在第一期中,我们简单了解了一些 nGQL 的常用语句。本文旨在帮助 NebulaGraph 新手快速了解查询语句调优,读懂查询计划。
一直以来,NebulaGraph 社区里最热门之一的话题都是“我如何表达这样的查询最好?“、”我这个查询还有优化空间吗?“这一类的话题。今天,我就来试着介绍下如何理解查询语句的执行与优化过程,帮助大家更好地脚踩在地上去写自己的查询语句。
同时,这篇文章也是 nGQL 简明教程系列的第二期。在你通过本文了解如何面向性能写查询语句后,就能更好地理解在第三期进行的图建模内容。
一个查询的一生
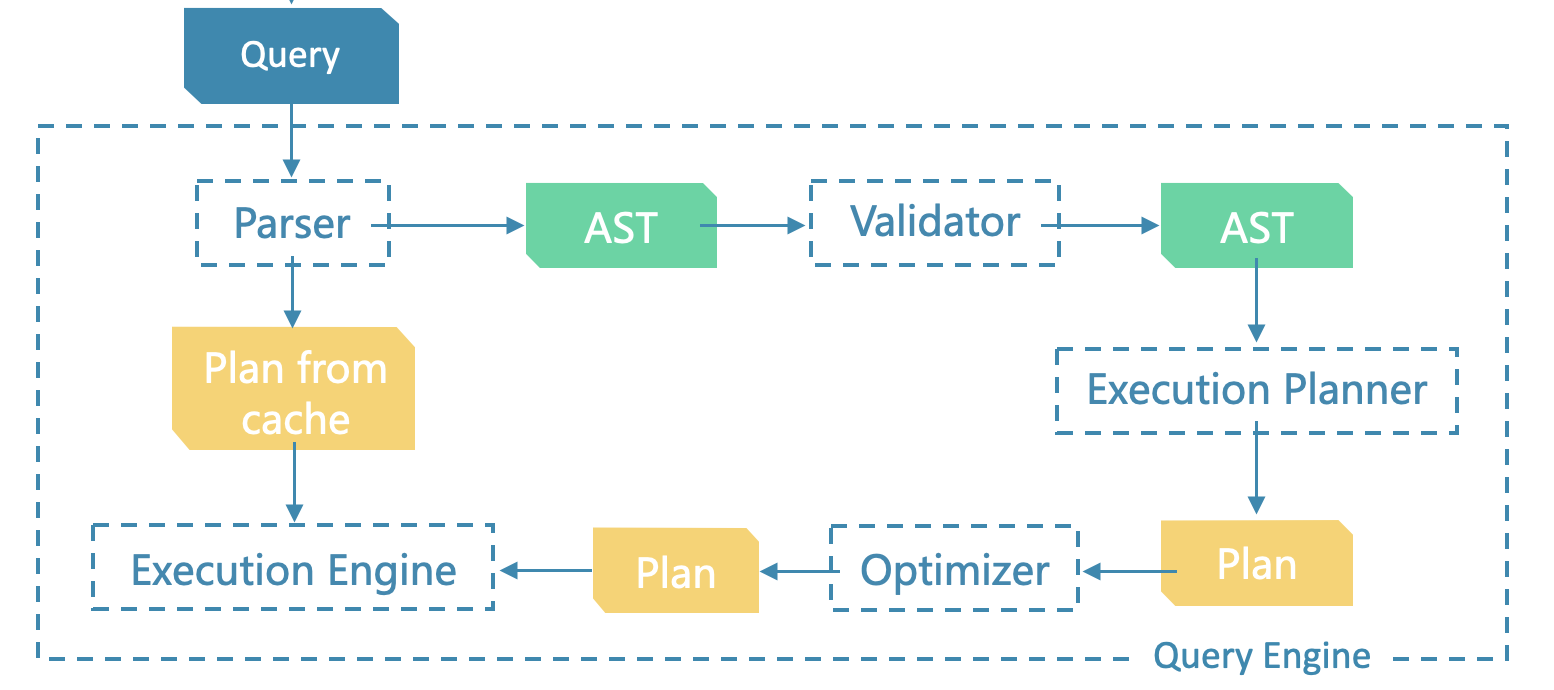
先从一个查询语句从进入 NebulaGraph 到返回查询结果的全过程讲起。在开始之前,建议阅读下文末的延伸阅读的架构和索引内容。
简单来说,一个查询语句被从 GraphClient 发送给 graphd 之后,经历了:
- 在 Parser 中被解析成抽象语法树 AST;
- 在 Validator、Planner 中被写成执行计划图,图中的每一个顶点 PlanNode 对应着一种算子;
- 通过 Optimizer 中的优化规则 RBO 改写执行计划图;
- 优化过的计划图被执行引擎从图的叶子节点开始执行直到根部。
举一个例子,这是一个实现「查询年龄大于 34 岁的三跳好友」的查询语句:
GO 3 STEPS FROM "player100" OVER follow WHERE $$.player.age > 34 YIELD DISTINCT $$.player.name AS name, $$.player.age AS age | ORDER BY $-.age ASC, $-.name DESC;
这条查询语句经过了解析、验证、优化之后,最终的执行计划是,Start -> Loop -> Start -> GetNeighbors -> Project -> Dedup -> Loop -> GetNeighbors -> Project -> GetVertices -> Project -> LeftJoin -> Filter -> Project -> Dedup -> Sort,或者如下图所示:
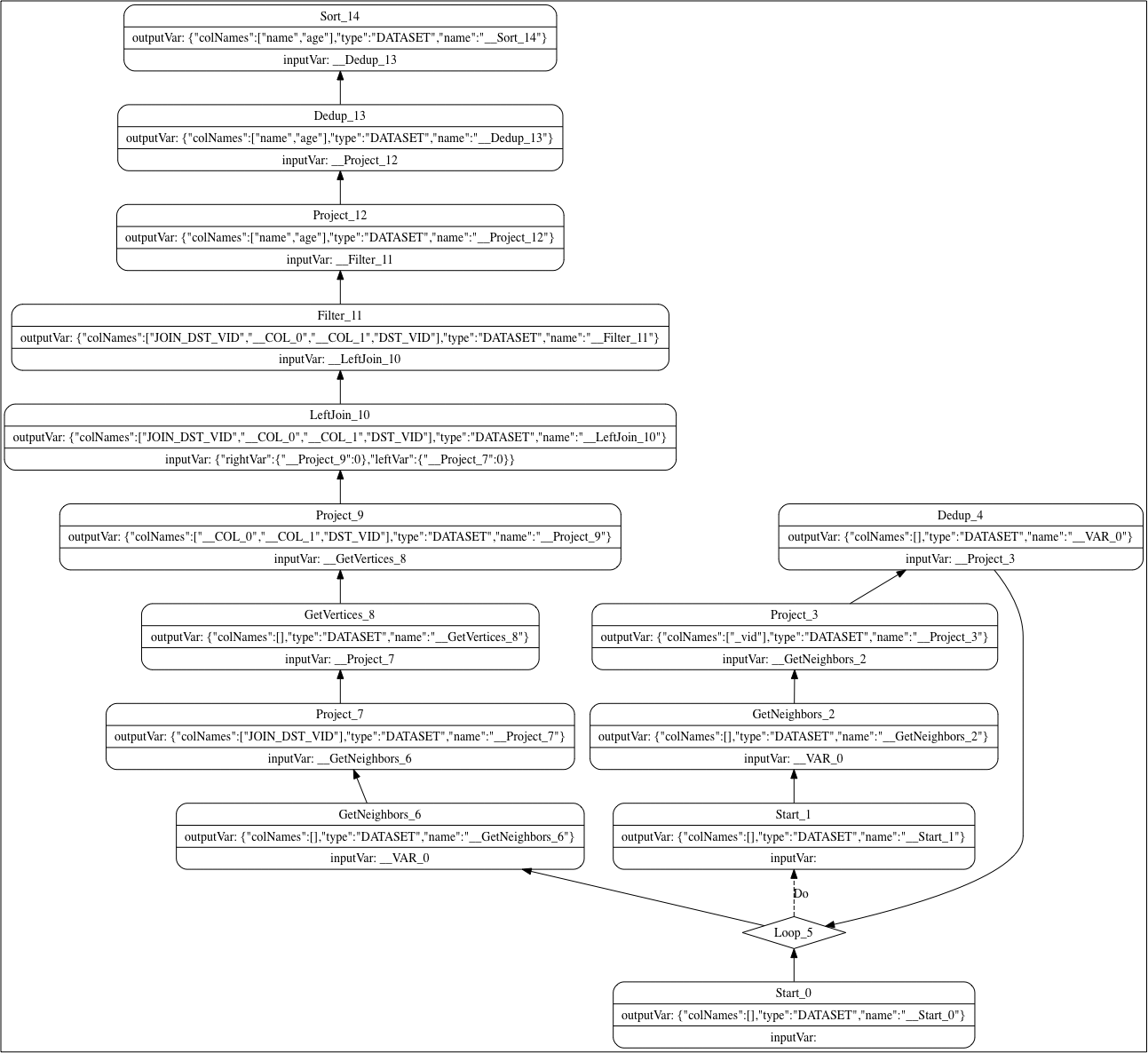
了解这个优化过程和最终执行计划是了解什么是调优查询、面向性能设计图建模的关键。
回到上面的执行计划,这个计划图由添加了 PROFILE FORMAT="DOT" 的执行结果中的 digraph 部分,借助 Graphviz 渲染而得。值得注意的是,FORMAT="DOT" 省略之后的输出结果是表格形式的,且有更多信息会展示出来,后面我们会解读。
(root@nebula) [basketballplayer]> PROFILE FORMAT="DOT" GO 3 STEPS FROM "player100" OVER follow WHERE $$.player.age > 34 YIELD DISTINCT $$.player.name AS name, $$.player.age AS age | ORDER BY $-.age ASC, $-.name DESC;
+-----------------+-----+
| name | age |
+-----------------+-----+
| "Tony Parker" | 36 |
| "Manu Ginobili" | 41 |
| "Tim Duncan" | 42 |
+-----------------+-----+
Got 3 rows (time spent 8885/19871 us)
Execution Plan (optimize time 1391 us)
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
plan
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
digraph exec_plan {
rankdir=BT;
"Sort_14"[label="{Sort_14|outputVar: \{\"colNames\":\[\"name\",\"age\"\],\"type\":\"DATASET\",\"name\":\"__Sort_14\"\}|inputVar: __Dedup_13}", shape=Mrecord];
"Dedup_13"->"Sort_14";
"Dedup_13"[label="{Dedup_13|outputVar: \{\"colNames\":\[\"name\",\"age\"\],\"type\":\"DATASET\",\"name\":\"__Dedup_13\"\}|inputVar: __Project_12}", shape=Mrecord];
