-
nebula 版本:v3.1.0
-
部署方式:分布式
-
安装方式:Docker
-
是否为线上版本:Y
-
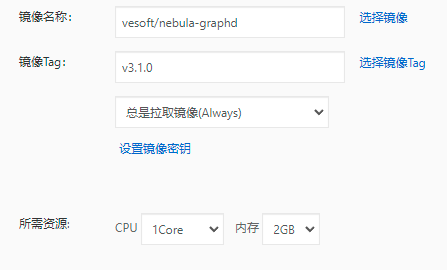
硬件信息
- 磁盘 阿里云oss
- CPU 1、内存2G(每个容器)
-
问题的具体描述:
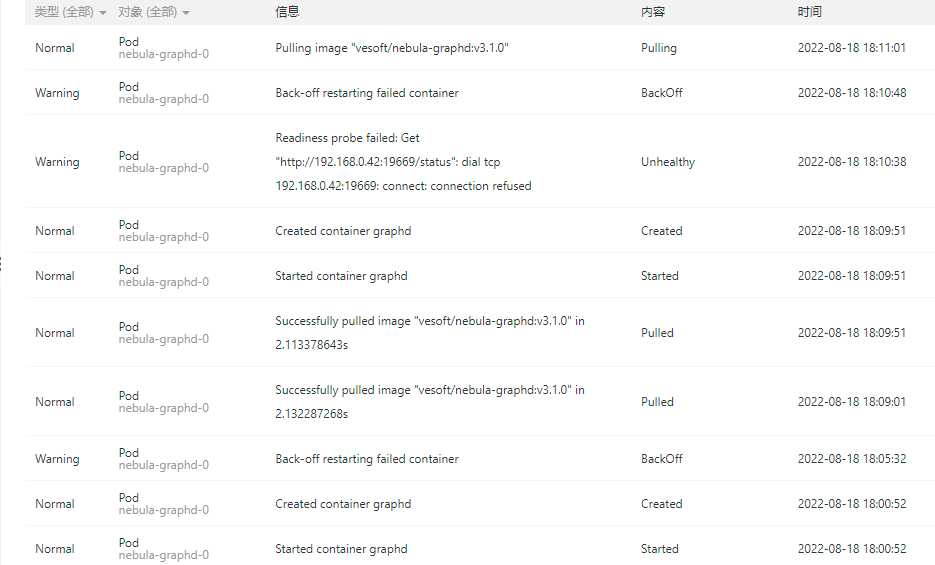
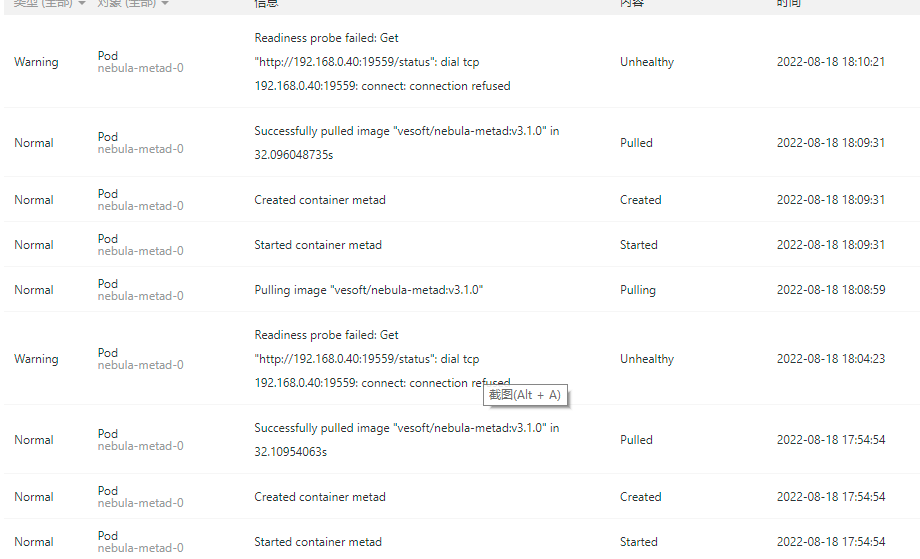
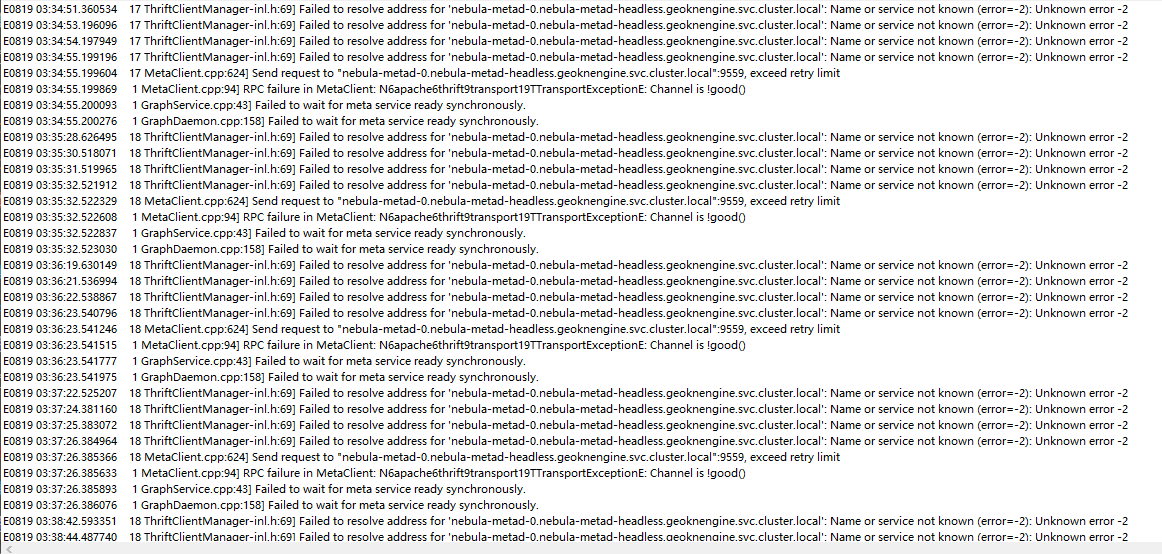
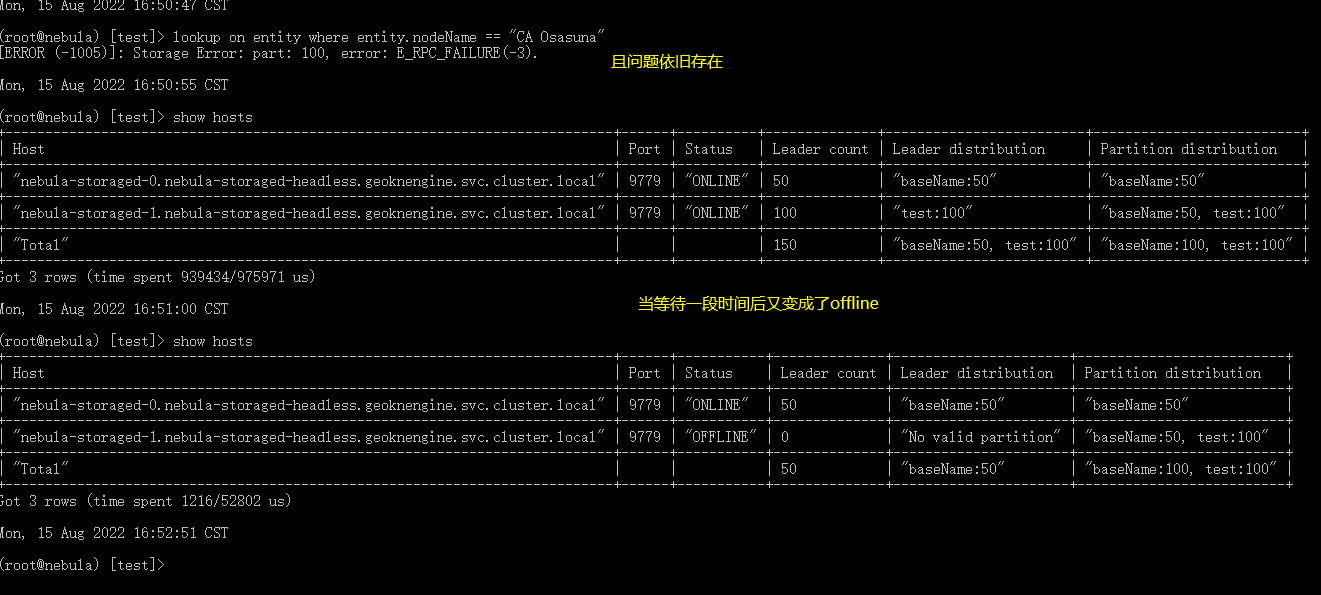
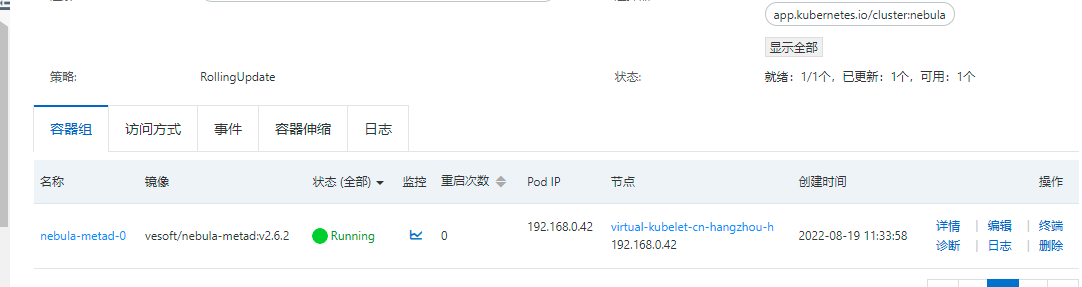
使用helm和kubectl采用对应版本的nebula operator分别在阿里云gask平台上尝试部署了nebula graph2.6.2和3.1.0,graphd和metad出现crashloop,graphd事件及日志没有发现问题,metad事件显示readness probe访问失败,storaged一直是黄色的running状态没有重启。
(此外kruise没有运行kruise-daemon容器,helm安的话会pending,通过gui里的组件管理安则直接没有这个容器) -
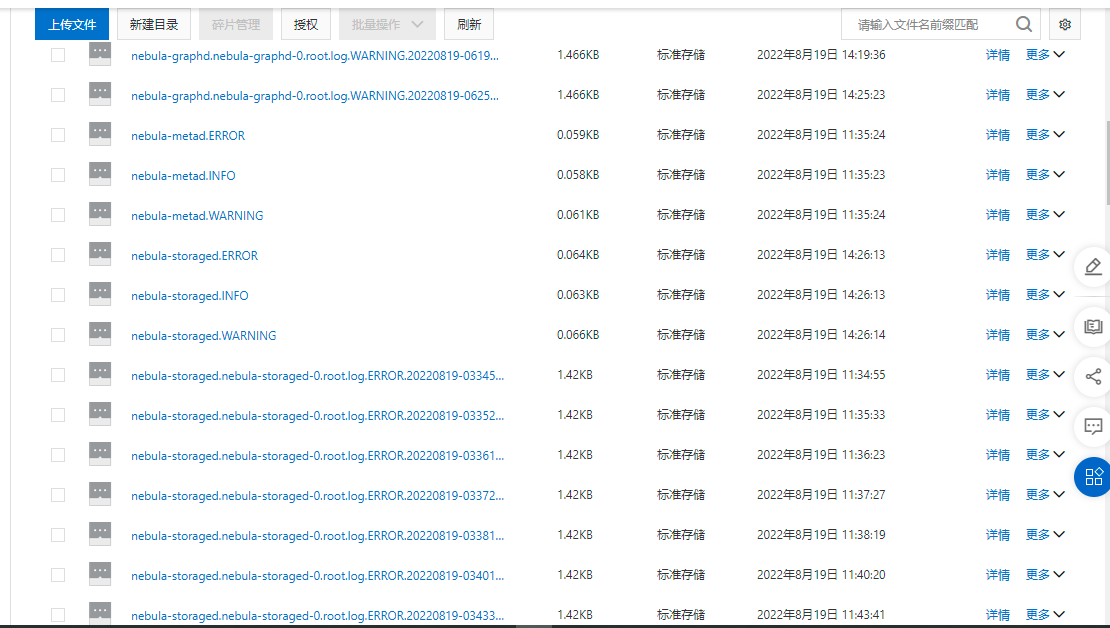
相关的 meta / storage / graph info 日志信息:
apiVersion: apps.nebula-graph.io/v1alpha1
kind: NebulaCluster
metadata:
name: nebula
spec:
graphd:
resources:
requests:
cpu: “1”
