单独执行这个 没有问题
match (m:USER) where id(m) in [“1510615318”]
optional match (m)-[r1:CALL_TO]-(x:MOBILE)-[:APPLY_FOR]->(a1:APPL)-[:APPLY_ON]-(t1:TIME)
where r1.first_callmark_on<=20220102 and t1.TIME.date < ‘2022-01-02’
with m, collect(distinct x) as col_appl_1st_v4
unwind col_appl_1st_v4 as x
return x
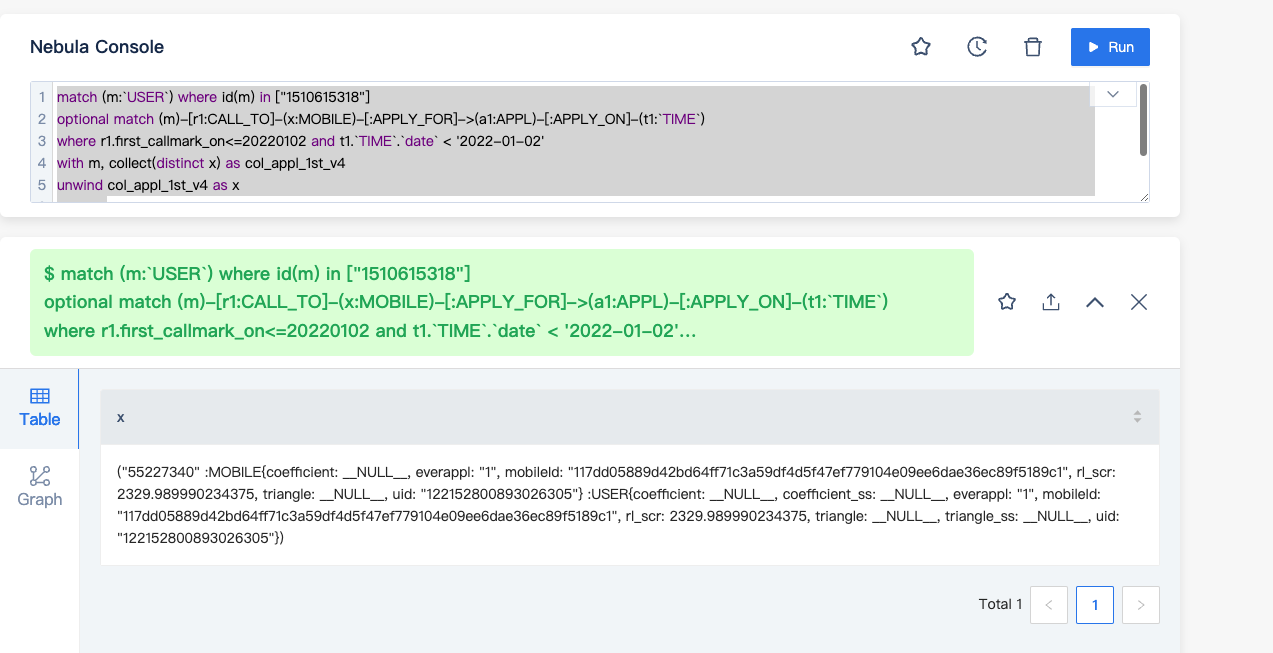
应该是后面语句有问题

这里没有复制错,因为 uu 是内部变量,最好跟外部定义的 n 有区分,这里有个错误是 labels 的参数应该是 uu
看了计划,最后的 match 还是通过 indexscan 的方式查询的,想问一下你们现在是打算上生产还是做 poc 使用?如果测试的话建议直接从 3.3 版本先升级成最新的 nightly 版本测试,这个问题已经在最新的分支解决了。
再试试下面的语句吧,如果不行,就建议升级了:
match (m:`USER`) where id(m) in ["1510615318"]
optional match (m)-[r1:CALL_TO]-(x:MOBILE)-[:APPLY_FOR]->(a1:APPL)-[:APPLY_ON]-(t1:`TIME`)
where r1.first_callmark_on<=20220102 and t1.`TIME`.`date` < '2022-01-02'
optional match (x)-[r2:CALL_TO]-(n:`USER`)
where r2.first_callmark_on<=20220102 and id(n)<>'1510615318'
with m, collect(distinct x) as col_appl_1st_v4, collect(distinct n) as col_user_2nd_v4
with m, col_appl_1st_v4, col_user_2nd_v4, [uu in col_user_2nd_v4 WHERE "MOBILE" in labels(uu)] as col_mobile_2nd_v4
return size(col_appl_1st_v4) as n_appl_1st_v4, size(col_user_2nd_v4) as n_user_2nd_v4

这个执行计划哪一块看出是走的index scan呢 我没有看太明白 这个执行计划
你可以在 explain 的后面加个输出的格式为 graphviz 就能看到计划的拓扑结构:
explain format="dot" YOUR-MATCH-QUERY
如果是上面的 table 形式,可以看到有个 IndexScan 算子,这个是用来产生你要的对应列 [x, r2] 的,要顺着 dependencies 找整个算子的流程
如果是对于这个cypher 我想对于下面在加一层optional match,我这个with应该如何放呢,都放在最后还是分层,我这个写的 是基于刚才你改的这个,如果要往下面加,该如何改呢
match (m:USER) where id(m) in [“1510615318”]
optional match (m)-[r1:CALL_TO]-(x:MOBILE)-[:APPLY_FOR]->(a1:APPL)-[:APPLY_ON]-(t1:TIME)
where r1.first_callmark_on<=20220102 and t1.TIME.date < ‘2022-01-02’
optional match (x)-[r2:CALL_TO]-(n:USER)
where r2.first_callmark_on<=20220102 and id(n)<>‘1510615318’
with m, collect(distinct x) as col_appl_1st_v4, collect(distinct n) as col_user_2nd_v4
with m, col_appl_1st_v4, col_user_2nd_v4, [uu in col_user_2nd_v4 WHERE “MOBILE” in labels(uu)] as col_mobile_2nd_v4
