如图
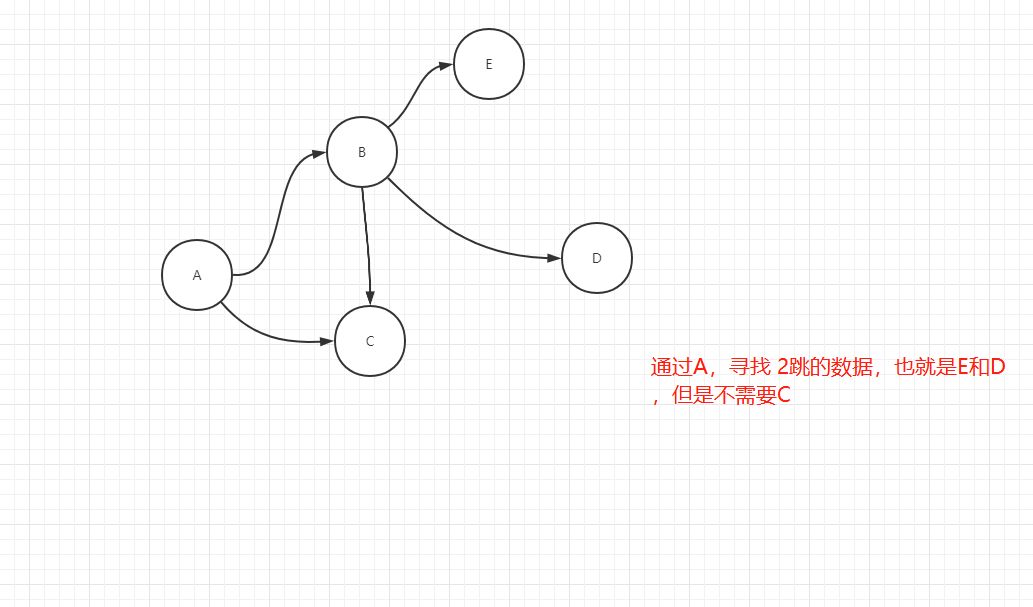
不要C的原因 是因为在查一跳的时候已经统计过了,如何实现这个查询呢,求大神支招
因为这是个下游数据处理的业务,所以还需要高性能
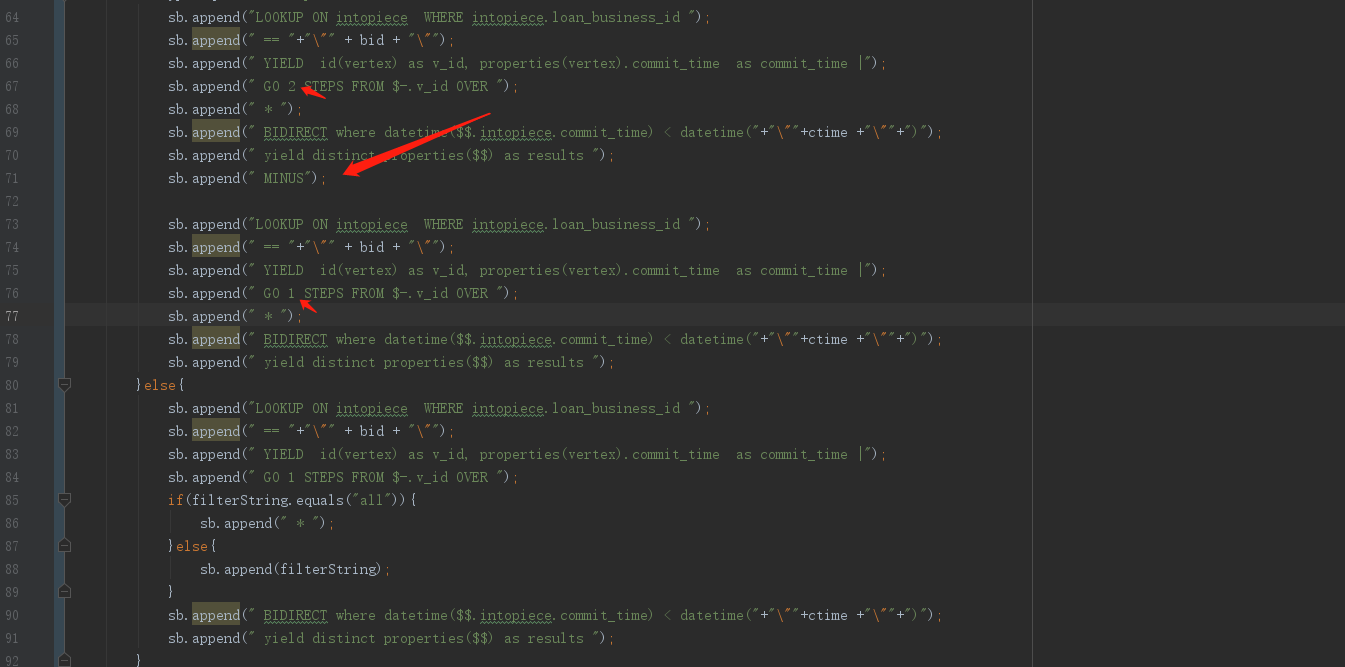
go 2 steps from "A" over E yield id($$) AS dst MINUS go from "A" over E yield id($$) AS dst
MINUS 是比较慢…你测过 MATCH 语句吗?
match (v)-[:E*2]->(n) where id(v)=="A" and not (v)-->(n) return n
没试过这种的,我改下试试,非常感谢
请问 mathch 会使用到索引吗?
