
上篇序言中我们讲述了源码解读系列的由来,在 Nebula Graph Overview 篇中我们将带你了解下 Nebula Graph 的架构以及代码仓分布、代码结构和模块规划。
1. 架构
Nebula Graph 是一个开源的分布式图数据库。Nebula采用存储计算分离的设计,解耦存储与计算。同时在数据库内核之外,我们也提供了很多周边工具,比如数据导入,监控,部署,可视化,图计算等等。
Nebula 设计请参见《图数据库综述与 Nebula 在图数据库设计的实践》。
整体架构设计如下图所示:

查询引擎采用无状态设计,可轻松实现横向扩展,分为语法分析、语义分析、优化器、执行引擎等几个主要部分。
详细设计参见《图数据库的查询引擎设计》,《初识 Nebula Graph 2.0 Query Engine》。
查询引擎架构设计如下图所示:

Storage 包含两个部分, 一是 meta 相关的存储, 我们称之为 Meta Service ,另一个是 data 相关的存储, 我们称之为 Storage Service。
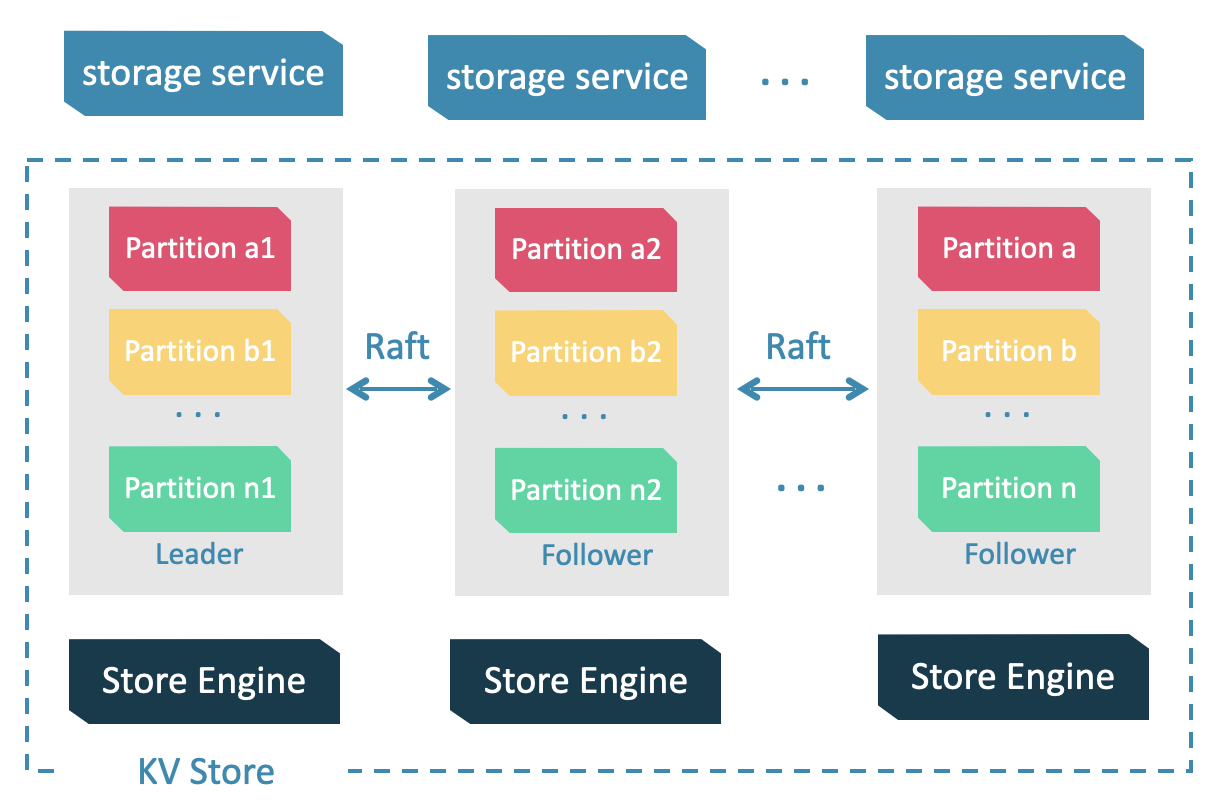
Storage Service 共有三层:最底层是 Store Engine;之上便是我们的 Consensus 层,实现了 Multi Group Raft;最上层,便是我们的 Storage interfaces,这一层定义了一系列和图相关的 API。
详细设计参见《图数据库的存储设计》 。
存储引擎架构设计如下图所示:
2. 代码仓库概览
欢迎来到 vesoft 代码仓库(vesoft 为图数据库 Nebula Graph 开发商)。
目前 Nebula 产品架构中,包含了图数据库内核,客户端,工具,测试框架,编译,可视化,监控等。
本文的主要目的是简单介绍 Nebula Graph 主要 Repo 的代码结构,并说明各个模块的基本功能。后续会有更多的详细设计说明。希望能够帮助到社区读者更好地理解 Nebula Graph,并能够为 Nebula 社区做出自己的贡献,比如提交 Feature,修复 Bug,提交文档等。
以下列出 vesoft-inc 仓库中大部分的代码仓库:
- nebula:Nebula 1.0 的内核代码
- nebula graph:Nebula 2.0 查询计算引擎
- nebula storage:Nebula 2.0 存储引擎
- nebula common:Nebula 2.0 内核工具包
- Nebula Clients
- nebula-java:Java 客户端
- nebula-cpp:CPP 客户端
- nebula-go:Go 客户端
- nebula-python:Python 客户端
- Nebula Tools
- nebula-importer:基于 Go 客户端实现的高性能数据导入工具
- nebula-spark-utils:收录工具 Spark Connector、Exchange、Algorithm
- nebula-br:备份恢复工具
- nebula-ansible、nebula-operator:部署工具
- Nebula Test
- nebula-bench:压力与性能测试工程
- nebula-chaos:混沌测试工程
- Compiling
- nebula-third-party:Nebula Graph 图数据库内核依赖的第三方包
- nebula-gears:Nebula Graph 图数据库内核工具链
- nebula-graph-studio:Nebula Graph 可视化工具
3. 代码结构及模块说明
3.1 Nebula Graph
├── cmake
├── conf
├── LICENSES
├── package
├── resources
├── scripts
├── src
│ ├── context
│ ├── daemons
│ ├── executor
│ ├── optimizer
│ ├── parser
│ ├── planner
│ ├── scheduler
│ ├── service
│ ├── session
│ ├── stats
│ ├── util
│ ├── validator
│ └── visitor
└── tests
├── admin
├── bench
├── common
├── data
├── job
├── maintain
├── mutate
├── query
└── tck
- conf/:查询引擎配置文件目录
