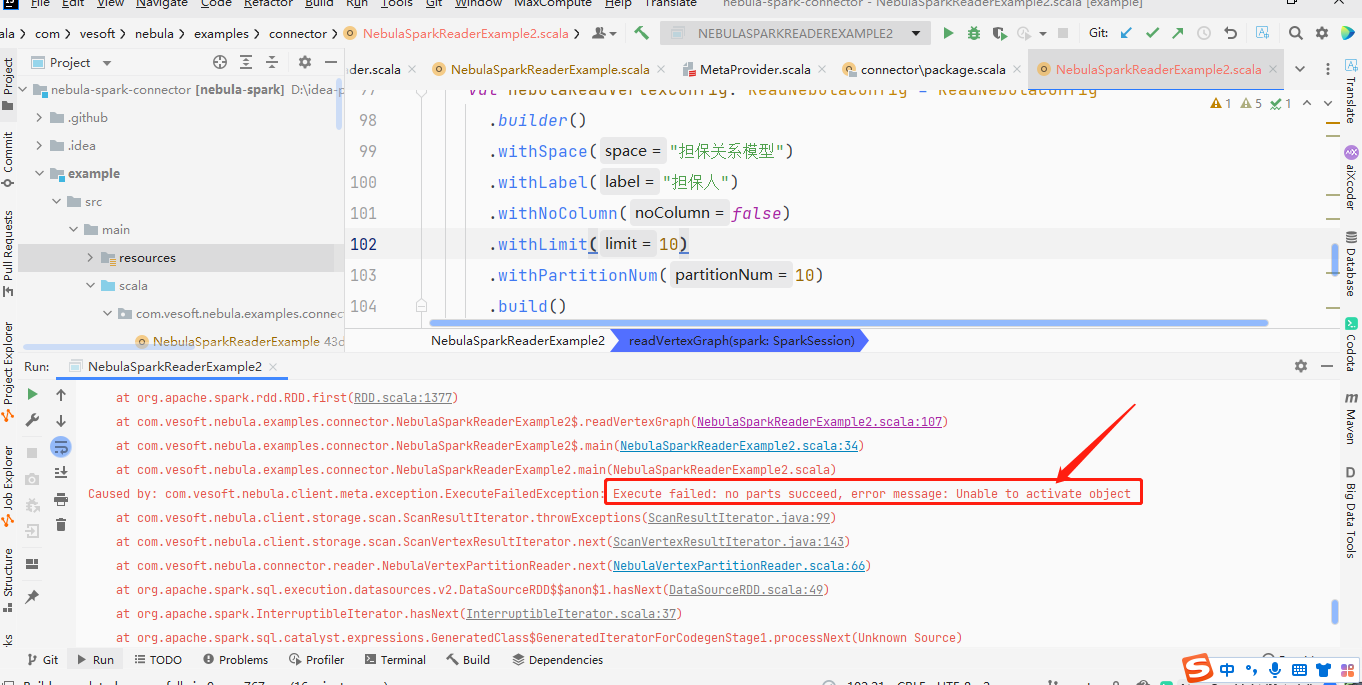
使用spark-connector 读取Nebula 中数据去构建graphx 图去做图计算,读取的时候报如下:
Caused by: com.vesoft.nebula.client.meta.exception.ExecuteFailedException: Execute failed: no parts succeed, error message: Unable to activate object
at com.vesoft.nebula.client.storage.scan.ScanResultIterator.throwExceptions(ScanResultIterator.java:99)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.next(ScanVertexResultIterator.java:143)
at com.vesoft.nebula.connector.reader.NebulaVertexPartitionReader.next(NebulaVertexPartitionReader.scala:66)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:49)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$13$$anon$1.hasNext(WholeStageCodegenExec.scala:636)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.generic.Growable$class.$plus$plus$eq(Growable.scala:59)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:104)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:48)
at scala.collection.TraversableOnce$class.to(TraversableOnce.scala:310)
at scala.collection.AbstractIterator.to(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.toBuffer(TraversableOnce.scala:302)
at scala.collection.AbstractIterator.toBuffer(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.toArray(TraversableOnce.scala:289)
at scala.collection.AbstractIterator.toArray(Iterator.scala:1334)
at org.apache.spark.rdd.RDD$$anonfun$collect$1$$anonfun$13.apply(RDD.scala:945)
at org.apache.spark.rdd.RDD$$anonfun$collect$1$$anonfun$13.apply(RDD.scala:945)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
22/08/10 16:01:38 ERROR ScanVertexResultIterator: get storage client error,
java.util.NoSuchElementException: Unable to activate object
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:400)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:277)
at com.vesoft.nebula.client.storage.StorageConnPool.getStorageConnection(StorageConnPool.java:41)
at com.vesoft.nebula.client.storage.scan.ScanVertexResultIterator.lambda$next$0(ScanVertexResultIterator.java:88)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.facebook.thrift.transport.TTransportException: java.net.ConnectException: Connection timed out: connect
