lookup go minus.csv (31.2 KB)
复合match.csv (26.7 KB)
这个能给分析下原因吗?或者哪里有资料我学下怎么看这种文件
profiling data 那一列会显示算子执行时间。有两个比较重的算子,RollUpApply(147930x388rows) 算子花了4s,Filter(147930->) 花了 2s,看上去是 pattern expression 的计算开销有点大
有这方面的文档吗?官方文档里没有这方面的介绍
pattern expression 查询优化器执行的慢吗
帅气~
是的。我们发现 pattern expression 的实现导致一些 filter 无法下推,这个我已经提了 feature(https://github.com/vesoft-inc/nebula/issues/4575)
当然不排除这条语句大量过滤是 pattern expression 本身导致的。需要你把 datetime 相关的 filter 去掉重新 profile 一下
MATCH (v:intopiece)
WHERE intopiece.loan_business_id == $bid
MATCH (v)-[*2]-(n:intopiece)
WHERE not (v)-->(n)
RETURN distinct n
1 个赞
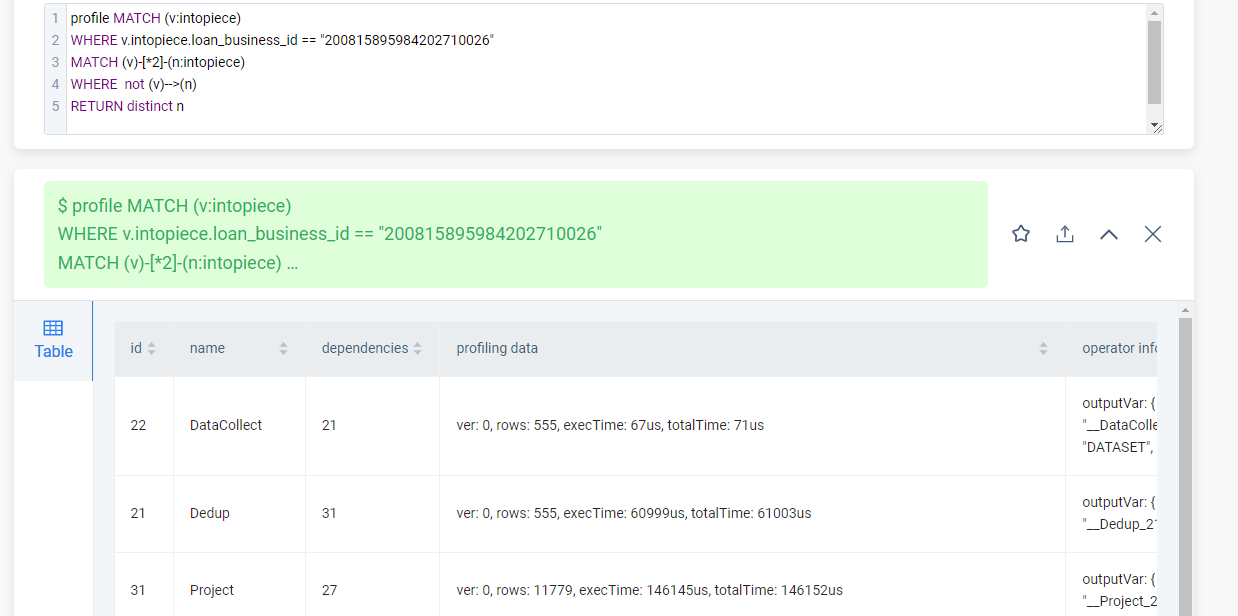
新的profile帮忙看下原因哈
pattern expression 的开销也很大,可以先等上面哪个 feature 做完之后再测下,如果 datetime 的 filter 选择度高的话,应该优化效果也很明显的。
1 个赞
请问这个feature什么时间可以使用呢?我这边下个月就要接新业务上线了,有点着急。。。 0.0
请问目前 go 语句 和 mathc语句效果都不太理想,其实我这边的需求也就是 根据一个节点的属性进行条件查询,得到这个节点二跳的数据 (剥离一跳的数据,因为我这边业务是又分组统计的,一跳的数据已经统计过了),请问在当前官方的正式版本中,可以找到最优解吗?还是说必须得等下个版本了 0.0 …我好评估下工作安排,因为这个是线上得迭代需求,确实卡这了,而且对整个项目进度有很大影响。
可以帮忙 解释下 那个执行计划的 痛点在哪里吗?