提问参考模版:
- nebula 版本:v3.4.0
- 部署方式: 分布式
- 安装方式: RPM
- 是否上生产环境:N
- 硬件信息
- 磁盘 SSD
- CPU、内存信息: 128G 内存
- 问题的具体描述
- 相关的 meta / storage / graph info 日志信息(尽量使用文本形式方便检索)
之前测试v3.3 的时候发现,job compact 会卡住 compaction 过了两天了还没有结束
这次在v3.4 上发现还是有个这个问题。
操作: 在A space上提交的job compact, 在B space 上也提交job compact QUEUE,前两天提交的。
今天发现A 上的一直Running 状态,今天重启meta 之后A 显示failed 了,B 进入Running status, 但是看log 只是开始了,并没有进行真正的compact
# A Space
show jobs
+--------+------------------+------------+----------------------------+----------------------------+
| Job Id | Command | Status | Start Time | Stop Time |
+--------+------------------+------------+----------------------------+----------------------------+
| 24 | "LEADER_BALANCE" | "FINISHED" | 2023-03-24T02:49:52.000000 | 2023-03-24T02:49:57.000000 |
| 23 | "COMPACT" | "FAILED" | 2023-03-23T01:36:59.000000 | 2023-03-24T02:49:52.000000 |
+--------+------------------+------------+----------------------------+----------------------------+
Got 2 rows (time spent 39.865ms/40.779452ms)
Fri, 24 Mar 2023 11:36:36 CST
# B Space
show jobs
+--------+-----------+-----------+----------------------------+----------------------------+
| Job Id | Command | Status | Start Time | Stop Time |
+--------+-----------+-----------+----------------------------+----------------------------+
| 22 | "COMPACT" | "RUNNING" | 2023-03-24T02:51:58.000000 | |
| 21 | "STATS" | "FAILED" | 2023-03-23T01:35:16.000000 | 2023-03-24T02:51:58.000000 |
+--------+-----------+-----------+----------------------------+----------------------------+
Got 2 rows (time spent 38.89ms/39.747516ms)
Fri, 24 Mar 2023 11:37:07 CST
logs 几台节点都是这个状态,后续就没了
I20230324 10:51:58.838047 14269 AdminTaskManager.cpp:315] subtask of task(21, 2) finished, unfinished task 1
I20230324 10:51:58.844677 14274 AdminTaskManager.cpp:326] task(21, 2) runSubTask() exit
I20230324 10:51:58.848191 14269 AdminTaskManager.cpp:326] task(21, 2) runSubTask() exit
I20230324 10:51:58.944547 14278 AdminTaskManager.cpp:315] subtask of task(21, 2) finished, unfinished task 0
I20230324 10:51:58.944617 14278 StatsTask.cpp:312] task(21, 2) finished, rc=[E_USER_CANCEL]
I20230324 10:51:58.948653 14079 AdminTaskManager.cpp:92] reportTaskFinish(), job=21, task=2, rc=E_USER_CANCEL
I20230324 10:51:58.948897 14079 AdminTaskManager.cpp:92] reportTaskFinish(), job=22, task=3, rc=E_TASK_EXECUTION_FAILED
I20230324 10:51:58.999516 14079 AdminTaskManager.cpp:134] reportTaskFinish(), job=21, task=2, rc=SUCCEEDED
I20230324 10:51:59.010535 13949 EventListener.h:21] Rocksdb start compaction column family: default because of ManualCompaction, status: OK, compacted 47741 files into 0, base level is 0, output level is 1
I20230324 10:51:59.031738 13949 CompactionFilter.h:82] Do full/manual compaction!
另外:
配置如下 enable 了memory_tracker , 发现storage 占用了很高内存
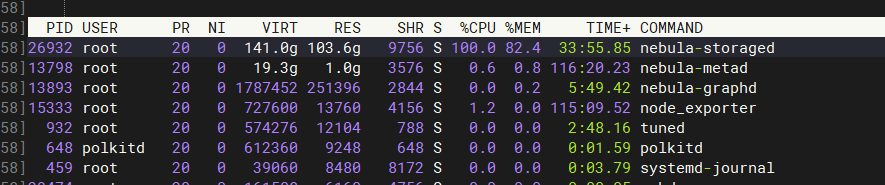
有两个问题,
- enable memory_tracker 和之前的参数
--system_memory_high_watermark_ratio=0.9作用一样吗 - 现在这个没有查询 为什么会一直有这么高的内存占用? 该怎么解决? 重启storage 服务吗?
System memory high watermark ratio, cancel the memory checking when the ratio greater than 1.0
--system_memory_high_watermark_ratio=0.9
########## metrics ##########
--enable_space_level_metrics=false
--meta_client_timeout_ms=200000
--num_operator_threads=16
########## experimental feature ##########
# if use experimental features
--enable_experimental_feature=true
# if use balance data feature, only work if enable_experimental_feature is true
--enable_data_balance=true
########## session ##########
# Maximum number of sessions that can be created per IP and per user
--max_sessions_per_ip_per_user=300
########## memory tracker ##########
# trackable memory ratio (trackable_memory / (total_memory - untracked_reserved_memory) )
--memory_tracker_limit_ratio=0.8
# untracked reserved memory in Mib
--memory_tracker_untracked_reserved_memory_mb=50
# enable log memory tracker stats periodically
--memory_tracker_detail_log=false
# log memory tacker stats interval in milliseconds
--memory_tracker_detail_log_interval_ms=60000
# enable memory background purge (if jemalloc is used)
--memory_purge_enabled=true
# memory background purge interval in seconds
--memory_purge_interval_seconds=10