"Project_12"->"Dedup_13";
"Project_12"[label="{Project_12|outputVar: \{\"colNames\":\[\"name\",\"age\"\],\"type\":\"DATASET\",\"name\":\"__Project_12\"\}|inputVar: __Filter_11}", shape=Mrecord];
"Filter_11"->"Project_12";
"Filter_11"[label="{Filter_11|outputVar: \{\"colNames\":\[\"JOIN_DST_VID\",\"__COL_0\",\"__COL_1\",\"DST_VID\"\],\"type\":\"DATASET\",\"name\":\"__Filter_11\"\}|inputVar: __LeftJoin_10}", shape=Mrecord];
"LeftJoin_10"->"Filter_11";
"LeftJoin_10"[label="{LeftJoin_10|outputVar: \{\"colNames\":\[\"JOIN_DST_VID\",\"__COL_0\",\"__COL_1\",\"DST_VID\"\],\"type\":\"DATASET\",\"name\":\"__LeftJoin_10\"\}|inputVar: \{\"rightVar\":\{\"__Project_9\":0\},\"leftVar\":\{\"__Project_7\":0\}\}}", shape=Mrecord];
"Project_9"->"LeftJoin_10";
"Project_9"[label="{Project_9|outputVar: \{\"colNames\":\[\"__COL_0\",\"__COL_1\",\"DST_VID\"\],\"type\":\"DATASET\",\"name\":\"__Project_9\"\}|inputVar: __GetVertices_8}", shape=Mrecord];
"GetVertices_8"->"Project_9";
"GetVertices_8"[label="{GetVertices_8|outputVar: \{\"colNames\":\[\],\"type\":\"DATASET\",\"name\":\"__GetVertices_8\"\}|inputVar: __Project_7}", shape=Mrecord];
"Project_7"->"GetVertices_8";
"Project_7"[label="{Project_7|outputVar: \{\"colNames\":\[\"JOIN_DST_VID\"\],\"type\":\"DATASET\",\"name\":\"__Project_7\"\}|inputVar: __GetNeighbors_6}", shape=Mrecord];
"GetNeighbors_6"->"Project_7";
"GetNeighbors_6"[label="{GetNeighbors_6|outputVar: \{\"colNames\":\[\],\"type\":\"DATASET\",\"name\":\"__GetNeighbors_6\"\}|inputVar: __VAR_0}", shape=Mrecord];
"Loop_5"->"GetNeighbors_6";
"Loop_5"[shape=diamond];
"Dedup_4"->"Loop_5";
"Loop_5"->"Start_1"[label="Do", style=dashed];
"Start_0"->"Loop_5";
"Dedup_4"[label="{Dedup_4|outputVar: \{\"colNames\":\[\],\"type\":\"DATASET\",\"name\":\"__VAR_0\"\}|inputVar: __Project_3}", shape=Mrecord];
"Project_3"->"Dedup_4";
"Project_3"[label="{Project_3|outputVar: \{\"colNames\":\[\"_vid\"\],\"type\":\"DATASET\",\"name\":\"__Project_3\"\}|inputVar: __GetNeighbors_2}", shape=Mrecord];
"GetNeighbors_2"->"Project_3";
"GetNeighbors_2"[label="{GetNeighbors_2|outputVar: \{\"colNames\":\[\],\"type\":\"DATASET\",\"name\":\"__GetNeighbors_2\"\}|inputVar: __VAR_0}", shape=Mrecord];
