wey
2021 年5 月 8 日 01:50
23
您好 Yangmeng,
可以参考这两个帖子, Yee 分别 给的一些解释
concurrency 设置成机器的 cores 数就差不多了, importer 的实现原理如下图所示:
[importer]
每个文件一个读线程,同时启动 concurrency 个 client 用来给 nebula graph 发压,每个 client 都有个 channelBufferSize 大小的 queue 用来缓存数据,queue 中存放的是按 batch 组装好的 nGQ…
https://discuss.nebula-graph.io/t/nebula-importer-optimize-performance/875/7
我引用一下 Yee 老师在两个帖子的信息
对于csv文件,importer读它是一个线程,启动concurrency个 client,每一个client有channelBufferSize size的queue来buffer query
看起来您的 10/10 是没有到storaged的处理极限,50/50也不知道有没有到极限,可以试着给定 cores数量的 concurrent数, batchSize再调大一些(超过50)评估一下速度,我建议把CSV截断为十分钟可以看结果的量级,不断逼近优化一下结果,然后share出来你的结果哈。
好的, 我的机器是88core, 754内存, 12T 高性能本地SSD, 那我就安装下面的再测试2组看看效果, channelBufferSize 这个参数我理解就是一个定长队列, 排满了就阻塞等待, 这个应该对速度影响不大,
1 个赞
wey
2021 年5 月 8 日 08:58
26
看起来因为yangmeng这个importor的运行环境太豪华了,以至于,50到88个cocurrency 在这两种 batchsize的时候都达到了 storage/server端的最大处理能力(还有网络传输)了,所以importor这边已经没有优化余地了,您觉得呢?
min.wu
2021 年5 月 10 日 02:36
28
一般不太会的。
1 个赞
wey
2021 年5 月 10 日 02:39
29
这样呀,好的好的,谢谢吴老师!那就是那几个组合下都达到了importor的输出极限?
min.wu
2021 年5 月 10 日 02:42
30
importer我们也没有特别调过最优。因为单机导入一般数据量也不会太大,基本上改下并发和batch就够了。而且一个client压一个集群,硬件本身就很难压满的。
想大批量写入还是用spark吧
2 个赞
你好, wey, 能麻烦指导一下这个问题吗? 具体是什么timeout呢?’
你好, 各位大佬, 帮忙指导一下这怎么解决
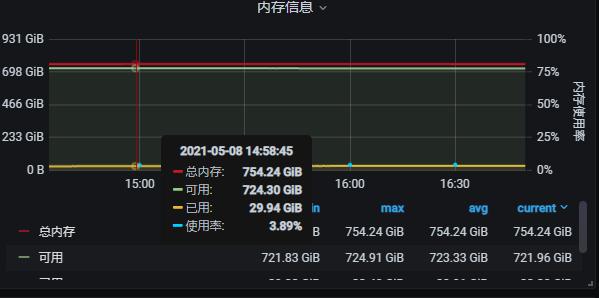
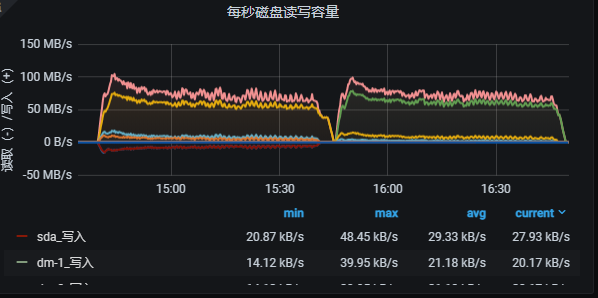
1 我使用这个语句来查中边数 (或者, 我查一些多跳, 节点数上7, 8 亿的也会报这个错, 其实我的内存只用了300G, 一共754G, 是什么原因呢??? 是不是有些默认配置需要修改??)
[image]
2 监控信息
[image]
3 对应graph节点的err日志
[image]
[121]
hello, wey
min.wu
2021 年5 月 12 日 09:23
33
请求应该会失败,报leader change等,重试通常可以恢复。
1 个赞
啊,
1 个赞
min.wu
2021 年5 月 13 日 08:20
36
见过N多人掉这个坑了。。。。
虽然:known issue和faq都写过。。。。
此数据集 26 亿实体、177 亿关系,估计平均每个节点的度为个位数,关系比较稀疏,而节点度的大小对查询的效率的影响很大,不知有没有这方面的评测?
1 个赞
这个除了配置是32核,64g ssd磁盘,集群本身做调优了吗,我用k8s装完集群,用java client测试写500个线程对应500session的tps才2000多。




 ,多谢你花了这么多时间做实验,然后还share结果过来。
,多谢你花了这么多时间做实验,然后还share结果过来。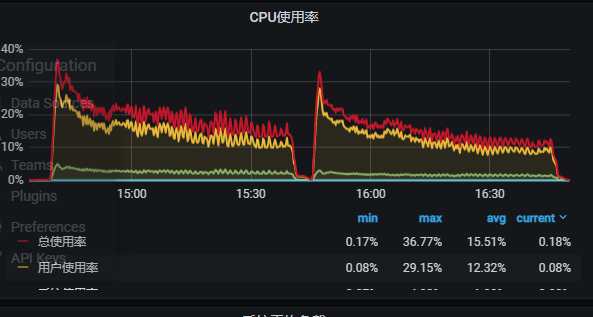

 , 感谢wu老师, 我还是试试吧, 有结果了给你share
, 感谢wu老师, 我还是试试吧, 有结果了给你share 