optional match (n)<-[r3:CBK_STATE_ENTERPRISE_LEADER]-(y:USER)
where r3.first_cbkmark_on<=20220602 and id(n)<>‘1510615318’
with count(distinct case when y is not null then n else null end) as n_cbkin_State_enterprise_leader_2nd_v4
with m, col_appl_1st_v4, col_user_2nd_v4, col_mobile_2nd_v4,n_cbkin_State_enterprise_leader_2nd_v4
return size(col_appl_1st_v4) as n_appl_1st_v4,size(col_user_2nd_v4) as n_user_2nd_v4,size(col_mobile_2nd_v4) as n_mobile_2nd_v4,n_cbkin_State_enterprise_leader_2nd_v4
试试下面这样:
match (m:USER) where id(m) in [“1510615318”]
optional match (m)-[r1:CALL_TO]-(x:MOBILE)-[:APPLY_FOR]->(a1:APPL)-[:APPLY_ON]-(t1:TIME)
where r1.first_callmark_on<=20220102 and t1.TIME.date < ‘2022-01-02’
optional match (x)-[r2:CALL_TO]-(n:USER)
where r2.first_callmark_on<=20220102 and id(n)<>‘1510615318’
optional match (n)<-[r3:CBK_STATE_ENTERPRISE_LEADER]-(y:USER)
where r3.first_cbkmark_on<=20220602 and id(y)<>‘1510615318’
with
m,
collect(distinct x) as col_appl_1st_v4,
collect(distinct n) as col_user_2nd_v4,
count(distinct case when y is not null then n else null end) as n_cbkin_State_enterprise_leader_2nd_v4
with
m,
col_appl_1st_v4,
col_user_2nd_v4,
n_cbkin_State_enterprise_leader_2nd_v4,
[uu in col_user_2nd_v4 WHERE “MOBILE” in labels(uu)] as col_mobile_2nd_v4
return
size(col_appl_1st_v4) as n_appl_1st_v4,
size(col_user_2nd_v4) as n_user_2nd_v4,
size(col_mobile_2nd_v4) as n_mobile_2nd_v4,
n_cbkin_State_enterprise_leader_2nd_v4
match (m:USER) where id(m) in [“1510615318”]
optional match (m)-[r1:CALL_TO]-(x:MOBILE)-[:APPLY_FOR]->(a1:APPL)-[:APPLY_ON]-(t1:TIME)
where r1.first_callmark_on<=20220102 and t1.TIME.date < ‘2022-01-02’
optional match (x)-[r2:CALL_TO]-(n:USER)
where r2.first_callmark_on<=20220102 and id(n)<>‘1510615318’
optional match (n)<-[r3:CBK_STATE_ENTERPRISE_LEADER]-(y:USER)
where r3.first_cbkmark_on<=20220602 and id(n)<>‘1510615318’
optional match (n)<-[r3:CBK_ENGINEER]-(y:USER)
where r3.first_cbkmark_on<=20220602 and id(n)<>‘1510615318’
with
m,
collect(distinct x) as col_appl_1st_v4,