"Start_1"->"GetNeighbors_2";
"Start_1"[label="{Start_1|outputVar: \{\"colNames\":\[\],\"type\":\"DATASET\",\"name\":\"__Start_1\"\}|inputVar: }", shape=Mrecord];
"Start_0"[label="{Start_0|outputVar: \{\"colNames\":\[\],\"type\":\"DATASET\",\"name\":\"__Start_0\"\}|inputVar: }", shape=Mrecord];
}
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
查询计划
为了理解一个查询在整个生命周期中,如何反应到执行层面,以及它们的性能代价是多少,我们从认识它的执行计划开始入手。
以前面的图遍历(图拓展)GO 语句为例,它经历了如下节点:
GetNeighbors是执行计划中最重要的节点,GetNeighbors算子会在运行期访问存储服务,拿到通过起点和指定边类型一步拓展后终点的 ID;- 多步拓展通过
Loop节点实现,Start到Loop之间是Loop的子计划,当满足条件时Loop子计划会被循环执行,最后一步拓展节点在Loop外实现; Project节点用来获取当前拓展的终点 ID;Dedup节点对终点 ID 去重后作为下一步拓展的起点;GetVertices节点负责取终点 tag 的属性;Filter做条件过滤;LeftJoin的作用是合并GetNeighbors和GetVertices的结果;Sort做排序;
而这些节点就是不同的算子。
认识算子
在 NebulaGraph 博客的代码解读文章中已经有很多算子被提及、解释过,这里列举其中部分常见的算子:
注:这里没有提及 GET SUBGRAPH / FIND PATH 中的算子。
| 算子 | 介绍 |
|---|---|
| GetNeighbor | 根据指定的 vid ,从存储层获取起始点和边的属性 |
| Traverse | 仅用于 MATCH 匹配 ()-[e:0..n]-() 模式,获取拓展过程中的起始点和边的属性 |
| AppendVertices | 供 MATCH 使用,同算子 Traverse 配合获取点的属性 |
| GetEdge | 获取边的属性 |
| GetVertices | 获取点的属性,FETCH PROP 或者 GO 语句中。 |
| ScanEdge | 全表扫描边,例如 MATCH ()-[e]->() RETURN e LIMIT 3 |
| ScanVertices | 全表扫描点,例如 MATCH (v) return v LIMIT 3 |
| IndexScan | MATCH 语句中找到起始点的索引查询 |
| TagIndexPrefixScan | LOOKUP 语句中前缀扫描 LOOKUP ON player where player.name == "Steve Nash" YIELD player.name |
| TagIndexRangeScan | LOOKUP 语句中范围扫描 LOOKUP ON player where player.name > "S" YIELD player.name |
| TagIndexFullScan | LOOKUP 语句中全扫描 LOOKUP ON player YIELD player.name |
| Filter | 按条件过滤,例如 WHERE 语句 |
| Project | 获取上一步算子的列 |
| Dedup | 去重 |
| LeftJoin | 合并结果 |
| LIMIT | 限制输出行数 |
从这些算子的含义中,你已经知道图数据库的查询具体落到查询引擎 graphd 内部的最小所需操作了。而性能调优的关键就在于如何规划、优化查询语句是如何被拆解为算子的执行计划。
认识优化规则
对于任何给定的查询,执行计划并不是唯一确定的。相反,在最简单、直接的计划基础之上,优化器 Optimizer 会进行很多性能上的优化。
NebulaGraph 目前的优化器是完全的基于规则的优化 RBO,这些预设的规则的代码都在 src/graph/optimizer 的 rules 里,它们都是针对执行计划模式的修改规则。对 RBO 有兴趣的小伙伴可以读下文末的延伸阅读的源码介绍。
值得一提的是,2022 年开始在大部分优化规则的代码中增加了很多好理解的 ASCII Art 图形注释,结合优化规则的命名本身的自解释性,我们可以快速理解优化规则的匹配和转换逻辑。
首先,这些规则的转换 transform 代码都在 .cpp 文件里,ASCII Art 图形注释在同名对应的 .h 里!