指定 id 就不会
可以详细说下吗?或者我说下我这边的情况的 目前数据中对节点的 loan_business_id 做了索引,我查询的时候也是会对这个条件进行查询的。
完整描述下你的需求
我的基础数据 一个节点类型(into,数据量较大) 40种边关系类型,而我要实现的是根据某一个节点,需要查询出来上面40种边关系的其中一种以及全部边关系的一跳和二跳,三跳的数据(注:二跳不需要统计一跳中出现过的数据,同理三跳也一样),并取出属性值来进行业务计算(这些计算原本想在查询语句中实现的,几经尝试后发现不行,可能是我没找对方法吧,所以现在改为查询回数据,在后台执行计算)
大部分数学计算或聚合都可以在查询语句中完成,而且 match 语句提供了 cypher 语法的支持,你上面提到的这些需求应该是可以描述的。
目前是怎么查出这个数据,所以才会出现我上面截图的 MINUS 的拼接语句,请问有没有例子呢?还有刚才的match (v)-[:E*2]->(n) where id(v)==“A” and not (v)–>(n) return n这个 说指定id就不会用索引,我这边就是根据某一个属性先查到这个点,然后在从这个点开始执行上面的查找的,所以也不行吗?求解
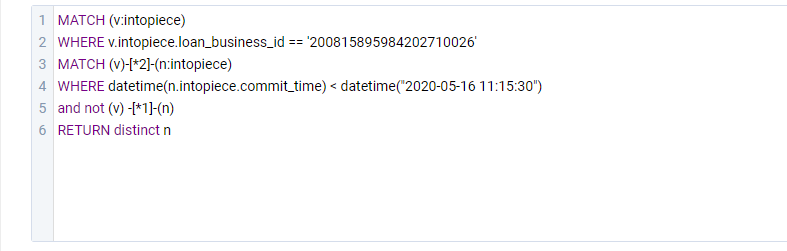
我按照你 if 块的语句简单写了下等价的 match 语句($-.commit_time 发现你并没有用到),你可以看下。
cypher 语法描述图查询更简单自然,但是性能需要进行实际测试
MATCH (v:intopiece)
WHERE intopiece.loan_business_id == $bid
MATCH (v)-[*2]-(n:intopiece)
WHERE datetime(n.intopiece.commit_time)<datetime($ctime) and not (v)-->(n)
RETURN distinct n
测一下整体语句性能吧。
确实有一些属性裁剪的优化规则没有应用上,导致捞取了所有的属性。
等价的 lookup+go+minus 的时间是多少了?
profile 跑一下看看,match 应该还会有不少优化的空间
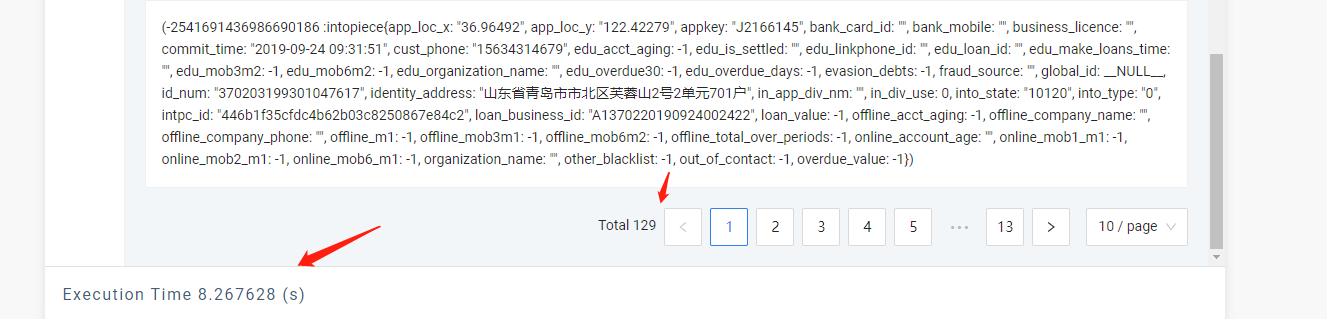
根据昨天最后一次测试结果,同一个数据量(二跳节点数量,样本129),lookup+go+minus的时间在2-4秒,而使用复合mathch方式一次执行时间在9秒左右。
profile 看下