collect(distinct n) as col_user_2nd_v4,
count(distinct y) as n_cbkin_State_enterprise_leader_2nd_v4
count(distinct case when y is not null then n else null end) as n_cbkin_Engineer_2nd_v4
with
m,
col_appl_1st_v4,
col_user_2nd_v4,
n_cbkin_State_enterprise_leader_2nd_v4,
[uu in col_user_2nd_v4 WHERE “MOBILE” in labels(uu)] as col_mobile_2nd_v4
return
size(col_appl_1st_v4) as n_appl_1st_v4,
size(col_user_2nd_v4) as n_user_2nd_v4,
size(col_mobile_2nd_v4) as n_mobile_2nd_v4,
n_cbkin_State_enterprise_leader_2nd_v4如果是新加的,我这里面属性名一样了,是这个别名,必须改成其他的吗,比如这个
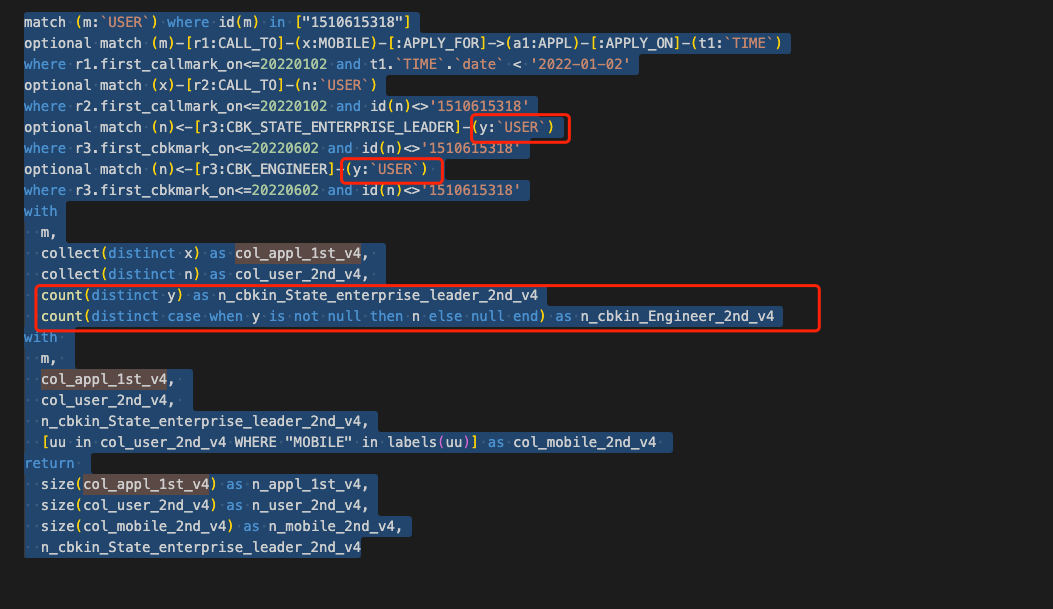
这样的该如何处理呢,我后面都是这种,原来的neo4j的语句
如果不是表示的同一个变量还是要改成别的变量名的,上面的 count(case when) 我看错了,还是按照你的写法吧
下面累加了n多层,count case when还是按照目前你这个架子写吗,能否帮忙把我刚才发的 写个例子 后续我往后加 不太明白这种怎么加上去
不知道理解的对不对,类似下面这种吧:
match (m:USER) where id(m) in [“1510615318”]
optional match (m)-[r1:CALL_TO]-(x:MOBILE)-[:APPLY_FOR]->(a1:APPL)-[:APPLY_ON]-(t1:TIME)
where r1.first_callmark_on<=20220102 and t1.TIME.date < ‘2022-01-02’
optional match (x)-[r2:CALL_TO]-(n:USER)<-[r3:CBK_STATE_ENTERPRISE_LEADER]-(n2:USER)<-[r4:CBK_ENGINEER]-(n3:USER)
where r2.first_callmark_on<=20220102 and id(n)<>‘1510615318’ and r3.first_cbkmark_on<=20220602 and r4.first_cbkmark_on<=20220602
with
m,
collect(distinct x) as col_appl_1st_v4,
collect(distinct n) as col_user_2nd_v4,
count(distinct n2) as n_cbkin_State_enterprise_leader_2nd_v4
count(distinct case when n2 is not null then n3 else null end) as n_cbkin_Engineer_2nd_v4
with
m,
col_appl_1st_v4,
col_user_2nd_v4,
n_cbkin_State_enterprise_leader_2nd_v4,
[uu in col_user_2nd_v4 WHERE “MOBILE” in labels(uu)] as col_mobile_2nd_v4
return
size(col_appl_1st_v4) as n_appl_1st_v4,
size(col_user_2nd_v4) as n_user_2nd_v4,
size(col_mobile_2nd_v4) as n_mobile_2nd_v4,
n_cbkin_State_enterprise_leader_2nd_v4
cypher有50多行 好多option match 估计这样写 不太行把 是不是太长了?
像我刚才发的 都有7个option match 估计合成一个 没法看了
一个 query 太长到也不要紧,主要看能不能表达你的业务逻辑。
如果可以,建议升级一下最新的 nightly 版本,就没这个限制了,可以按照你们最早的写法。不写在一起主要是担心可能会走了索引扫描,导致内存问题。
我们现在是3.3 应该是最高了吧