ls src/graph/optimizer/rule/*.h
src/graph/optimizer/rule/CollapseProjectRule.h src/graph/optimizer/rule/PushFilterDownLeftJoinRule.h
src/graph/optimizer/rule/CombineFilterRule.h src/graph/optimizer/rule/PushFilterDownNodeRule.h
src/graph/optimizer/rule/EdgeIndexFullScanRule.h src/graph/optimizer/rule/PushFilterDownProjectRule.h
src/graph/optimizer/rule/EliminateAppendVerticesRule.h src/graph/optimizer/rule/PushFilterDownScanVerticesRule.h
src/graph/optimizer/rule/EliminateRowCollectRule.h src/graph/optimizer/rule/PushLimitDownGetNeighborsRule.h
src/graph/optimizer/rule/GeoPredicateEdgeIndexScanRule.h src/graph/optimizer/rule/PushLimitDownIndexScanRule.h
src/graph/optimizer/rule/GeoPredicateIndexScanBaseRule.h src/graph/optimizer/rule/PushLimitDownProjectRule.h
src/graph/optimizer/rule/GeoPredicateTagIndexScanRule.h src/graph/optimizer/rule/PushLimitDownScanAppendVerticesRule.h
src/graph/optimizer/rule/GetEdgesTransformAppendVerticesLimitRule.h src/graph/optimizer/rule/PushLimitDownScanEdgesAppendVerticesRule.h
src/graph/optimizer/rule/GetEdgesTransformRule.h src/graph/optimizer/rule/PushLimitDownScanEdgesRule.h
src/graph/optimizer/rule/GetEdgesTransformUtils.h src/graph/optimizer/rule/PushStepLimitDownGetNeighborsRule.h
src/graph/optimizer/rule/IndexFullScanBaseRule.h src/graph/optimizer/rule/PushStepSampleDownGetNeighborsRule.h
src/graph/optimizer/rule/IndexScanRule.h src/graph/optimizer/rule/PushTopNDownIndexScanRule.h
src/graph/optimizer/rule/MergeGetNbrsAndDedupRule.h src/graph/optimizer/rule/PushVFilterDownScanVerticesRule.h
src/graph/optimizer/rule/MergeGetNbrsAndProjectRule.h src/graph/optimizer/rule/RemoveNoopProjectRule.h
src/graph/optimizer/rule/MergeGetVerticesAndDedupRule.h src/graph/optimizer/rule/RemoveProjectDedupBeforeGetDstBySrcRule.h
src/graph/optimizer/rule/MergeGetVerticesAndProjectRule.h src/graph/optimizer/rule/TagIndexFullScanRule.h
src/graph/optimizer/rule/OptimizeEdgeIndexScanByFilterRule.h src/graph/optimizer/rule/TopNRule.h
src/graph/optimizer/rule/OptimizeTagIndexScanByFilterRule.h src/graph/optimizer/rule/UnionAllEdgeIndexScanRule.h
src/graph/optimizer/rule/PushEFilterDownRule.h src/graph/optimizer/rule/UnionAllIndexScanBaseRule.h
src/graph/optimizer/rule/PushFilterDownAggregateRule.h src/graph/optimizer/rule/UnionAllTagIndexScanRule.h
src/graph/optimizer/rule/PushFilterDownGetNbrsRule.h
GetEdgesTransformRule
我们看下这个规则名字的意思是转换 GetEdges 的规则。看起来不够明确,来看看 GetEdgesTransformRule.h:
// Convert [[ScanVertices]] to [[ScanEdges]] in certain cases
// Required conditions:
// 1. Match the pattern
// Benefits:
// 1. Avoid doing Traverse to optimize performance
// Quey example:
// 1. match ()-[e]->() return e limit 3
//
// Tranformation:
// Before:
// +---------+---------+
// | Project |
// +---------+---------+
// |
// +---------+---------+
// | Limit |
// +---------+---------+
// |
// +---------+---------+
// | Traverse |
// +---------+---------+
// |
// +---------+---------+
// | ScanVertices |
// +---------+---------+
//
// After:
// +---------+---------+
// | Project |
// +---------+---------+
// |
// +---------+---------+
// | Limit |
// +---------+---------+
// |
// +---------+---------+
// | Project |
// +---------+---------+
// |
// +---------+---------+
// | ScanEdges |
// +---------+---------+
结合 .cpp 中 GetEdgesTransformRule::match 和 GetEdgesTransformRule::transform 的代码,我们可以确定这个优化规则是将 MATCH ()-[e]->() RETURN e LIMIT 3 原本按照 ScanVertices 去扫描点变为 ScanEdges 扫描边。
因为,这个规则的背景是在没有点、边索引的 LIMIT 情况下,无起点 VID/属性条件的查询是可以通过扫点、边数据下推 LIMIT 的。这里 MATCH ()-[e]->() RETURN e LIMIT 3 扫描边的查询因为只需要返回边 RETURN e,所以直接扫描边 ScanEdges 是更高效的。
PushLimitDownScanEdgesRule
我们看看这个规则,在 PushLimitDownScanEdgesRule.h 里有注释
// Embedding limit to [[ScanEdges]]
// Required conditions:
// 1. Match the pattern
// Benefits:
// 1. Limit data early to optimize performance
//
// Transformation:
// Before:
//
// +--------+--------+
// | Limit |
// | (limit=3) |
// +--------+--------+
// |
// +---------+---------+
// | ScanEdges |
// +---------+---------+
//
// After:
//
// +--------+--------+
// | Limit |
// | (limit=3) |
// +--------+--------+
// |
// +---------+---------+
// | ScanEdges |
// | (limit=3) |
// +---------+---------+
这个规则很简单,当 ScanEdges 算子的下游是 Limit 算子的时候,把 Limit 的过滤条件嵌入到 ScanEdges 之中。这一步的意义是什么呢?这里涉及到一个优化规则里常见的概念,计算下推。
计算下推
在计算存储分离的数据库系统中,涉及到读取数据的算子需要从存储层远程捞取数据再做进一步处理。而这个 RPC 的数据传输常常成为性能的瓶颈。然而,如果下一步计算要做的事情是对数据的按条件剪枝,例如 Filter、Limit、TopN 等等。这时候,如果存储层捞数据时考虑了条件剪枝情况,则可以大大地减少数据传输量。
上面提到的 PushLimitDownScanEdgesRule.h 的优化规则就是一个典型的 Limit 下推(Push Down)的规则。
PushLimitDownProjectRule
类似的,我们看看这个规则。PushLimitDownProjectRule.h 里有这样一段注释,这个规则只是把 Project 算子之后的 Limit 算子的顺序调换了一下。我们可以想象在这个变换之后,Limit 就和 ScanEdges 等其他可以下推 Limit 的算子相邻了,像 PushLimitDownScanEdgesRule 的规则变换也可以做了。
// Push [[Limit]] down [[Project]]
// Required conditions:
// 1. Match the pattern
// Benefits:
// 1. Limit data early to optimize performance
//
// Tranformation:
// Before:
//
// +--------+--------+
// | Limit |
// | (limit=3) |
// +--------+--------+
// |
// +---------+---------+
// | Project |
// +---------+---------+
//
// After:
// +---------+---------+
// | Project |
// +---------+---------+
// |
// +--------+--------+
// | Limit |
// | (limit=3) |
// +--------+--------+
PushFilterDownGetNbrsRule
再介绍一个 Filter 下推的例子,从规则注释里的转换图示可以读出,当 GetNeighbors 之后再双条件交集 Filter 的时候,取一个条件下推到 GetNeighbors,再进行另一个条件的 Filter。这个规则既减少了 GetNeighbors 数据的传输量、Filter 输入的运算量,又少了一次集合运算。
// Embed the [[Filter]] into [[GetNeighbors]]
// Required conditions:
// 1. Match the pattern
// 2. Filter contains subexpressions that meet pushdown conditions
// Benefits:
// 1. Filter data early to optimize performance
//
// Tranformation:
// Before:
//
// +------------------+------------------+
// | Filter |
// |($^.player.age>3 and $$.player.age<4)|
// +------------------+------------------+
// |
// +------+------+
// | GetNeighbors|
// +------+------+
//
// After:
//
// +--------+--------+
// | Filter |
// |($$.player.age<4)|
// +--------+--------+
// |
// +--------+--------+
// | GetNeighbors |
// |($^.player.age>3)|
// +--------+--------+
下一步
- 感兴趣的同学可以试着进一步看看所有的规则。
- 可以试着在多个 graphd 集群上,更改其中一个 graphd 的配置,关闭
enable_optimizer,把同一个 Query 分别在开启了优化和关闭优化的 graphd 中执行,比较执行计划的区别。 - 如果你发现更优的规则,欢迎来论坛、GitHub 提交优化建议、PR!
简单的介绍就到这里,接下来我们从一些实例出发来进一步实操执行计划调优吧。
nGQL 执行计划调优解读实例
希望这些具体问题能够给大家带来启发。
观察基于索引与数据的扫描
我在索引详解中解释过 NebulaGraph 的索引和传统数据库中索引的区别。简单来说,因为以类似于邻接表的方式存储数据,NebulaGraph 要额外创建索引来解决全扫描或者根据属性条件扫描点、边这些类似于表结构数据库中的场景。
另外,在无过滤条件 LIMIT 采样扫描的场景下,NebulaGraph 从 v3.0 开始允许无索引的查询情形(因为点边数据扫描支持了 Limit 下推,不再像之前那么昂贵)。在没有索引可以被选择的情况下,Planner 也会选择直接扫点或者边的数据,这个差别可以从 explain、profile 中看出来。
这里用 basketballplayer 数据集中自带的索引来举例,这个数据集只在 player 这个 tag 上有两个索引:
(root@nebula) [basketballplayer]> SHOW TAG INDEXES
+------------------+----------+----------+
| Index Name | By Tag | Columns |
+------------------+----------+----------+
| "player_index_0" | "player" | [] |
| "player_index_1" | "player" | ["name"] |
+------------------+----------+----------+
Got 2 rows (time spent 2440/19653 us)
无索引查询
先看一个没有索引的场景查询:
(root@nebula) [basketballplayer]> PROFILE MATCH (n:team) RETURN id(n) LIMIT 1
+-----------+
| id(n) |
+-----------+
| "team206" |
+-----------+
Got 1 rows (time spent 3637/17551 us)
Execution Plan (optimize time 265 us)
-----+----------------+--------------+-----------------------------------------------------+--------------------------------------------------------------
| id | name | dependencies | profiling data | operator info |
-----+----------------+--------------+-----------------------------------------------------+--------------------------------------------------------------
| 15 | Project | 16 | ver: 0, rows: 1, execTime: 28us, totalTime: 29us | outputVar: { |
| | | | | "colNames": [ |
| | | | | "id(n)" |
| | | | | ], |
| | | | | "type": "DATASET", |
| | | | | "name": "__DataCollect_8" |
| | | | | } |
| | | | | inputVar: __Limit_13 |
| | | | | columns: [ |
| | | | | "id($-.n)" |
| | | | | ] |
-----+----------------+--------------+-----------------------------------------------------+--------------------------------------------------------------
| 16 | Limit | 17 | ver: 0, rows: 1, execTime: 3us, totalTime: 8us | outputVar: { |
| | | | | "colNames": [ |
| | | | | "n" |
| | | | | ], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Limit_13" |
| | | | | } |
| | | | | inputVar: __AppendVertices_17 |
| | | | | offset: 0 |
| | | | | count: 1 |
-----+----------------+--------------+-----------------------------------------------------+--------------------------------------------------------------
| 17 | AppendVertices | 18 | { | outputVar: { |
| | | | ver: 0, rows: 3, execTime: 244us, totalTime: 1124us | "colNames": [ |
| | | | "storaged0":9779 exec/total: 257(us)/779(us) | "n" |
| | | | "storaged2":9779 exec/total: 190(us)/870(us) | ], |
| | | | total_rpc: 1024(us) | "type": "DATASET", |
| | | | "storaged1":9779 exec/total: 195(us)/879(us) | "name": "__AppendVertices_17" |
| | | | } | } |
| | | | | inputVar: __ScanVertices_18 |
| | | | | space: 2 |
| | | | | dedup: true |
| | | | | limit: -1 |
| | | | | filter: |
| | | | | orderBy: [] |
| | | | | src: $-._vid |
| | | | | props: [ |
| | | | | { |
| | | | | "props": [ |
| | | | | "name", |
| | | | | "age", |
| | | | | "_tag" |
| | | | | ], |
| | | | | "tagId": 3 |
| | | | | }, |
| | | | | { |
| | | | | "props": [ |
| | | | | "name", |
| | | | | "_tag" |
| | | | | ], |
| | | | | "tagId": 4 |
| | | | | } |
| | | | | ] |
| | | | | exprs: |
| | | | | vertex_filter: |
| | | | | if_track_previous_path: false |
-----+----------------+--------------+-----------------------------------------------------+--------------------------------------------------------------
| 18 | ScanVertices | 3 | { | outputVar: { |
| | | | ver: 0, rows: 3, execTime: 225us, totalTime: 1586us | "colNames": [ |
| | | | "storaged2":9779 exec/total: 532(us)/1303(us) | "_vid", |
| | | | "storaged1":9779 exec/total: 480(us)/1318(us) | "team._tag" |
| | | | total_rpc: 1502(us) | ], |
| | | | "storaged0":9779 exec/total: 506(us)/1382(us) | "type": "DATASET", |
| | | | } | "name": "__ScanVertices_18" |
| | | | | } |
| | | | | inputVar: |
| | | | | space: 2 |
| | | | | dedup: false |
| | | | | limit: 1 |
| | | | | filter: (team._tag IS NOT EMPTY AND team._tag IS NOT EMPTY) |
| | | | | orderBy: [] |
| | | | | props: [ |
| | | | | { |
| | | | | "props": [ |
| | | | | "_tag" |
| | | | | ], |
| | | | | "tagId": 4 |
| | | | | } |
| | | | | ] |
| | | | | exprs: |
-----+----------------+--------------+-----------------------------------------------------+--------------------------------------------------------------
| 3 | Start | | ver: 0, rows: 0, execTime: 0us, totalTime: 27us | outputVar: { |
| | | | | "colNames": [], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Start_3" |
| | | | | } |
-----+----------------+--------------+-----------------------------------------------------+--------------------------------------------------------------
这个例子里我们关注从 Storage 里取数据的算子,以及算子取得数据的行数:
- ScanVertices,扫描点(其中
limit: 1) - rows: 3,扫描得到 3 行数据
ScanVertices 比较好理解,在没有索引的情况下,只能去扫描点数据(非索引)了,limit : 1 表示它也被下推了,不会取全量数据。
其次,rows: 3,为什么不是 1 呢?这是因为数据分别在 3 个 storaged 之中,同时被扫描,所以在每一个 storaged 中都 limit 1 才能保证最终数据能满足需求,而这里刚好三个 storaged 中都有数据分布,最终得到的数据量就是 3 了。
有索引查询,LIMIT 无下推
下面,我们来查 player 上的数据,前面的 SHOW TAG INDEXES 里看到,player 上是存在索引的:
(root@nebula) [basketballplayer]> PROFILE MATCH (n:player) RETURN id(n) LIMIT 1
+-------------+
| id(n) |
+-------------+
| "player127" |
+-------------+
Got 1 rows (time spent 4053/19496 us)
Execution Plan (optimize time 181 us)
-----+----------------+--------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------
| id | name | dependencies | profiling data | operator info |
-----+----------------+--------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------
| 11 | Project | 9 | ver: 0, rows: 1, execTime: 21us, totalTime: 25us | outputVar: { |
| | | | | "colNames": [ |
| | | | | "id(n)" |
| | | | | ], |
| | | | | "type": "DATASET", |
| | | | | "name": "__DataCollect_7" |
| | | | | } |
| | | | | inputVar: __Limit_9 |
| | | | | columns: [ |
| | | | | "id($-.n)" |
| | | | | ] |
-----+----------------+--------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------
| 9 | Limit | 3 | ver: 0, rows: 1, execTime: 12us, totalTime: 16us | outputVar: { |
| | | | | "colNames": [ |
| | | | | "n" |
| | | | | ], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Limit_9" |
| | | | | } |
| | | | | inputVar: __AppendVertices_3 |
| | | | | offset: 0 |
| | | | | count: 1 |
-----+----------------+--------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------
| 3 | AppendVertices | 1 | { | outputVar: { |
| | | | ver: 0, rows: 52, execTime: 390us, totalTime: 1140us | "colNames": [ |
| | | | total_rpc: 933(us) | "n" |
| | | | "storaged1":9779 exec/total: 208(us)/718(us) | ], |
| | | | "storaged0":9779 exec/total: 118(us)/693(us) | "type": "DATASET", |
| | | | "storaged2":9779 exec/total: 241(us)/664(us) | "name": "__AppendVertices_3" |
| | | | } | } |
| | | | | inputVar: __IndexScan_1 |
| | | | | space: 2 |
| | | | | dedup: true |
| | | | | limit: -1 |
| | | | | filter: |
| | | | | orderBy: [] |
| | | | | src: $_vid |
| | | | | props: [ |
| | | | | { |
| | | | | "props": [ |
| | | | | "_tag" |
| | | | | ], |
| | | | | "tagId": 3 |
| | | | | } |
| | | | | ] |
| | | | | exprs: |
| | | | | vertex_filter: player._tag IS NOT EMPTY |
| | | | | if_track_previous_path: false |
-----+----------------+--------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------
| 1 | IndexScan | 2 | { | outputVar: { |
| | | | ver: 0, rows: 52, execTime: 0us, totalTime: 1567us | "colNames": [ |
| | | | "storaged1":9779 exec/total: 499(us)/1266(us) | "_vid" |
| | | | "storaged0":9779 exec/total: 441(us)/1321(us) | ], |
| | | | storage_detail: {IndexLimitNode(limit=9223372036854775807):263(us),IndexProjectionNode(projectColumn=[_vid]):267(us),IndexVertexScanNode(IndexID=7, Path=()):271(us)} | "type": "DATASET", |
| | | | "storaged2":9779 exec/total: 487(us)/1256(us) | "name": "__IndexScan_1" |
| | | | } | } |
| | | | | inputVar: |
| | | | | space: 2 |
| | | | | dedup: false |
| | | | | limit: 9223372036854775807 |
| | | | | filter: |
| | | | | orderBy: [] |
| | | | | schemaId: 3 |
| | | | | isEdge: false |
