Abel
1
- nebula 版本:3.0.0
- 部署方式:Spark伪分布式 / Nebula单机(按照手册的示例进行)
- 安装方式:RPM
- 是否为线上版本:N
- 硬件信息
- 磁盘SSD
- 4CPU 20core
- RAM 256G
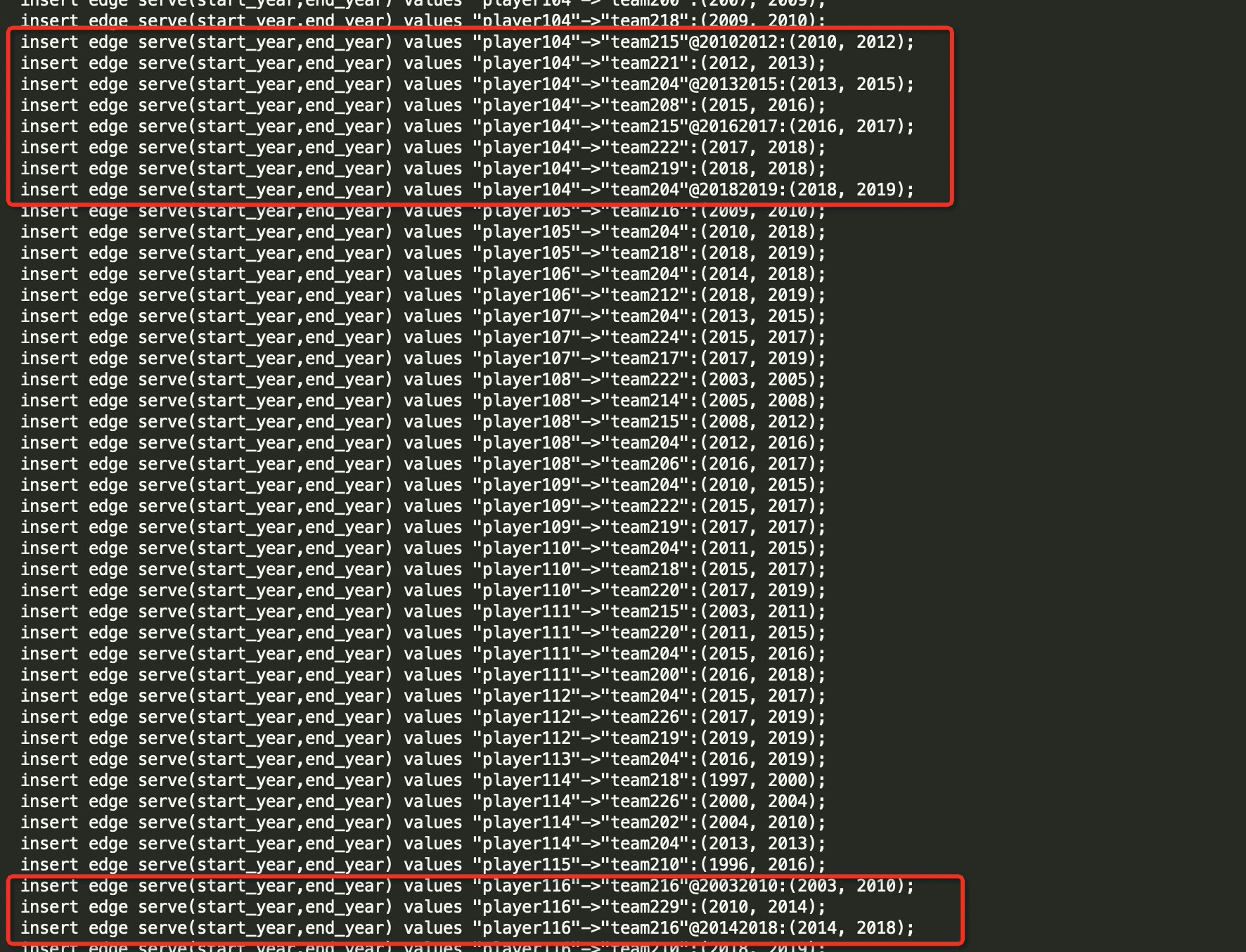
- 问题的具体描述:按照手册的要求部署了Spark+Hadoop,然后将basketballplayer导入到我的Nebula中,结果其中的"serve"边共152个在Exchange导入之后只有146个,图一为nSQL语句文件在客户端的直接导入"serve"边共有152个,图二为CSV文件的Exchange导入"serve"边仅有146个(值得一提的是使用Hadoop和MySQL的导入结果也是如此)
(root@nebula) [basketballplayer]> show stats
+---------+------------+-------+
| Type | Name | Count |
+---------+------------+-------+
| "Tag" | "player" | 51 |
| "Tag" | "team" | 30 |
| "Edge" | "follow" | 81 |
| "Edge" | "serve" | 152 |
| "Space" | "vertices" | 81 |
| "Space" | "edges" | 233 |
+---------+------------+-------+
(root@nebula) [basketball]> show stats
+---------+------------+-------+
| Type | Name | Count |
+---------+------------+-------+
| "Tag" | "player" | 51 |
| "Tag" | "team" | 30 |
| "Edge" | "follow" | 81 |
| "Edge" | "serve" | 146 |
| "Space" | "vertices" | 81 |
| "Space" | "edges" | 227 |
+---------+------------+-------+
1 个赞
看日志导入是成功的,你的serve 这个edge的配置是什么样的,如果没有配置rank的话,数据中是否存在源点和目标点相同的边数据。
Abel
3
没有配置rank,数据是Nebula手册示例的数据,应该不会有问题吧
如下是你自己通过console导入的ngql语句,有6条数据是有rank的,且这6条数据 存在和其相同的src dst id数据的。 当你用同样的数据集 使用exchange导入时,在没有配置rank的情况下这6条数据会覆盖掉具有相同 src dst的数据。 所以你的数据会少6条。
2 个赞
system
关闭
6
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。