nebula 版本:3.6.0
nebula-importer版本:4.0.0
部署方式:所有模块都在一台服务器中
安装方式:二进制包
问题描述:原来自己通过Java将数据直接转化成nGQL语句,进行节点插入,节点数大概有十几亿的数量姐,外加相应的边,可能是自己的拼接的插入语句存在问题(长短不一),导致入库速度不稳定,波动极大。所以下载了importer4.0.0,但在使用时报错,yaml模板是v3的模板,然后自己手动改的,不知道会不会不兼容
瞅瞅这个帖子?
就是这个帖子,没有看到明显的解决办法,是要1、修改配置文件呢?我用的是v3的配置文件的模板,只是将v3改成了v4;2、还是要使用低版本的importer呢(这个我试了一下报了别的错误)
是我搞错了,我以为填的版本是importer的版本,实际是填nebula的版本
1 个赞
所以可以导入了么
没有 ![]() ,好像有个变量不能识别,我看他们论坛上说可以跑一个python代码直接生成yaml文件,这个python代码在哪啊?
,好像有个变量不能识别,我看他们论坛上说可以跑一个python代码直接生成yaml文件,这个python代码在哪啊?
o.o 你问问说这个话的人?我好像没啥印象。

就这个论坛里的 nebula-bench导入数据时报错"unsupported client version" - 问答 / 问题 - NebulaGraph 技术社区 (nebula-graph.com.cn)

好的,谢谢。就是还要安装nebula-Bench是吧
其实使用nebula-bench的最终目的是跑性能测试,但是它那个测试工具正好可以生成importe要用到的yaml文件,所以为了省事,你可以下载一个Nebula-bench.
1 个赞
您能帮我解读一下这个结果吗
{“level”:“info”,“ts”:“2023-12-21T01:59:53Z”,“caller”:“manager/manager.go:416”,“msg”:“13m20s 13m31s 49.64%(17 GiB/34 GiB) Records{Finished: 733711477, Failed: 0, Rate: 917127.53/s}, Requests{Finished: 44785, Failed: 0, Latency: 177.744345ms/178.583607ms, Rate: 55.98/s}, Processed{Finished: 733711477, Failed: 0, Rate: 917127.53/s}”}
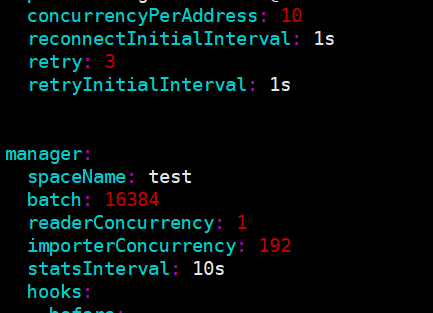
我的服务器是96核384个线程,yaml设置的是192个线程,读取文件使用的是1个线程
你是看不懂结果么,![]()
1、我没看到解读结果的文章
2、想看下我这个入库速度是什么水平,还能不能提升
我这边cpu的利用率只有10%,内存使用只有25%
因为这里的参数字段都是英文命名的,没啥歧义点不需要额外多一篇文档来讲解;
这个要结合你的机器配置来看,以及我这边没有相关的导入报告。如果你觉得现在的速度不满足你的业务需求,你可以把相关的机器配置、导入配置贴贴看能不能优化一下。(我的意思是没必要为了优化而优化,要看你有没有优化(提升)的需求)
比如这个结果,他的单位是一条语句,还是指的一个点或一个边
这个速度跟我直接拼接成语句之后运行所需要的时间差不多,但importer利用的资源比例比较低,另外,肯定还是需要提升的,因为我有比较大的任务量要跑,我现在只是在测试,所以能提升还是需要提升的
GitHub - vesoft-inc/nebula-importer: Nebula Graph Importer with Go 这里有各个参数的说明,看看你address是不是把所有graph的地址都配置上了,并发的那些参数可以按照cpu核数来调整。如果单条记录不是长,batch可以调到1024或者更大
1 个赞