| | | | | returnCols: [ |
| | | | | "_vid" |
| | | | | ] |
| | | | | indexCtx: [ |
| | | | | { |
| | | | | "columnHints": [], |
| | | | | "filter": "", |
| | | | | "index_id": 7 |
| | | | | } |
| | | | | ] |
-----+----------------+--------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------
| 2 | Start | | ver: 0, rows: 0, execTime: 0us, totalTime: 42us | outputVar: { |
| | | | | "colNames": [], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Start_2" |
| | | | | } |
-----+----------------+--------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------
可以看出:
- 捞数据的算子是
IndexScan,Limit并没有下推limit: 9223372036854775807 - 取得的数据行数是
rows: 52
由于当前 NebulaGraph 社区版并没有进行 MATCH 带索引查询的 Limit 下推,所以在社区版中这种无条件查询比有索引的情况下开销更加昂贵。
btw,MATCH 起点查询策略的代码在 src/graph/planner/PlannersRegister.cpp 中,如果你感兴趣的话可以去读读看。下面代码仅供参考:
void PlannersRegister::registerMatch() {
auto& planners = Planner::plannersMap()[Sentence::Kind::kMatch];
planners.emplace_back(&MatchPlanner::match, &MatchPlanner::make);
auto& startVidFinders = StartVidFinder::finders();
// MATCH(n) WHERE id(n) = value RETURN n
startVidFinders.emplace_back(&VertexIdSeek::make);
// MATCH (n)-[]-(l), (l)-[]-(m) return n,l,m
// MATCH (n)-[]-(l) MATCH (l)-[]-(m) return n,l,m
startVidFinders.emplace_back(&ArgumentFinder::make);
// MATCH(n:Tag{prop:value}) RETURN n
// MATCH(n:Tag) WHERE n.prop = value RETURN n
startVidFinders.emplace_back(&PropIndexSeek::make);
// seek by tag or edge(index)
// MATCH(n: tag) RETURN n
// MATCH(s)-[:edge]->(e) RETURN e
startVidFinders.emplace_back(&LabelIndexSeek::make);
// Scan the start vertex directly
// Now we hard code the order of match rules before CBO,
// put scan rule at the last for we assume it's most inefficient
startVidFinders.emplace_back(&ScanSeek::make);
}
有索引查询,LIMIT 下推
值得庆幸的是,现在 LOOKUP 与 MATCH 等价的查询中的索引查询算子是支持 Limit 下推的优化规则的:
(root@nebula) [basketballplayer]> PROFILE LOOKUP ON player YIELD id(vertex) AS n | LIMIT 1
+-------------+
| n |
+-------------+
| "player114" |
+-------------+
Got 1 rows (time spent 9643/37744 us)
Execution Plan (optimize time 217 us)
-----+------------------+--------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------
| id | name | dependencies | profiling data | operator info |
-----+------------------+--------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------
| 8 | Project | 9 | ver: 0, rows: 1, execTime: 31us, totalTime: 33us | outputVar: { |
| | | | | "colNames": [ |
| | | | | "n" |
| | | | | ], |
| | | | | "type": "DATASET", |
| | | | | "name": "__DataCollect_4" |
| | | | | } |
| | | | | inputVar: __Limit_6 |
| | | | | columns: [ |
| | | | | "id(VERTEX) AS n" |
| | | | | ] |
-----+------------------+--------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------
| 9 | Limit | 10 | ver: 0, rows: 1, execTime: 42us, totalTime: 43us | outputVar: { |
| | | | | "colNames": [ |
| | | | | "_vid", |
| | | | | "player._tag", |
| | | | | "player.age", |
| | | | | "player.name" |
| | | | | ], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Limit_6" |
| | | | | } |
| | | | | inputVar: __TagIndexFullScan_10 |
| | | | | offset: 0 |
| | | | | count: 1 |
-----+------------------+--------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------
| 10 | TagIndexFullScan | 0 | { | outputVar: { |
| | | | ver: 0, rows: 10, execTime: 0us, totalTime: 8540us | "colNames": [ |
| | | | "storaged2":9779 exec/total: 369(us)/951(us) | "_vid", |
| | | | "storaged1":9779 exec/total: 383(us)/8198(us) | "player._tag", |
| | | | "storaged0":9779 exec/total: 483(us)/1181(us) | "player.age", |
| | | | storage_detail: {IndexLimitNode(limit=1):319(us),IndexProjectionNode(projectColumn=[_vid,_tag,age,name]):321(us),IndexVertexScanNode(IndexID=7, Path=()):346(us)} | "player.name" |
| | | | } | ], |
| | | | | "type": "DATASET", |
| | | | | "name": "__TagIndexFullScan_10" |
| | | | | } |
| | | | | inputVar: |
| | | | | space: 2 |
| | | | | dedup: false |
| | | | | limit: 1 |
| | | | | filter: |
| | | | | orderBy: [] |
| | | | | schemaId: 3 |
| | | | | isEdge: false |
| | | | | returnCols: [ |
| | | | | "_vid", |
| | | | | "_tag", |
| | | | | "age", |
| | | | | "name" |
| | | | | ] |
| | | | | indexCtx: [ |
| | | | | { |
| | | | | "columnHints": [], |
| | | | | "filter": "", |
| | | | | "index_id": 7 |
| | | | | } |
| | | | | ] |
-----+------------------+--------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------
| 0 | Start | | ver: 0, rows: 0, execTime: 0us, totalTime: 22us | outputVar: { |
| | | | | "colNames": [], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Start_0" |
| | | | | } |
-----+------------------+--------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------
我们可以看到:
- 数据捞取算子是
TagIndexFullScan,有limit:1下推 - 因为索引扫描是所有分区 fan-out 扫描(区别于