memory: “2Gi”
limits:
cpu: “1”
memory: “2Gi”
replicas: 1
image: vesoft/nebula-graphd
version: v3.1.0
service:
type: NodePort
externalTrafficPolicy: Local
logVolumeClaim:
resources:
requests:
storage: 2Gi
storageClassName: sc-geoknengine-nebula
config:
“client_idle_timeout_secs”: “1”
metad:
resources:
requests:
cpu: “1”
memory: “2Gi”
limits:
cpu: “1”
memory: “2Gi”
replicas: 1
image: vesoft/nebula-metad
version: v3.1.0
dataVolumeClaim:
resources:
requests:
storage: 2Gi
storageClassName: sc-geoknengine-nebula
logVolumeClaim:
resources:
requests:
storage: 2Gi
storageClassName: sc-geoknengine-nebula
config:
“client_idle_timeout_secs”: “1”
storaged:
resources:
requests:
cpu: “1”
memory: “2Gi”
limits:
cpu: “1”
memory: “2Gi”
replicas: 1
image: vesoft/nebula-storaged
version: v3.1.0
dataVolumeClaim:
resources:
requests:
storage: 2Gi
storageClassName: sc-geoknengine-nebula
logVolumeClaim:
resources:
requests:
storage: 2Gi
storageClassName: sc-geoknengine-nebula
config:
“client_idle_timeout_secs”: “1”
reference:
name: statefulsets.apps
version: v1
schedulerName: default-scheduler
imagePullPolicy: Always
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-oss-geoknengine-nebula22
namespace: geoknengine
labels:
alicloud-pvname: pv-oss-geoknengine-nebula
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: sc-geoknengine-nebula
flexVolume:
driver: “alicloud/oss”
options:
bucket: “deepengine”
url: “oss-cn-hangzhou.aliyuncs.com”
otherOpts: “-o max_stat_cache_size=0 -o allow_other”
path: “/data/onesis/kt3/nebula”
akId: “L=-------------------YrQ6”
akSecret: “m==1------------------x==Ml”
相关截图: