图数据库在挖掘黑灰团伙以及建立安全知识图谱等安全领域有着天然的优势。为了能更好的服务业务,选择一款高效并且贴合业务发展的图数据库就变得尤为关键。本文挑选了几款业界较为流行的开源图数据库与Nebula进行了多角度的对比。
比较对象:
Neo4j: Neo4j是目前业界广泛使用的图数据库,包含社区版本和商用版本,本文中使用社区版本。
HugeGraph:HugeGraph是百度基于JanusGraph改进而来的分布式图数据库,主要应用场景是解决百度安全事业部所面对的反欺诈、威胁情报、黑产打击等业务的图数据存储和图建模分析需求。具有良好的读写性能。
测试硬件环境:
性能对比:
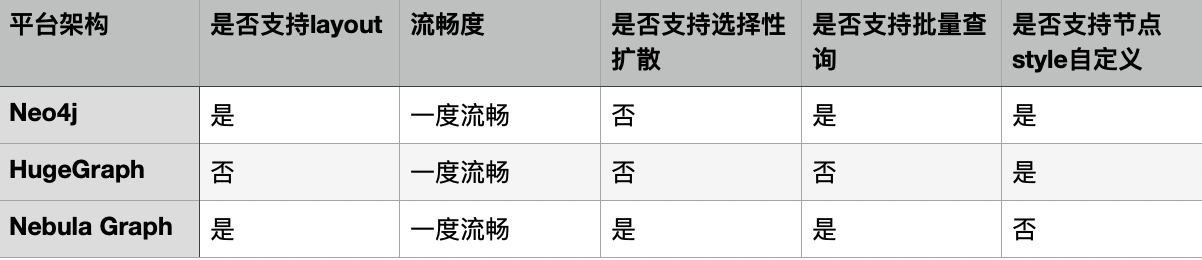
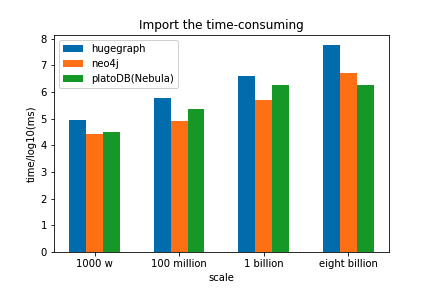
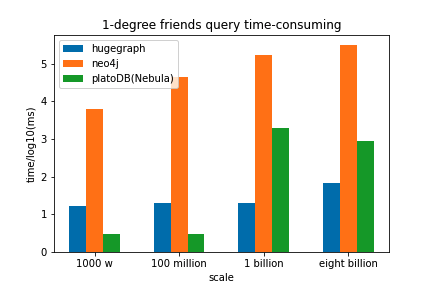
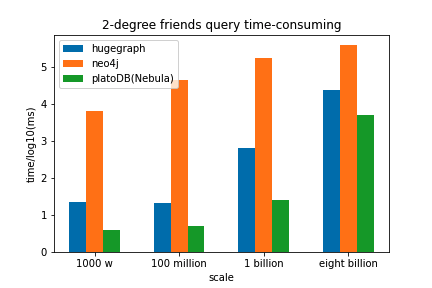
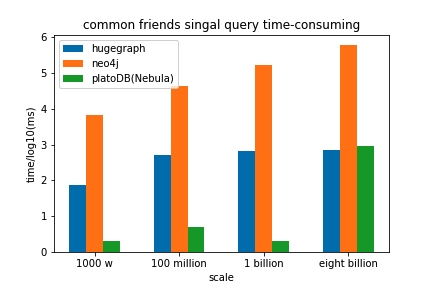
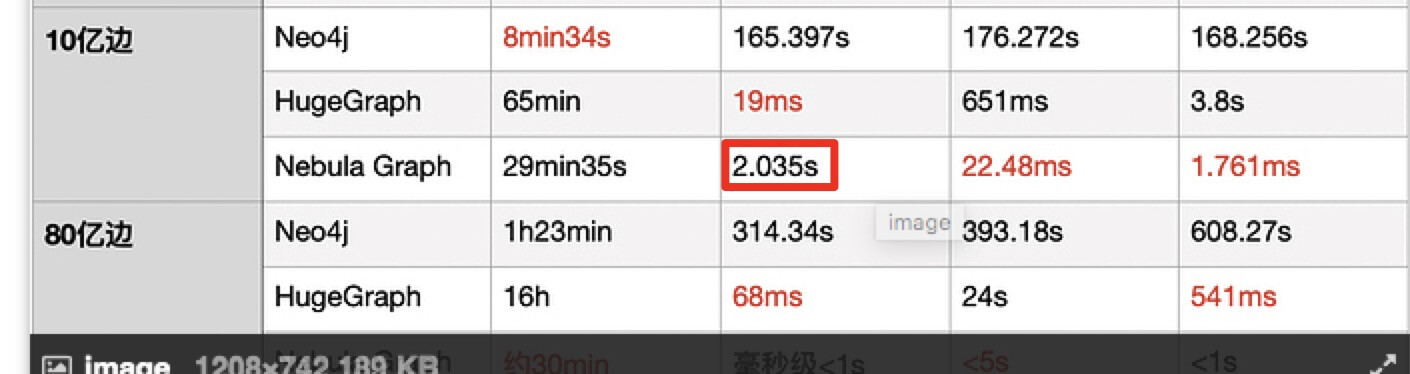
我们使用不同量级的图从入库时间,一度好友查询,二度好友查询,共同好友查询几个方面进行了对比,结果如下:
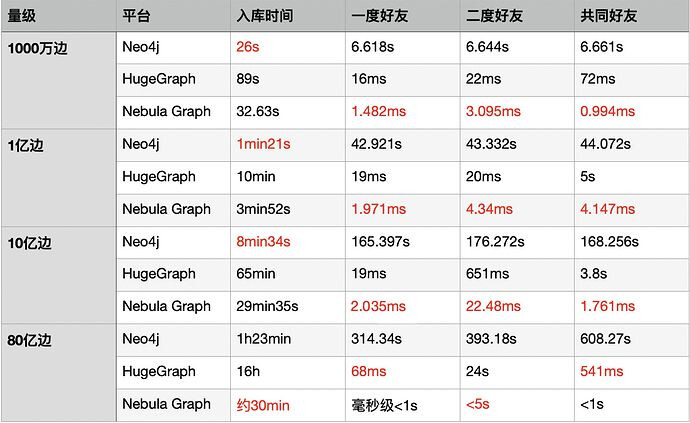
可以看到在导入性能上,数据量小的时候nebula的导入效率稍慢于neo4j,但在大数据量的时候Nebula Graph的导入明显优于其他两款图数据库;在3种查询场景下,nebula的效率都明显高于neo4j,与HugeGraph相比也有一定的优势。