at com.facebook.thrift.transport.TSocket.open(TSocket.java:206)
at com.vesoft.nebula.client.storage.GraphStorageConnection.open(GraphStorageConnection.java:66)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:58)
at com.vesoft.nebula.client.storage.StorageConnPoolFactory.activateObject(StorageConnPoolFactory.java:15)
at org.apache.commons.pool2.impl.GenericKeyedObjectPool.borrowObject(GenericKeyedObjectPool.java:391)
... 8 more
Caused by: java.net.ConnectException: Connection timed out: connect
at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method)
at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:81)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:476)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:218)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:200)
at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:162)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:394)
at java.net.Socket.connect(Socket.java:606)
at com.facebook.thrift.transport.TSocket.open(TSocket.java:201)
... 12 more
22/08/10 16:01:38 ERROR ScanVertexResultIterator: get storage client error,
相关读取的代码如下:
private[this] def readVertexGraph() = {
println("start to read graphx vertex")
val space = configs.nebulaConfig.readConfigEntry.space
println("space:" + space)
val vertexLabels = configs.nebulaConfig.readConfigEntry.vertexLabels
var vertexRDD: RDD[(VertexID, PropertyValues)] = null
if(vertexLabels.nonEmpty) {
for(i <- vertexLabels.indices) {
val nebulaReadVertexConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace(space)
.withLabel(vertexLabels(i))
.withNoColumn(false)
.withLimit(10)
.withPartitionNum(10)
.build()
if (vertexRDD == null) {
vertexRDD = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToGraphx()
} else {
val df = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToGraphx()
vertexRDD = vertexRDD.union(df)
}
}
}
vertexRDD.collect().foreach(println(_))
vertexRDD
}
程序的配置地址如下:

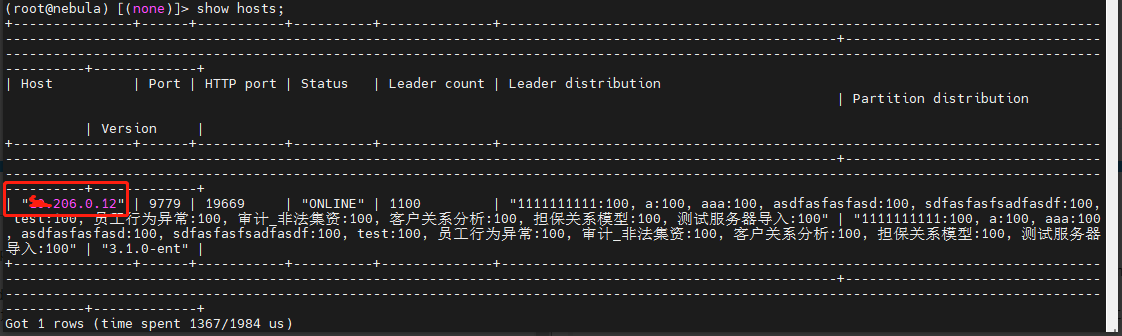
show hosts 显示出来的地址如下
从日志内容上看,是没有获取到storage 客户端,也参考了论坛其他小伙伴遇到类似的问题进行排查,保证spark 可以访问到show hosts 的主机地址,目前看下来是可以正常访问的,我们部署方式是腾讯云部署的,相关的9559 9669 9779 端口已开