ScanVertices只是所有 storage 扫描,LOOKUP的算子扫得更细),这里limit:1下推扫得的数据量是rows: 10
综上,我们对“无 VID 的起点查询”的不同情况有了更具体的认识。
观察 filter 下推
我们先来看看这个查询,它沿着指定起点向外做图扩展,根据边的属性条件过滤,返回目的点 ID:
GO FROM "player100" OVER follow WHERE properties(edge).degree > 1 YIELD follow._dst
它的执行计划是:
(root@nebula) [basketballplayer]> explain GO FROM "player100" OVER follow WHERE properties(edge).degree > 1 YIELD follow._dst
Execution succeeded (time spent 959/7917 us)
Execution Plan (optimize time 369 us)
-----+--------------+--------------+----------------+-----------------------------------------
| id | name | dependencies | profiling data | operator info |
-----+--------------+--------------+----------------+-----------------------------------------
| 3 | Project | 2 | | outputVar: { |
| | | | | "colNames": [ |
| | | | | "follow._dst" |
| | | | | ], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Project_3" |
| | | | | } |
| | | | | inputVar: __Filter_2 |
| | | | | columns: [ |
| | | | | "follow._dst" |
| | | | | ] |
-----+--------------+--------------+----------------+-----------------------------------------
| 2 | Filter | 1 | | outputVar: { |
| | | | | "colNames": [], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Filter_2" |
| | | | | } |
| | | | | inputVar: __GetNeighbors_1 |
| | | | | condition: (properties(EDGE).degree>1) |
| | | | | isStable: false |
-----+--------------+--------------+----------------+-----------------------------------------
| 1 | GetNeighbors | 0 | | outputVar: { |
| | | | | "colNames": [], |
| | | | | "type": "DATASET", |
| | | | | "name": "__GetNeighbors_1" |
| | | | | } |
| | | | | inputVar: __VAR_0 |
| | | | | space: 49 |
| | | | | dedup: false |
| | | | | limit: -1 |
| | | | | filter: |
| | | | | orderBy: [] |
| | | | | src: COLUMN[0] |
| | | | | edgeTypes: [] |
| | | | | edgeDirection: OUT_EDGE |
| | | | | vertexProps: |
| | | | | edgeProps: [ |
| | | | | { |
| | | | | "props": [ |
| | | | | "_dst", |
| | | | | "_rank", |
| | | | | "_src", |
| | | | | "_type", |
| | | | | "degree" |
| | | | | ], |
| | | | | "type": 53 |
| | | | | } |
| | | | | ] |
| | | | | statProps: |
| | | | | exprs: |
| | | | | random: false |
-----+--------------+--------------+----------------+-----------------------------------------
| 0 | Start | | | outputVar: { |
| | | | | "colNames": [], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Start_0" |
| | | | | } |
-----+--------------+--------------+----------------+-----------------------------------------
可以看到,这个计划里,GetNeighboors 算子取得了所有的 player100 的出边(以及边属性),然后再通过单独 filter 算子。
我们关注:
filter:是空的properties(EDGE).degree>1作为filter算子的条件。
这里,我们有没有可能把 filter 下推呢?答案是可以的,只要在 WHERE 条件中提供边类型的信息,优化条件就可以把它下推到 GetNeighbors 算子:
(root@nebula) [basketballplayer]> explain GO FROM "player100" OVER follow WHERE follow.degree > 1 YIELD follow._dst
Execution succeeded (time spent 664/6650 us)
Execution Plan (optimize time 161 us)
-----+--------------+--------------+----------------+----------------------------
| id | name | dependencies | profiling data | operator info |
-----+--------------+--------------+----------------+----------------------------
| 3 | Project | 4 | | outputVar: { |
| | | | | "colNames": [ |
| | | | | "follow._dst" |
| | | | | ], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Project_3" |
| | | | | } |
| | | | | inputVar: __Filter_2 |
| | | | | columns: [ |
| | | | | "follow._dst" |
| | | | | ] |
-----+--------------+--------------+----------------+----------------------------
| 4 | GetNeighbors | 0 | | outputVar: { |
| | | | | "colNames": [], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Filter_2" |
| | | | | } |
| | | | | inputVar: __VAR_0 |
| | | | | space: 49 |
| | | | | dedup: false |
| | | | | limit: -1 |
| | | | | filter: (follow.degree>1) |
| | | | | orderBy: [] |
| | | | | src: COLUMN[0] |
| | | | | edgeTypes: [] |
| | | | | edgeDirection: OUT_EDGE |
| | | | | vertexProps: |
| | | | | edgeProps: [ |
| | | | | { |
| | | | | "props": [ |
| | | | | "_dst", |
| | | | | "degree" |
| | | | | ], |
| | | | | "type": 53 |
| | | | | } |
| | | | | ] |
| | | | | statProps: |
| | | | | exprs: |
| | | | | random: false |
-----+--------------+--------------+----------------+----------------------------
| 0 | Start | | | outputVar: { |
| | | | | "colNames": [], |
| | | | | "type": "DATASET", |
| | | | | "name": "__Start_0" |
| | | | | } |
-----+--------------+--------------+----------------+----------------------------
这时候 WHERE follow.degree > 1 把 follow 这个信息传递给了优化规则,让它可以:
- 在
GetNeighbors算子里提供filter: (follow.degree>1)的信息 - 去掉
filter算子
这样,优化之后的查询不仅少了一个 graphd 里的算子执行过程,GetNeighbors 捞取的数据也因为传递了 filter 参数涉及的数据可能比全量的数据少了。
通过这个例子,我们可以推断出这样的一个规律:显式表达尽可能多的已知信息往往是有帮助的。在做规则优化、数据查询时,模糊查询常常是更昂贵的,确定的信息会带来更多的剪枝、过滤、短路,并且这些信息在查询中越明确、越早提供性能也会越好。
下面是另一个例子:

