
我用studio 导入的时候能导入成功啊
是error lines 0,是没有错误的意思吧。。。
total lines 0一条都没导进去啊
文件行数是不是比较少,打印的日志是每 5s 异步收集一次,如果 5s 之内就结束了,有可能统计变量还没更新就结束了
是的
2000w行的数据啊,不少了吧 
有没有大佬能帮忙解决一下啊?
你好,想问一下hdfs的csv导入样例有没有呢?我用下边这个的时候spark提示我字段用_c0,_c1改了也还是导不进去,导入json、hive啥的都好使的
tags: [
{
name: player
type: csv
path: /home/hdp/test/playtagcsv0
fields: {
name: name,
age: age
}
vertex: {
field: name
policy: "hash"
}
}
]
你好,spark数据导入请使用 https://github.com/vesoft-inc/nebula-java/tree/master/tools/exchange ,使用方式和spark writer一样,配置文件参考resources下的配置示例。
另外,tag的配置需要加上head的配置:
tags: [
{
name: player
。。。
head=true
}
]噢噢明白了,我还是在想为啥都是_c0这样的,类型和列名都没法定义,感谢哈~
1 个赞
抱歉我又来了……我试着加上了head的配置,好像并没有起作用还是会有下面的错误:
Caused by: java.lang.IllegalArgumentException: Field “age” does not exist.
Available fields: _c0, _c1
看了一下咱们spark导入的com.vesoft.nebula.tools.generator.v2.SparkClientGenerator这个类下边没有从配置里取head/header或者separator的操作, _c0, _c1的默认类型好像还都是string,所以数据没灌进去?麻烦大神帮忙解答一下,谢谢
spark writer已经迁移到这里啦 https://github.com/vesoft-inc/nebula-java/tree/master/tools/exchange
你用的还是旧的代码。
新代码有用到head和separator:
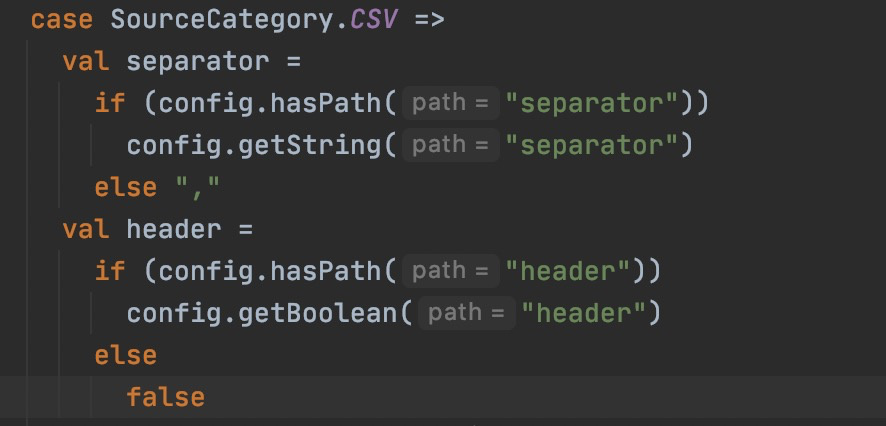
哦哦好的……看网站上链接好像指向的都是老代码的地址,这个咋移到java客户端下了呀 
嗯嗯,刚刚试过了新的这个好使,有个问题就是如果我的csv中有一列是整数,导入的时候spark.read()读成了字符串会造成插入失败,这样子的有没有什么好的解决办法呢?感谢
你在Nebula Graph中对应的属性是什么数据类型呢? 报错的是指定为点的id或者边src_id、dst_id或rank的列么,麻烦把错误日志、配置文件、图数据库的schema贴出来吧。
你好,我这个是简单的测试,在windows下运行scala,只插入顶点,属性分别是name和age,类型是string和int,打印出来的插入语句是下面这样的,在命令行上试了下把age对应的值上的双引号去掉就能正确插入了,不然就会报错。
INSERT VERTEX player(name,age) VALUES hash("wangwu-02"): ("wangwu-02", "30"), hash("jiang-02"): ("jiang-02", "30")
报错信息如下:
ERROR [pool-17-thread-1] - execute error: ValueType is wrong
单步debug的时候看到createDataSource出来的类型是两个string,话说回来,好像一直没有指定csv各字段数据类型的地方,csv的源文件示例如下:
wangwu-02,30
不知道是不是我漏掉了什么,谢谢解答!