- package/:graph 打包脚本
- resources/:资源文件
- scripts/:启动脚本
- src/:查询引擎源码目录
- src/context/:查询的上下文信息,包括 AST(抽象语法树),Execution Plan(执行计划),执行结果以及其他计算相关的资源。
- src/daemons/:查询引擎主进程
- src/executor/:执行器,各个算子的实现
- src/optimizer/:RBO(基于规则的优化)实现,以及优化规则
- src/parser/:词法解析,语法解析,:AST结构定义
- src/planner/:算子,以及执行计划生成
- src/scheduler/:执行计划的调度器
- src/service/:查询引擎服务层,提供鉴权,执行 Query 的接口
- src/session/:Session 管理
- src/stats/:执行统计,比如 P99、慢查询统计等
- src/util/:工具函数
- src/validator/:语义分析实现,用于检查语义错误,并进行一些简单的改写优化
- src/visitor/:表达式访问器,用于提取表达式信息,或者优化
- tests/:基于 BDD 的集成测试框架,测试所有 Nebula Graph 提供的功能
3.2 Nebula Storage
├── cmake
├── conf
├── docker
├── docs
├── LICENSES
├── package
├── scripts
└── src
├── codec
├── daemons
├── kvstore
├── meta
├── mock
├── storage
├── tools
├── utils
└── version
- conf/:存储引擎配置文件目录
- package/:storage 打包脚本
- scripts/:启动脚本
- src/:存储引擎源码目录
- src/codec/:序列化反序列化工具
- src/daemons/:存储引擎和元数据引擎主进程
- src/kvstore/:基于 raft 的分布式 KV 存储实现
- src/meta/:基于 KVStore 的元数据管理服务实现,用于管理元数据信息,集群管理,长耗时任务管理等
- src/storage/:基于 KVStore 的图数据存储引擎实现
- src/tools/:一些小工具实现
- src/utils/:代码工具函数
3.3 Nebula Common
├── cmake
│ └── nebula
├── LICENSES
├── src
│ └── common
│ ├── algorithm
│ ├── base
│ ├── charset
│ ├── clients
│ ├── concurrent
│ ├── conf
│ ├── context
│ ├── cpp
│ ├── datatypes
│ ├── encryption
│ ├── expression
│ ├── fs
│ ├── function
│ ├── graph
│ ├── hdfs
│ ├── http
│ ├── interface
│ ├── meta
│ ├── network
│ ├── plugin
│ ├── process
│ ├── session
│ ├── stats
│ ├── test
│ ├── thread
│ ├── thrift
│ ├── time
│ ├── version
│ └── webservice
└── third-party
Nebula Common 仓库代码是 Nebula 内核代码的工具包,提供一些常用工具的高效实现。一些常用工具包相信各位工程师一定也是了然于心。这里只对其中和图数据库密切相关的目录进行说明。
- src/common/clients/:meta,storage 客户端的 CPP 实现
- src/common/datatypes/:Nebula Graph 中数据类型及计算的定义,比如 string,int,bool,float,Vertex,Edge 等。
- rc/common/expression/:nGQL 中表达式的定义
- src/common/function/:nGQL 中的函数的定义
- src/common/interface/:graph、meta、storage 服务的接口定义
以上为本篇文章的介绍内容。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~