查询语言对比:
从查询语句的角度出发,gremlin比较复杂,ngql和cypher比较简练,从可读性角度出发,ngql比较类sql化,比较符合大家的使用习惯。
可视化对比:
在可视化方面,所有的平台都还只处于可用状态,Nebula Graph的选择性扩展在团伙挖掘中是一个加分项,但是在二度结果展示流畅度,展示结果自定义展示方面还有优化空间。
在比较了多款业内主要使用的开源数据库后,我们从性能,学习成本和与业务的贴合程度多个角度考虑,最终选择了性能出众,上手简单,能大幅提高业务效率的Nebula Graph图数据库。
本次测试结果系腾讯云安全团队李航宇、邓昶博撰写
9 个赞
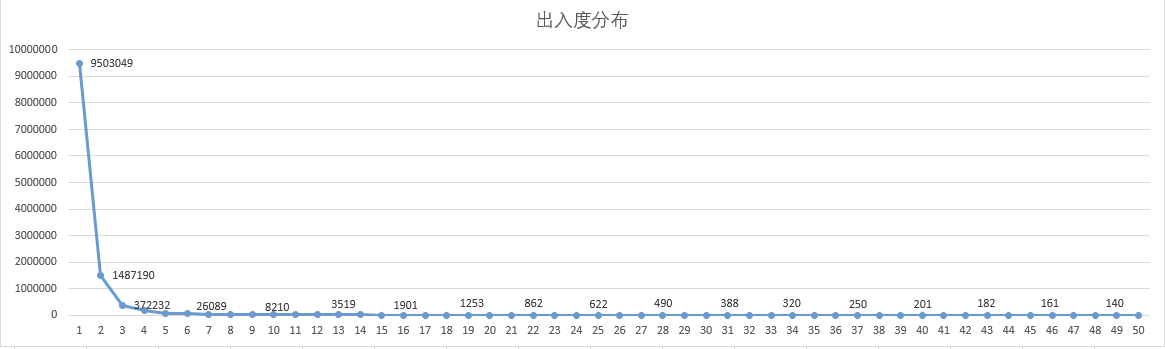
1.数据集用的是我们内部脱敏的关系数据,大概分布如下图(高于50度的点分布也很少,为了方便看我们把50度以上的结果截断了):
2.延迟我们用的是平均延迟。
3.这块我们在测试neo4j的时候使用的是其推荐的内存大小,具体如下:

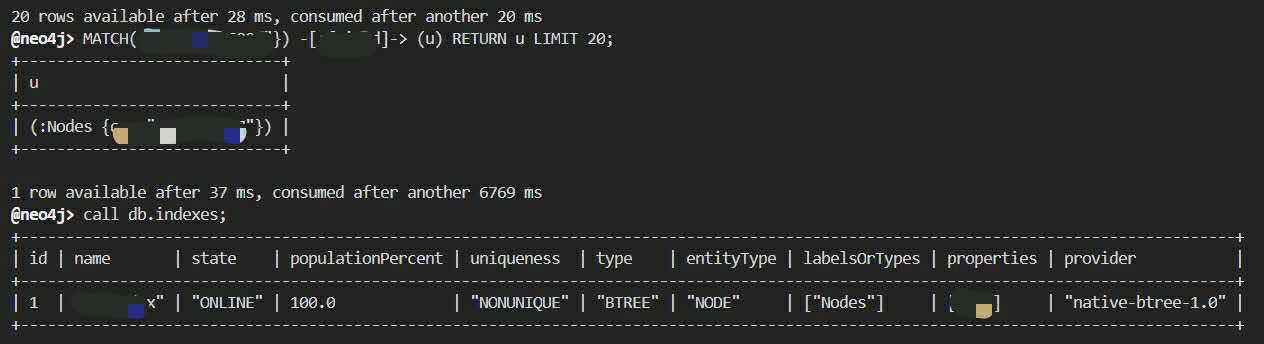
效果在我们经过几次测试之后,仍然稳定在6s左右:
index也是正常运作的,可能的解释是说到查询时间是指图中的37ms,我们在实验中记录的都是控制台显示结果的时间,所以记录的是6s。
如果这块测试还有什么问题的话欢迎指出哈~
1 个赞
感谢你的问题和建议,我们在根据建议逐个排查测试,有结果会及时反馈上来 
少了Dgraph,很喜欢nebula,但没有Dgraph与nebula的对比,请增加这两个的对比
图的CRUD很丰富,各个产品侧重点也完全不同。
欢迎你在自己的业务场景下评测对比。
LiFool
10
想问下hugegraph这边用的是哪个后端? 二度三度关系查询到的数据量级大概是多少?
1 个赞
3种图耗时对比有问题吧,还是语句没有写全。One-Hop Friends Query 和 Two-Hop Friends Query ,HugeGraph 直接用both() 就可以吧,而且返回的是去重后的总数,而其他2种图是返回的顶点吧,而且 Nebula over relation 是确定的边,还是 * ,而且这里不是双向跳跃吧,希望能更加完善一些吧。 现在nebula的文档是真的少,但国内好多大厂推荐,一时不知道改不改,现在用的是janusgraph
1 个赞
您可以移步美团技术团队发的这篇帖子看看 Dgraph,Nebula Graph, HugeGraph 的性能测试: 主流开源分布式图数据库Benchmark
这篇帖子有关于数据批量导入、实时写入、多跳查询这几个维度的对比,希望能帮到您!
2 个赞
测试数据集及测试样本可否提供一下?谢谢 
数据库版本,测试语言(java?),nosql,导入方式,样本选取依据,某方法测试结果的评测依据是什么:样本测试次数,最终结果如何选取:avg, p99?
可以把项目分享一下吗?谢谢 谢谢 谢谢 
BOSS 直聘最近也发了一篇对比文章,Dgraph VS Nebula Graph,很详细,可以参考一下:图数据库 Nebula Graph 在 Boss 直聘的应用 
我也是hugegraph的使用者。在你们测试查询共同好友的gremlin语法中,存在了错误,这个命令是无法查询到共同好友的。经过实际测试证实了这一点。